SSVD: Structured SVD for Parameter-Efficient Fine-Tuning and Benchmarking under Domain Shift in ASR
作者: Pu Wang, Shinji Watanabe, Hugo Van hamme
分类: cs.CL, eess.AS
发布日期: 2025-09-02
备注: Accepted by IEEE ASRU 2025
💡 一句话要点
提出SSVD,通过结构化SVD微调提升ASR领域迁移性能与效率。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 领域自适应 语音识别 奇异值分解 结构化学习
📋 核心要点
- 现有参数高效微调方法在语音领域,尤其是在领域迁移场景下的ASR任务中,验证不足。
- 提出结构化SVD引导的微调方法(SSVD),通过选择性旋转奇异向量,在保留语义信息的同时实现高效领域自适应。
- 在多种领域转移的ASR任务上,SSVD在不同模型规模下均表现出良好的性能,并开源了所有实现。
📝 摘要(中文)
参数高效微调(PEFT)已成为适应大型基础模型的可扩展解决方案。虽然低秩适应(LoRA)在语音应用中被广泛使用,但其最先进的变体,如VeRA、DoRA、PiSSA和SVFT,主要为语言和视觉任务开发,在语音方面的验证有限。本文首次在ESPnet中全面集成和基准测试了这些PEFT方法。我们进一步提出了结构化SVD引导(SSVD)微调,它选择性地旋转输入相关的右奇异向量,同时保持输出相关的向量固定,以保留语义映射。这种设计能够以最少的训练参数和更高的效率实现鲁棒的领域自适应。我们在领域转移的语音识别任务上评估了所有方法,包括儿童语音和方言变异,模型规模从0.1B到2B。所有实现都在ESPnet中发布,以支持可重复性和未来的工作。
🔬 方法详解
问题定义:论文旨在解决语音识别(ASR)中,当训练数据和测试数据存在领域差异时,模型性能显著下降的问题。现有的参数高效微调(PEFT)方法,如LoRA及其变体,虽然在语言和视觉任务中表现良好,但在语音领域,尤其是在处理儿童语音、方言变异等领域迁移问题时,验证不足,且可能无法有效保留语音的语义信息。
核心思路:论文的核心思路是利用结构化的奇异值分解(SVD)来引导模型的微调过程。通过选择性地旋转与输入相关的右奇异向量,同时保持与输出相关的向量固定,SSVD旨在保留原始模型的语义映射,并实现对特定领域的有效适应。这种方法能够在减少可训练参数的同时,提升模型在领域迁移场景下的鲁棒性。
技术框架:SSVD方法主要包含以下几个步骤:1) 对预训练模型的权重矩阵进行奇异值分解(SVD);2) 选择性地旋转与输入相关的右奇异向量,而保持与输出相关的左奇异向量固定;3) 使用领域特定的数据对旋转后的模型进行微调。整个过程在ESPnet框架下实现,方便集成和复现。
关键创新:SSVD的关键创新在于其结构化的SVD引导微调策略。与传统的LoRA等方法不同,SSVD不是简单地添加低秩矩阵,而是通过旋转奇异向量来调整模型的参数。这种结构化的方法能够更有效地保留原始模型的语义信息,并实现对特定领域的精确适应。此外,SSVD选择性地旋转输入相关的奇异向量,而保持输出相关的向量不变,进一步增强了其在领域迁移场景下的鲁棒性。
