PalmX 2025: The First Shared Task on Benchmarking LLMs on Arabic and Islamic Culture
作者: Fakhraddin Alwajih, Abdellah El Mekki, Hamdy Mubarak, Majd Hawasly, Abubakr Mohamed, Muhammad Abdul-Mageed
分类: cs.CL
发布日期: 2025-09-02
备注: https://palmx.dlnlp.ai/
💡 一句话要点
PalmX 2025:首个面向阿拉伯和伊斯兰文化的大语言模型评测共享任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 阿拉伯文化 伊斯兰文化 文化理解 基准测试
📋 核心要点
- 现有大语言模型在阿拉伯和伊斯兰文化知识方面存在不足,尤其是在代表性不足的主题上。
- PalmX 2025 通过构建包含阿拉伯和伊斯兰文化选择题的共享任务,来评估和提升 LLM 在这些领域的文化能力。
- 实验结果表明,针对特定任务的微调可以显著提高模型性能,参数高效微调是有效方法,数据增强效果依赖于领域。
📝 摘要(中文)
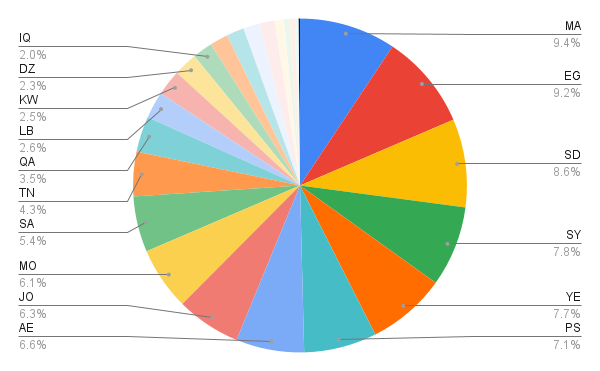
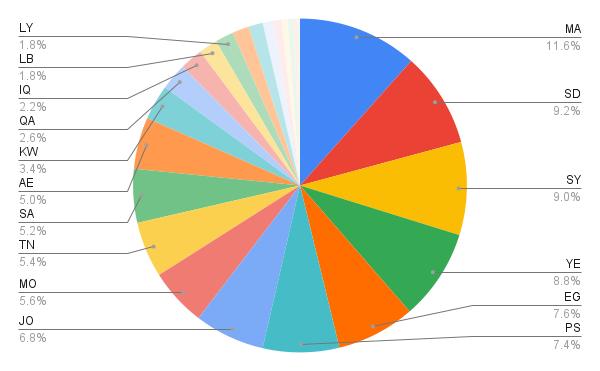
大型语言模型(LLMs)在预训练阶段会受到大量数据分布的影响。由于这些数据主要来自网络,因此很可能偏向于高资源语言和文化,例如西方文化。因此,LLM 通常对某些社群的理解不足,尤其是在阿拉伯和伊斯兰文化知识方面。对于代表性不足的主题,这个问题更加突出。为了应对这一挑战,我们推出了 PalmX 2025,这是首个旨在评估 LLM 在这些特定领域文化能力的共享任务。该任务由两个子任务组成,包含现代标准阿拉伯语(MSA)的选择题(MCQ):通用阿拉伯文化和通用伊斯兰文化。这些子任务涵盖了广泛的主题,包括来自 22 个阿拉伯国家的传统、食物、历史、宗教习俗和语言表达。该倡议引起了广泛关注,有 26 个团队注册了子任务 1,19 个团队注册了子任务 2,最终分别有 9 个和 6 个有效提交。我们的研究结果表明,针对特定任务的微调可以显著提高基线模型的性能。表现最佳的系统在文化问题上的准确率达到 72.15%,在伊斯兰知识上的准确率达到 84.22%。参数高效微调成为参与者中最主要和最有效的方法,而数据增强的效用被发现是领域相关的。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)在预训练数据中,由于西方文化数据占比较高,导致其在阿拉伯和伊斯兰文化知识方面存在明显的不足。这使得 LLM 在处理涉及这些文化的任务时,表现不佳,无法准确理解和回答相关问题。因此,需要一种方法来提升 LLM 在这些特定文化领域的理解能力。
核心思路:PalmX 2025 的核心思路是通过构建一个专门针对阿拉伯和伊斯兰文化的基准测试数据集,并组织共享任务,鼓励研究人员开发和优化 LLM 在这些领域的性能。通过任务特定的微调,使模型能够更好地理解和掌握相关文化知识。
技术框架:PalmX 2025 包含两个子任务:通用阿拉伯文化和通用伊斯兰文化。每个子任务都包含一系列选择题(MCQ),这些问题涵盖了广泛的主题,包括传统、食物、历史、宗教习俗和语言表达。参与者需要使用 LLM 来回答这些问题,并提交结果进行评估。评估指标为准确率。
关键创新:PalmX 2025 的关键创新在于它首次提出了一个专门针对阿拉伯和伊斯兰文化的 LLM 评估基准。这填补了现有 LLM 评估体系中的一个空白,并为研究人员提供了一个平台来比较和改进模型在这些领域的性能。
关键设计:PalmX 2025 的关键设计包括:1) 选择题的形式,易于评估和比较不同模型的性能;2) 涵盖广泛的文化主题,确保评估的全面性;3) 使用现代标准阿拉伯语(MSA),保证语言的规范性和通用性;4) 鼓励使用参数高效微调方法,降低计算成本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过任务特定的微调,LLM 在阿拉伯和伊斯兰文化知识方面的性能可以得到显著提升。表现最佳的系统在文化问题上的准确率达到 72.15%,在伊斯兰知识上的准确率达到 84.22%。参数高效微调成为最主要和最有效的方法。
🎯 应用场景
该研究成果可应用于提升智能客服、文化交流、教育等领域中涉及阿拉伯和伊斯兰文化的语言模型的性能。通过提高模型对这些文化的理解,可以改善用户体验,促进跨文化交流,并为教育提供更准确的知识。
📄 摘要(原文)
Large Language Models (LLMs) inherently reflect the vast data distributions they encounter during their pre-training phase. As this data is predominantly sourced from the web, there is a high chance it will be skewed towards high-resourced languages and cultures, such as those of the West. Consequently, LLMs often exhibit a diminished understanding of certain communities, a gap that is particularly evident in their knowledge of Arabic and Islamic cultures. This issue becomes even more pronounced with increasingly under-represented topics. To address this critical challenge, we introduce PalmX 2025, the first shared task designed to benchmark the cultural competence of LLMs in these specific domains. The task is composed of two subtasks featuring multiple-choice questions (MCQs) in Modern Standard Arabic (MSA): General Arabic Culture and General Islamic Culture. These subtasks cover a wide range of topics, including traditions, food, history, religious practices, and language expressions from across 22 Arab countries. The initiative drew considerable interest, with 26 teams registering for Subtask 1 and 19 for Subtask 2, culminating in nine and six valid submissions, respectively. Our findings reveal that task-specific fine-tuning substantially boosts performance over baseline models. The top-performing systems achieved an accuracy of 72.15% on cultural questions and 84.22% on Islamic knowledge. Parameter-efficient fine-tuning emerged as the predominant and most effective approach among participants, while the utility of data augmentation was found to be domain-dependent.