Implicit Actor Critic Coupling via a Supervised Learning Framework for RLVR
作者: Jiaming Li, Longze Chen, Ze Gong, Yukun Chen, Lu Wang, Wanwei He, Run Luo, Min Yang
分类: cs.CL, cs.LG
发布日期: 2025-09-02
🔗 代码/项目: GITHUB
💡 一句话要点
提出PACS框架,通过监督学习隐式耦合Actor-Critic,提升RLVR中LLM的推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 可验证奖励 大型语言模型 监督学习 策略优化 数学推理 Actor-Critic 隐式耦合
📋 核心要点
- 现有RLVR方法面临奖励稀疏和策略梯度更新不稳定的挑战,尤其是在基于强化学习的方法中。
- PACS框架将RLVR问题转化为监督学习任务,通过预测奖励标签隐式耦合Actor和Critic,实现更稳定的训练。
- 实验表明,PACS在数学推理任务上显著优于PPO和GRPO等基线方法,提升了LLM的推理性能。
📝 摘要(中文)
本文提出了一种名为PACS的新型RLVR框架,旨在解决现有RLVR方法中奖励稀疏和策略梯度更新不稳定等问题。PACS通过将结果奖励视为可预测的标签,将RLVR问题转化为一个监督学习任务,该任务基于由策略模型参数化的评分函数,并使用交叉熵损失进行优化。详细的梯度分析表明,这种监督学习形式在本质上恢复了经典的策略梯度更新,同时隐式地耦合了actor和critic的角色,从而实现了更稳定和高效的训练。在具有挑战性的数学推理任务上的基准测试表明,PACS优于强大的RLVR基线方法,如PPO和GRPO,实现了卓越的推理性能。例如,PACS在AIME 2025上实现了59.78%的pass@256,比PPO和GRPO分别提高了13.32和14.36个百分点。这种简单而强大的框架为LLM基于可验证奖励的后训练提供了一条有希望的途径。
🔬 方法详解
问题定义:论文旨在解决RLVR(Reinforcement Learning with Verifiable Rewards)框架下,大型语言模型(LLMs)在处理复杂推理任务时,由于奖励信号稀疏和策略梯度更新不稳定而导致的训练困难问题。现有方法,如基于强化学习的PPO和GRPO,难以有效地利用可验证的奖励来指导策略优化,限制了LLMs在数学和编程等领域的应用。
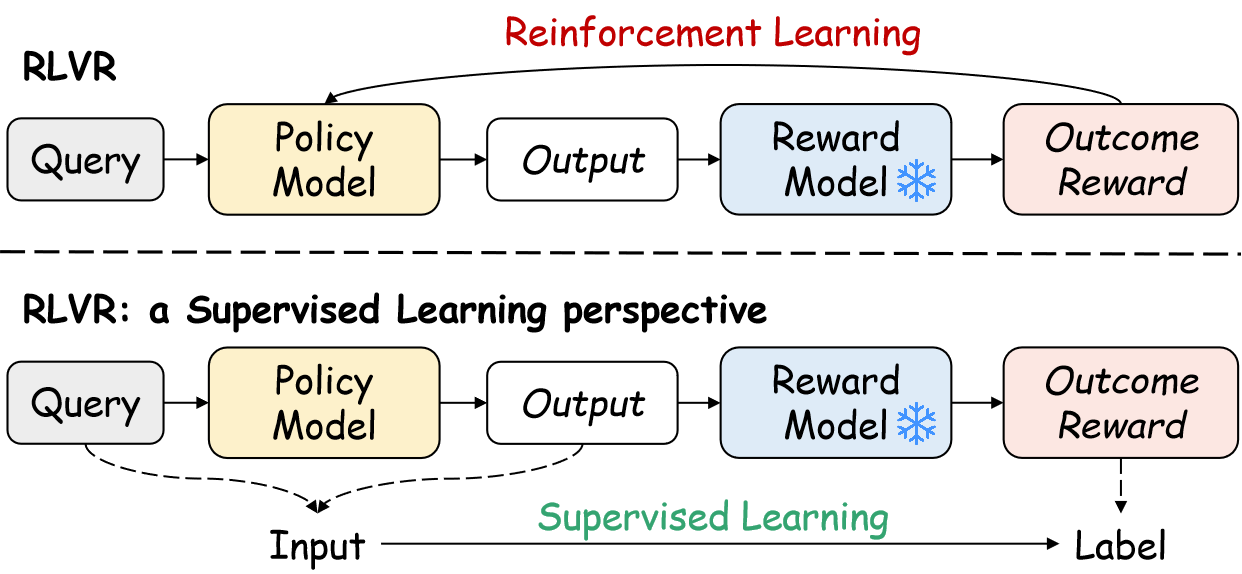
核心思路:PACS的核心思路是将RLVR问题重新表述为一个监督学习问题。具体来说,它将可验证的结果奖励视为一个可预测的标签,然后训练一个评分函数(由策略模型参数化)来预测这个标签。通过这种方式,PACS将强化学习中的策略优化问题转化为一个监督学习中的分类问题,从而可以利用交叉熵损失等成熟的监督学习技术进行训练。
技术框架:PACS的整体框架包括以下几个关键步骤:1) 使用策略模型生成输出;2) 使用可验证的奖励函数评估输出,得到奖励标签;3) 使用奖励标签作为监督信号,训练评分函数(策略模型)来预测奖励标签。训练过程使用交叉熵损失函数,优化策略模型的参数。该框架避免了显式的Actor-Critic结构,而是通过监督学习隐式地耦合了Actor和Critic的角色。
关键创新:PACS最重要的技术创新在于其将RLVR问题转化为监督学习问题的思路。这种转化避免了传统强化学习方法中策略梯度估计的方差问题,并允许使用更稳定和高效的监督学习算法进行训练。此外,PACS通过监督学习隐式地耦合了Actor和Critic的角色,避免了显式Actor-Critic结构带来的复杂性和训练难度。
关键设计:PACS的关键设计包括:1) 使用交叉熵损失函数作为训练目标,鼓励策略模型生成能够获得高奖励的输出;2) 使用策略模型本身作为评分函数,避免了引入额外的Critic网络;3) 通过梯度分析证明,该监督学习框架在本质上恢复了经典的策略梯度更新,保证了算法的收敛性。
🖼️ 关键图片

📊 实验亮点
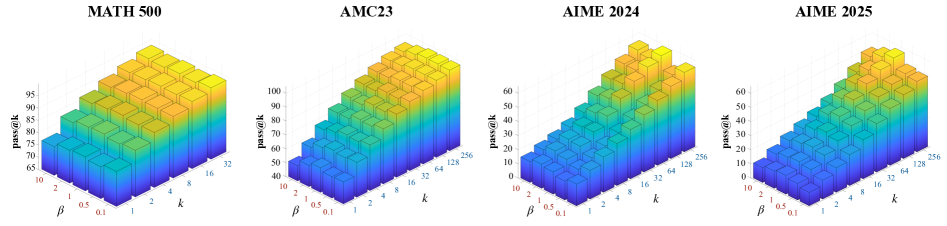
