Scaling behavior of large language models in emotional safety classification across sizes and tasks
作者: Edoardo Pinzuti, Oliver Tüscher, André Ferreira Castro
分类: cs.CL, cs.LG
发布日期: 2025-09-02
💡 一句话要点
研究LLM在情感安全分类中的规模效应,探索轻量级模型在心理健康领域的应用潜力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感安全分类 大型语言模型 心理健康 轻量级微调 LLaMA 规模效应 数据增强
📋 核心要点
- 现有LLM在处理情感安全内容时缺乏深入理解,尤其是在心理健康领域,存在潜在风险。
- 通过构建新的数据集并评估不同规模的LLaMA模型,研究情感安全分类任务中的模型性能。
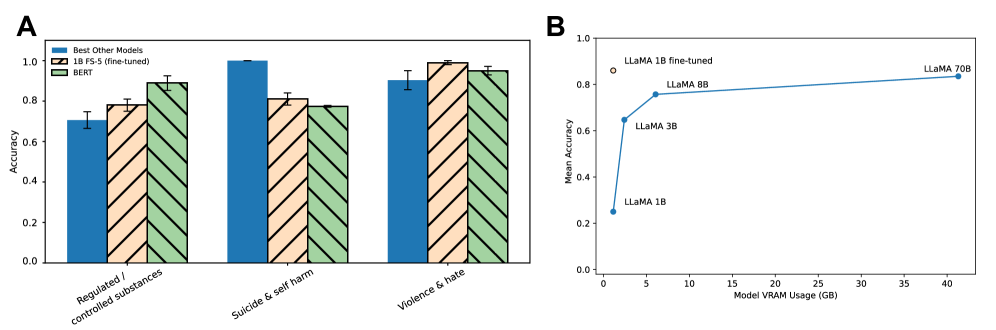
- 实验表明,轻量级微调后的1B模型在特定任务上可媲美大型模型,为隐私保护应用提供可能。
📝 摘要(中文)
本文研究了大型语言模型(LLM)在处理情感敏感内容时的规模效应,这对于构建安全可靠的系统至关重要,尤其是在心理健康领域。研究聚焦于两个关键任务:情感安全的三元分类(安全、不安全、临界)和使用六类安全风险分类的多标签分类。为此,作者构建了一个新的数据集,通过合并多个人工撰写的心理健康数据集(>15K样本),并使用ChatGPT生成的情感重新解释提示进行扩充。评估了四个LLaMA模型(1B、3B、8B、70B)在零样本、少样本和微调设置下的性能。结果表明,更大的LLM在多标签分类和零样本设置中表现更强。然而,轻量级微调使1B模型在多个高数据类别中实现了与更大模型和BERT相当的性能,且推理时仅需<2GB VRAM。这些发现表明,更小的、设备上的模型可以作为敏感应用中可行的、保护隐私的替代方案,提供解释情感上下文和维持安全对话边界的能力。这项工作强调了治疗性LLM应用和安全关键系统可扩展对齐的关键意义。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在情感安全分类任务中的表现,特别是在心理健康领域。现有方法,如直接使用大型模型,可能存在隐私泄露风险,且计算成本高昂。同时,缺乏专门针对心理健康领域情感安全的数据集,限制了模型的训练和评估。
核心思路:论文的核心思路是探索小型LLM通过轻量级微调,在情感安全分类任务中达到与大型模型相当的性能,从而在保护隐私的前提下,实现高效的情感安全检测。通过构建领域数据集,并研究不同规模模型的性能,揭示模型规模与性能之间的关系。
技术框架:整体框架包括数据构建、模型选择、训练和评估四个主要阶段。首先,合并多个心理健康数据集,并使用ChatGPT进行数据增强,构建情感安全分类数据集。然后,选择不同规模的LLaMA模型(1B, 3B, 8B, 70B)作为研究对象。接着,在零样本、少样本和微调设置下训练模型。最后,评估模型在情感安全三元分类和多标签分类任务上的性能。
关键创新:论文的关键创新在于:1) 构建了一个专门用于情感安全分类的心理健康数据集,为相关研究提供了数据基础。2) 证明了通过轻量级微调,小型LLM可以在特定任务上达到与大型模型相当的性能,为隐私保护应用提供了新的思路。3) 系统地研究了LLM在情感安全分类任务中的规模效应。
关键设计:在数据增强方面,使用ChatGPT生成情感重新解释提示,以扩充数据集的多样性。在模型训练方面,采用轻量级微调策略,以降低计算成本和保护隐私。在评估方面,使用情感安全三元分类和多标签分类作为评估指标,全面评估模型的性能。具体参数设置和损失函数等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,更大的LLM在多标签分类和零样本设置中表现更强。然而,通过轻量级微调,1B LLaMA模型在多个高数据类别中实现了与更大模型和BERT相当的性能,且推理时仅需<2GB VRAM。这表明小型模型在特定任务上具有竞争力,为资源受限场景下的情感安全应用提供了可能。
🎯 应用场景
该研究成果可应用于开发隐私保护的心理健康助手,例如,在移动设备上部署小型微调模型,用于检测用户输入文本中的情感安全风险,并提供个性化的反馈和支持。此外,该研究也为构建更安全、更可靠的对话系统提供了指导,有助于提升人机交互的质量。
📄 摘要(原文)
Understanding how large language models (LLMs) process emotionally sensitive content is critical for building safe and reliable systems, particularly in mental health contexts. We investigate the scaling behavior of LLMs on two key tasks: trinary classification of emotional safety (safe vs. unsafe vs. borderline) and multi-label classification using a six-category safety risk taxonomy. To support this, we construct a novel dataset by merging several human-authored mental health datasets (> 15K samples) and augmenting them with emotion re-interpretation prompts generated via ChatGPT. We evaluate four LLaMA models (1B, 3B, 8B, 70B) across zero-shot, few-shot, and fine-tuning settings. Our results show that larger LLMs achieve stronger average performance, particularly in nuanced multi-label classification and in zero-shot settings. However, lightweight fine-tuning allowed the 1B model to achieve performance comparable to larger models and BERT in several high-data categories, while requiring <2GB VRAM at inference. These findings suggest that smaller, on-device models can serve as viable, privacy-preserving alternatives for sensitive applications, offering the ability to interpret emotional context and maintain safe conversational boundaries. This work highlights key implications for therapeutic LLM applications and the scalable alignment of safety-critical systems.