English Pronunciation Evaluation without Complex Joint Training: LoRA Fine-tuned Speech Multimodal LLM
作者: Taekyung Ahn, Hosung Nam
分类: cs.CL
发布日期: 2025-09-03
💡 一句话要点
提出基于LoRA微调的多模态LLM,用于英语发音评估与诊断
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 低秩适应 发音评估 发音错误检测 计算机辅助语言学习 语音识别 微调
📋 核心要点
- 现有发音评估方法通常需要复杂的架构设计和针对不同任务的独立训练流程,效率较低。
- 本研究提出使用LoRA微调多模态LLM,无需复杂架构修改即可同时实现APA和MDD。
- 实验表明,该方法在Speechocean762数据集上取得了与人工评估高度相关的性能,且错误率较低。
📝 摘要(中文)
本研究表明,通过低秩适应(LoRA)调整的多模态大型语言模型(MLLM)能够同时执行自动发音评估(APA)和发音错误检测与诊断(MDD)。利用微软的Phi-4-multimodal-instruct,我们的微调方法消除了传统上这些不同任务所需的复杂架构更改或单独的训练程序。在Speechocean762数据集上进行微调后,模型预测的发音评估分数与人工分配的分数表现出很强的皮尔逊相关系数(PCC > 0.7),同时实现了较低的词错误率(WER)和音素错误率(PER)(均 < 0.15)。值得注意的是,仅微调LoRA层就足以达到与微调所有音频层相当的性能水平。这项研究强调,通过调整大型多模态模型,无需完全微调,即可建立集成的发音评估系统,与以前为同时进行APA和MDD而设计的联合模型相比,该方法采用了一种显著更简单的训练方法。这种高效的基于LoRA的方法为英语L2学习者提供了更易于访问、集成和有效的计算机辅助发音训练(CAPT)技术。
🔬 方法详解
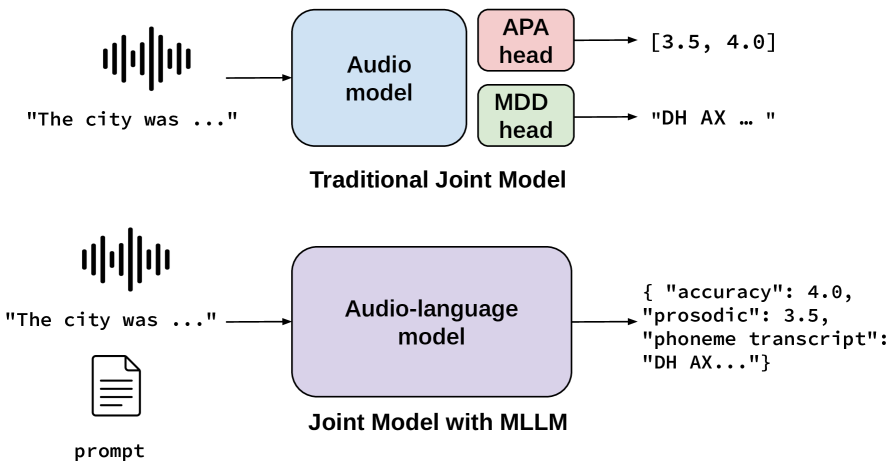
问题定义:论文旨在解决英语发音评估和错误诊断问题,即Automatic Pronunciation Assessment (APA)和Mispronunciation Detection and Diagnosis (MDD)。传统方法通常需要针对APA和MDD分别设计复杂的模型结构和训练流程,或者采用联合训练的方式,但计算成本高昂且不易部署。这些方法难以兼顾效率和性能,限制了其在实际计算机辅助语言学习(CAPT)系统中的应用。
核心思路:论文的核心思路是利用预训练的多模态大型语言模型(MLLM)的强大表征能力,通过低秩适应(LoRA)进行高效微调,从而同时实现APA和MDD。LoRA通过冻结预训练模型的大部分参数,仅训练少量新增的低秩矩阵,显著降低了计算成本和存储需求,使得在资源有限的条件下也能进行有效的模型微调。
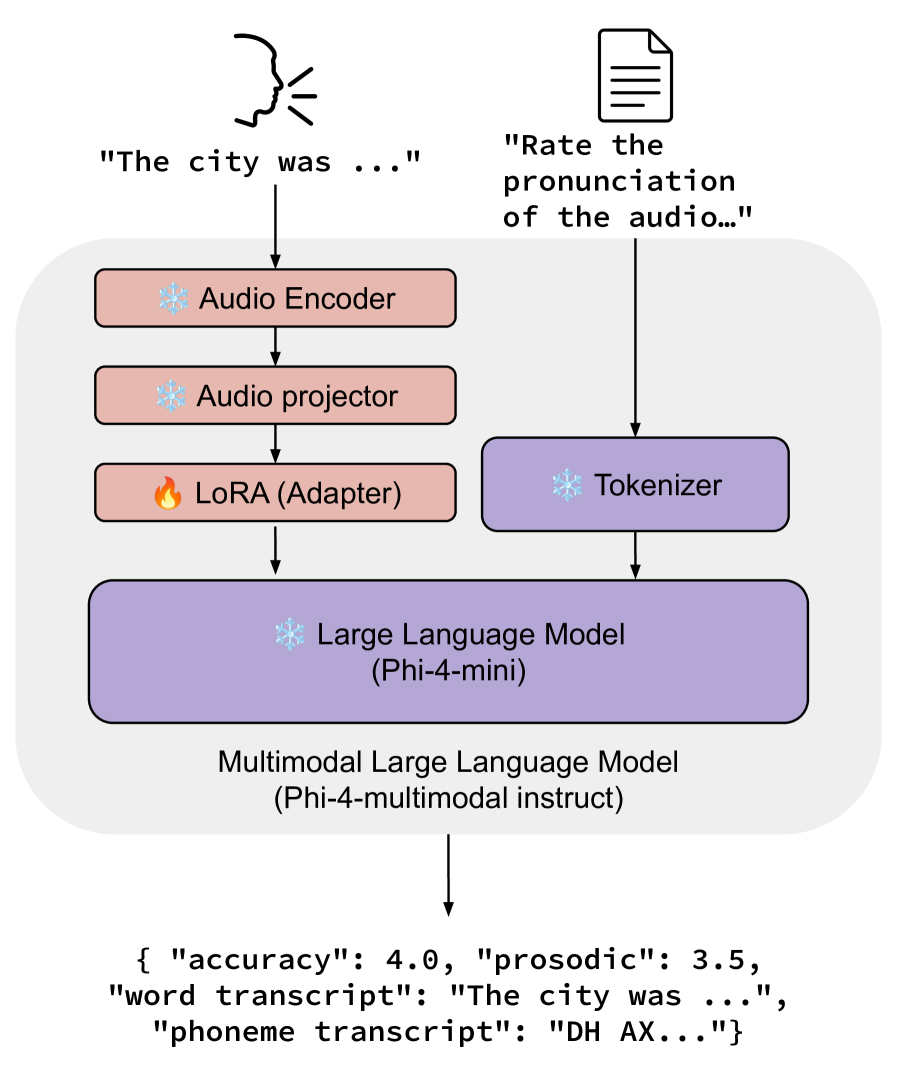
技术框架:整体框架基于Microsoft的Phi-4-multimodal-instruct模型。该模型首先接收语音输入,通过语音编码器提取语音特征。然后,将语音特征与文本信息(例如,目标发音文本)一起输入到MLLM中。MLLM利用其强大的语言理解和生成能力,对发音质量进行评估,并检测和诊断发音错误。整个流程无需复杂的架构修改,仅通过LoRA微调即可实现。
关键创新:最重要的技术创新点在于利用LoRA微调多模态LLM,实现了APA和MDD的联合建模,避免了传统方法中复杂的架构设计和训练流程。与现有方法相比,该方法训练效率更高,计算成本更低,同时保持了良好的性能。此外,研究表明,仅微调LoRA层即可达到与微调所有音频层相当的性能水平,进一步验证了LoRA的有效性。