PACS在AIME 2025数学推理任务上取得了显著的性能提升,pass@256指标达到59.78%,相比于PPO和GRPO基线分别提高了13.32和14.36个百分点。实验结果表明,PACS能够更有效地利用可验证的奖励来指导策略优化,从而提升LLM的推理能力。
🎯 应用场景
PACS框架具有广泛的应用前景,可用于提升大型语言模型在需要可验证奖励的复杂推理任务中的表现,例如数学问题求解、代码生成、逻辑推理等。该方法可以应用于教育、科研、软件开发等领域,提高LLM的可靠性和实用性,并促进人机协作。
📄 摘要(原文)
Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) have empowered large language models (LLMs) to tackle challenging reasoning tasks such as mathematics and programming. RLVR leverages verifiable outcome rewards to guide policy optimization, enabling LLMs to progressively improve output quality in a grounded and reliable manner. Despite its promise, the RLVR paradigm poses significant challenges, as existing methods often suffer from sparse reward signals and unstable policy gradient updates, particularly in RL-based approaches. To address the challenges, we propose $\textbf{PACS}$, a novel RLVR framework that achieves im$\textbf{P}$licit $\textbf{A}$ctor $\textbf{C}$ritic coupling via a $\textbf{S}$upervised learning framework. By treating the outcome reward as a predictable label, we reformulate the RLVR problem into a supervised learning task over a score function parameterized by the policy model and optimized using cross-entropy loss. A detailed gradient analysis shows that this supervised formulation inherently recovers the classical policy gradient update while implicitly coupling actor and critic roles, yielding more stable and efficient training. Benchmarking on challenging mathematical reasoning tasks, PACS outperforms strong RLVR baselines, such as PPO and GRPO, achieving superior reasoning performance. For instance, PACS achieves 59.78\% at pass@256 on AIME 2025, representing improvements of 13.32 and 14.36 points over PPO and GRPO. This simple yet powerful framework offers a promising avenue for LLMs post-training with verifiable rewards. Our code and data are available as open source at https://github.com/ritzz-ai/PACS.