IDEAlign: Comparing Large Language Models to Human Experts in Open-ended Interpretive Annotations
作者: Hyunji Nam, Lucia Langlois, James Malamut, Mei Tan, Dorottya Demszky
分类: cs.CL, cs.CY
发布日期: 2025-09-02
备注: 10 pages, 9 pages for appendix
💡 一句话要点
IDEAlign:通过“奇数挑一”评估LLM在开放式解释性标注任务中与人类专家的对齐程度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 解释性标注 相似性度量 基准测试 教育应用
📋 核心要点
- 现有方法难以大规模评估LLM在开放式解释性标注任务中与人类专家的对齐程度,缺乏有效的相似性度量。
- 提出IDEAlgin基准测试范例,通过“奇数挑一”的三元组判断任务,捕获专家对标注相似性的主观评判。
- 实验表明,IDEAlgin能有效评估LLM的标注质量,并发现通过特定prompt策略能显著提升LLM与专家判断的一致性。
📝 摘要(中文)
大型语言模型(LLM)越来越多地应用于开放式、解释性标注任务,例如研究人员进行主题分析或教师对学生作业生成反馈。这些任务涉及自由文本标注,需要基于特定目标(例如,研究问题或教学目标)的专家级判断。大规模评估LLM生成的标注与专家生成的标注是否一致具有挑战性,并且目前不存在经过验证的、可扩展的思想相似性度量方法。本文中,我们(i)将LLM对解释性标注的可扩展评估作为一项关键且未被充分研究的任务引入,(ii)提出IDEAlgin,一种直观的基准测试范例,通过“奇数挑一”的三元组判断任务来捕获专家相似性评级,以及(iii)根据这些人类基准,评估各种相似性度量,包括基于向量的度量(主题模型、嵌入)和LLM-as-a-judge。将此方法应用于两个真实的教育数据集(解释性分析和反馈生成),我们发现基于向量的度量在很大程度上未能捕获对专家有意义的细微相似性维度。与传统的词汇和基于向量的度量相比,通过IDEAlgin提示LLM可以显著提高与专家判断的一致性(提高9-30%)。这些结果将IDEAlgin确立为一种有前景的范例,用于大规模评估LLM与开放式专家标注的对齐程度,从而为LLM在教育及其他领域的负责任部署提供信息。
🔬 方法详解
问题定义:论文旨在解决如何有效评估大型语言模型(LLM)在开放式、解释性标注任务中,其生成的标注结果与人类专家标注结果的对齐程度的问题。现有方法,如基于词汇或向量相似度的度量,无法充分捕捉专家在解释性标注中使用的细微语义和推理,导致评估结果与人类专家的主观判断存在较大偏差。
核心思路:论文的核心思路是利用“奇数挑一”(Pick-the-Odd-One-Out)的三元组判断任务,构建一个基准测试框架(IDEAlgin),通过收集专家对标注相似性的主观评判,作为评估LLM标注质量的黄金标准。然后,利用这个基准来评估各种相似性度量方法,包括传统的向量方法和基于LLM的方法。
技术框架:IDEAlgin框架主要包含以下几个阶段: 1. 数据收集:收集开放式解释性标注任务的数据集,例如学生作业反馈或文本主题分析。 2. 三元组构建:从数据集中选取三个标注,其中两个标注在某种程度上相似,另一个则不同。 3. 专家标注:邀请领域专家对每个三元组进行判断,选择与其他两个标注最不相似的标注。 4. LLM标注:使用不同的LLM和prompt策略生成标注。 5. 相似性度量:使用各种相似性度量方法(如向量相似度、LLM-as-a-judge)计算LLM标注与专家标注之间的相似度。 6. 评估:将各种相似性度量方法的结果与专家判断进行比较,评估其与人类专家判断的对齐程度。
关键创新:该论文的关键创新在于提出了IDEAlgin基准测试范例,它通过“奇数挑一”任务,直接捕捉了专家对标注相似性的主观判断,从而提供了一个更可靠、更贴近人类认知的评估标准。与传统的基于词汇或向量相似度的评估方法相比,IDEAlgin能够更好地反映专家在解释性标注中使用的细微语义和推理。
关键设计:IDEAlgin的关键设计包括: 1. 三元组构建策略:如何选择具有代表性的三元组,以覆盖不同的相似性维度。 2. 专家招募和培训:如何确保专家的判断质量和一致性。 3. LLM Prompt设计:如何设计有效的prompt,引导LLM进行相似性判断,并减少偏差。 4. 相似性度量方法选择:如何选择合适的相似性度量方法,以捕捉不同类型的语义关系。