关键设计:论文使用了Speechocean762数据集进行微调。损失函数的设计旨在优化模型在APA和MDD任务上的性能。具体而言,APA任务使用回归损失,例如均方误差(MSE),来预测发音质量得分。MDD任务使用分类损失,例如交叉熵损失,来检测和诊断发音错误。LoRA的秩(rank)是一个关键参数,需要根据具体任务和数据集进行调整。实验中,作者探索了不同的LoRA秩,并选择了最佳的参数设置。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于LoRA微调的MLLM在Speechocean762数据集上取得了显著的性能。模型预测的发音评估分数与人工分配的分数表现出很强的皮尔逊相关系数(PCC > 0.7),同时实现了较低的词错误率(WER < 0.15)和音素错误率(PER < 0.15)。值得注意的是,仅微调LoRA层就足以达到与微调所有音频层相当的性能水平。
🎯 应用场景
该研究成果可广泛应用于计算机辅助发音训练(CAPT)系统、在线语言学习平台和移动学习应用中。通过提供自动化的发音评估和错误诊断,可以帮助英语学习者更有效地提高发音水平。该方法的高效性和易部署性使其能够应用于资源有限的环境,例如发展中国家的语言学习项目。
📄 摘要(原文)
This study demonstrates that a Multimodal Large Language Model (MLLM) adapted via Low-Rank Adaptation (LoRA) can perform both Automatic Pronunciation Assessment (APA) and Mispronunciation Detection and Diagnosis (MDD) simultaneously. Leveraging Microsoft's Phi-4-multimodal-instruct, our fine-tuning method eliminates the need for complex architectural changes or separate training procedures conventionally required for these distinct tasks. Fine-tuned on the Speechocean762 dataset, the pronunciation evaluation scores predicted by the model exhibited a strong Pearson Correlation Coefficient (PCC > 0.7) with human-assigned scores, while achieving low Word Error Rate (WER) and Phoneme Error Rate (PER) (both < 0.15). Notably, fine-tuning only the LoRA layers was sufficient to achieve performance levels comparable to those achieved by fine-tuning all audio layers. This research highlights that an integrated pronunciation assessment system can be established by adapting large multimodal models without full fine-tuning, utilizing a significantly simpler training methodology compared to previous joint models designed for simultaneous APA and MDD. This efficient LoRA-based approach paves the way for more accessible, integrated, and effective Computer-Assisted Pronunciation Training (CAPT) technologies for English L2 learners.