关键设计:SSVD的关键设计包括:1) 如何确定哪些奇异向量与输入相关,哪些与输出相关(具体实现细节未知);2) 旋转奇异向量的具体方法(例如,使用可学习的旋转矩阵);3) 微调过程中的学习率、batch size等超参数设置。论文中提到所有实现都在ESPnet中发布,因此具体的实现细节可以在代码中找到。
🖼️ 关键图片


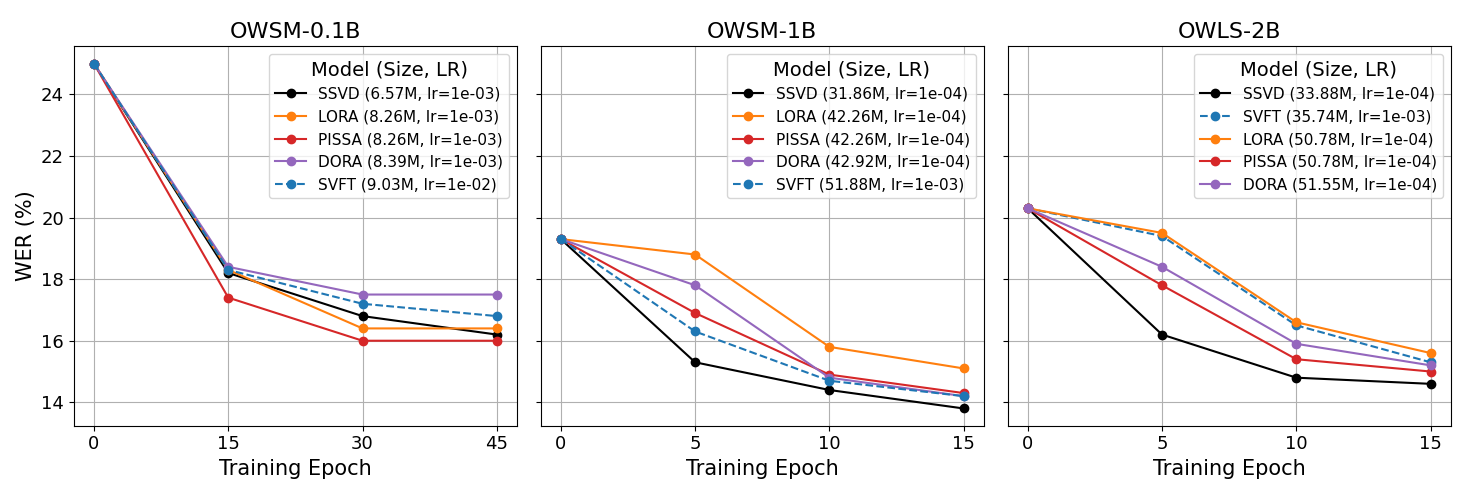
📊 实验亮点
论文在领域转移的语音识别任务上进行了广泛的实验,包括儿童语音和方言变异。实验结果表明,SSVD方法在不同模型规模(0.1B到2B)下均优于现有的PEFT方法,例如LoRA。具体的性能提升数据需要在论文中查找。此外,论文还开源了所有实现,为后续研究提供了便利。
🎯 应用场景
该研究成果可应用于各种语音识别场景,尤其是在数据分布存在偏差的情况下,例如儿童语音识别、方言语音识别、噪声环境下的语音识别等。通过SSVD方法,可以有效地提升模型在这些场景下的性能,降低对大量领域特定数据的依赖,从而降低模型部署和维护的成本。此外,该方法还可以推广到其他语音处理任务,如语音合成、语音增强等。
📄 摘要(原文)
Parameter-efficient fine-tuning (PEFT) has emerged as a scalable solution for adapting large foundation models. While low-rank adaptation (LoRA) is widely used in speech applications, its state-of-the-art variants, e.g., VeRA, DoRA, PiSSA, and SVFT, are developed mainly for language and vision tasks, with limited validation in speech. This work presents the first comprehensive integration and benchmarking of these PEFT methods within ESPnet. We further introduce structured SVD-guided (SSVD) fine-tuning, which selectively rotates input-associated right singular vectors while keeping output-associated vectors fixed to preserve semantic mappings. This design enables robust domain adaptation with minimal trainable parameters and improved efficiency. We evaluate all methods on domain-shifted speech recognition tasks, including child speech and dialectal variation, across model scales from 0.1B to 2B. All implementations are released in ESPnet to support reproducibility and future work.