🖼️ 关键图片


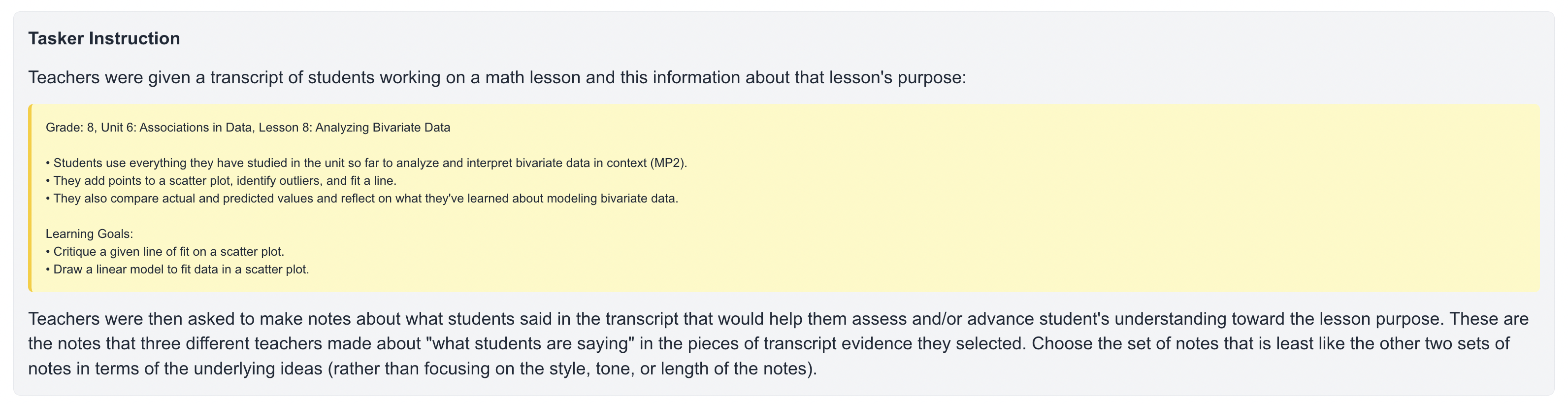
📊 实验亮点
实验结果表明,传统的基于向量的相似性度量方法在捕捉专家对解释性标注的细微理解方面表现不佳。通过IDEAlgin提示LLM,可以显著提高其与专家判断的一致性,提升幅度达到9-30%。这表明IDEAlgin是一种有效的评估LLM在开放式解释性标注任务中表现的范例。
🎯 应用场景
该研究成果可广泛应用于教育、社会科学、人文学科等领域,用于评估和改进LLM在开放式解释性标注任务中的表现。例如,可以用于评估LLM生成的学生作业反馈的质量,或评估LLM在主题分析中的一致性。该方法有助于负责任地部署LLM,并确保其在需要专家判断的任务中能够提供高质量的标注。
📄 摘要(原文)
Large language models (LLMs) are increasingly applied to open-ended, interpretive annotation tasks, such as thematic analysis by researchers or generating feedback on student work by teachers. These tasks involve free-text annotations requiring expert-level judgments grounded in specific objectives (e.g., research questions or instructional goals). Evaluating whether LLM-generated annotations align with those generated by expert humans is challenging to do at scale, and currently, no validated, scalable measure of similarity in ideas exists. In this paper, we (i) introduce the scalable evaluation of interpretive annotation by LLMs as a critical and understudied task, (ii) propose IDEAlgin, an intuitive benchmarking paradigm for capturing expert similarity ratings via a "pick-the-odd-one-out" triplet judgment task, and (iii) evaluate various similarity metrics, including vector-based ones (topic models, embeddings) and LLM-as-a-judge via IDEAlgin, against these human benchmarks. Applying this approach to two real-world educational datasets (interpretive analysis and feedback generation), we find that vector-based metrics largely fail to capture the nuanced dimensions of similarity meaningful to experts. Prompting LLMs via IDEAlgin significantly improves alignment with expert judgments (9-30% increase) compared to traditional lexical and vector-based metrics. These results establish IDEAlgin as a promising paradigm for evaluating LLMs against open-ended expert annotations at scale, informing responsible deployment of LLMs in education and beyond.