MoSEs: Uncertainty-Aware AI-Generated Text Detection via Mixture of Stylistics Experts with Conditional Thresholds
作者: Junxi Wu, Jinpeng Wang, Zheng Liu, Bin Chen, Dongjian Hu, Hao Wu, Shu-Tao Xia
分类: cs.CL, cs.AI
发布日期: 2025-09-02 (更新: 2025-09-08)
备注: EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
MoSEs:通过混合文体专家模型与条件阈值实现不确定性感知的AI生成文本检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成文本检测 文体建模 不确定性量化 条件阈值估计 混合专家模型
📋 核心要点
- 现有AI生成文本检测方法忽略文体建模,依赖静态阈值,导致检测性能受限。
- MoSEs框架通过混合文体专家模型和条件阈值估计,实现文体感知的AI生成文本检测。
- 实验结果表明,MoSEs在检测性能上优于基线方法,尤其在低资源场景下提升显著。
📝 摘要(中文)
大型语言模型的快速发展加剧了公众对其潜在滥用的担忧。因此,构建可信赖的AI生成文本检测系统至关重要。现有方法忽略了文体建模,并且主要依赖于静态阈值,这极大地限制了检测性能。本文提出了混合文体专家(MoSEs)框架,该框架通过条件阈值估计实现文体感知的不确定性量化。MoSEs包含三个核心组件,即文体参考库(SRR)、文体感知路由器(SAR)和条件阈值估计器(CTE)。对于输入文本,SRR可以激活SRR中适当的参考数据,并将其提供给CTE。随后,CTE联合建模语言统计属性和语义特征,以动态确定最佳阈值。通过判别分数,MoSEs产生具有相应置信水平的预测标签。与基线相比,我们的框架在检测性能方面平均提高了11.34%。更令人鼓舞的是,MoSEs在低资源情况下表现出更明显的改进,达到了39.15%。我们的代码可在https://github.com/creator-xi/MoSEs 获得。
🔬 方法详解
问题定义:当前AI生成文本检测方法主要痛点在于忽略了文本的文体特征,并且依赖于固定的阈值进行判断。这种方式无法适应不同风格的生成文本,导致检测准确率不高,尤其是在数据资源匮乏的情况下,性能下降更为明显。
核心思路:MoSEs的核心思路是利用文体信息来提升AI生成文本检测的准确性和鲁棒性。通过构建文体专家混合模型,针对不同文体选择合适的检测策略,并动态调整阈值,从而更好地适应各种风格的AI生成文本。
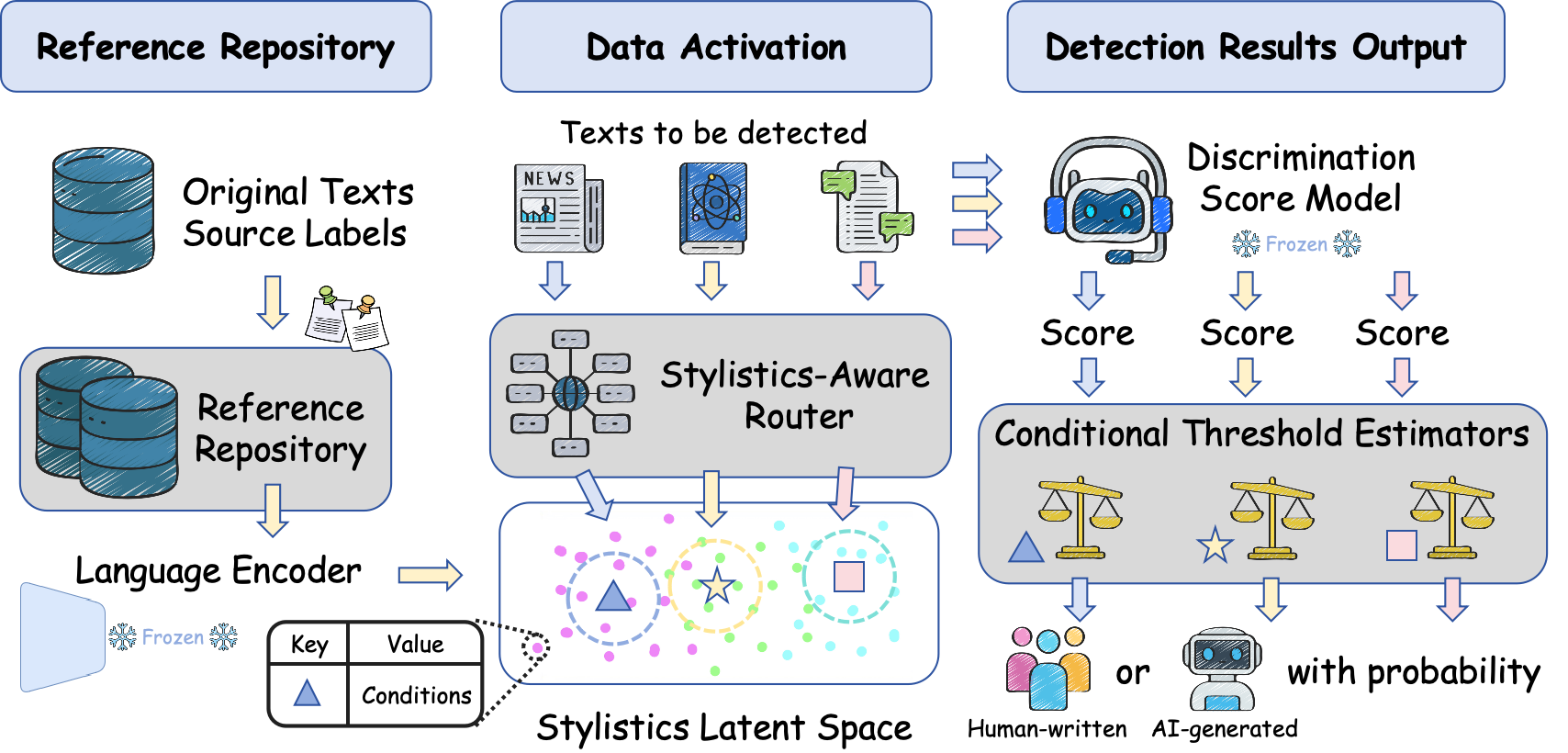
技术框架:MoSEs框架包含三个主要模块:文体参考库(SRR)、文体感知路由器(SAR)和条件阈值估计器(CTE)。首先,SRR存储了各种文体的参考数据。然后,SAR根据输入文本的文体特征,从SRR中选择合适的参考数据。最后,CTE结合语言统计属性和语义特征,动态估计最佳阈值,并输出预测标签和置信度。
关键创新:MoSEs的关键创新在于引入了文体信息进行AI生成文本检测,并提出了动态阈值估计方法。与传统的静态阈值方法相比,MoSEs能够根据输入文本的文体特征自适应地调整阈值,从而提高检测的准确性和鲁棒性。此外,混合文体专家模型的设计使得MoSEs能够处理各种风格的AI生成文本。
关键设计:SRR的构建需要收集和整理各种文体的文本数据。SAR可以使用文本分类模型或相似度计算方法来确定输入文本的文体。CTE可以采用神经网络模型,输入语言统计特征(如词频、句法结构)和语义特征(如词向量、句子嵌入),输出动态阈值。损失函数的设计需要考虑检测的准确率和置信度,例如可以使用交叉熵损失函数和置信度惩罚项。
🖼️ 关键图片

📊 实验亮点
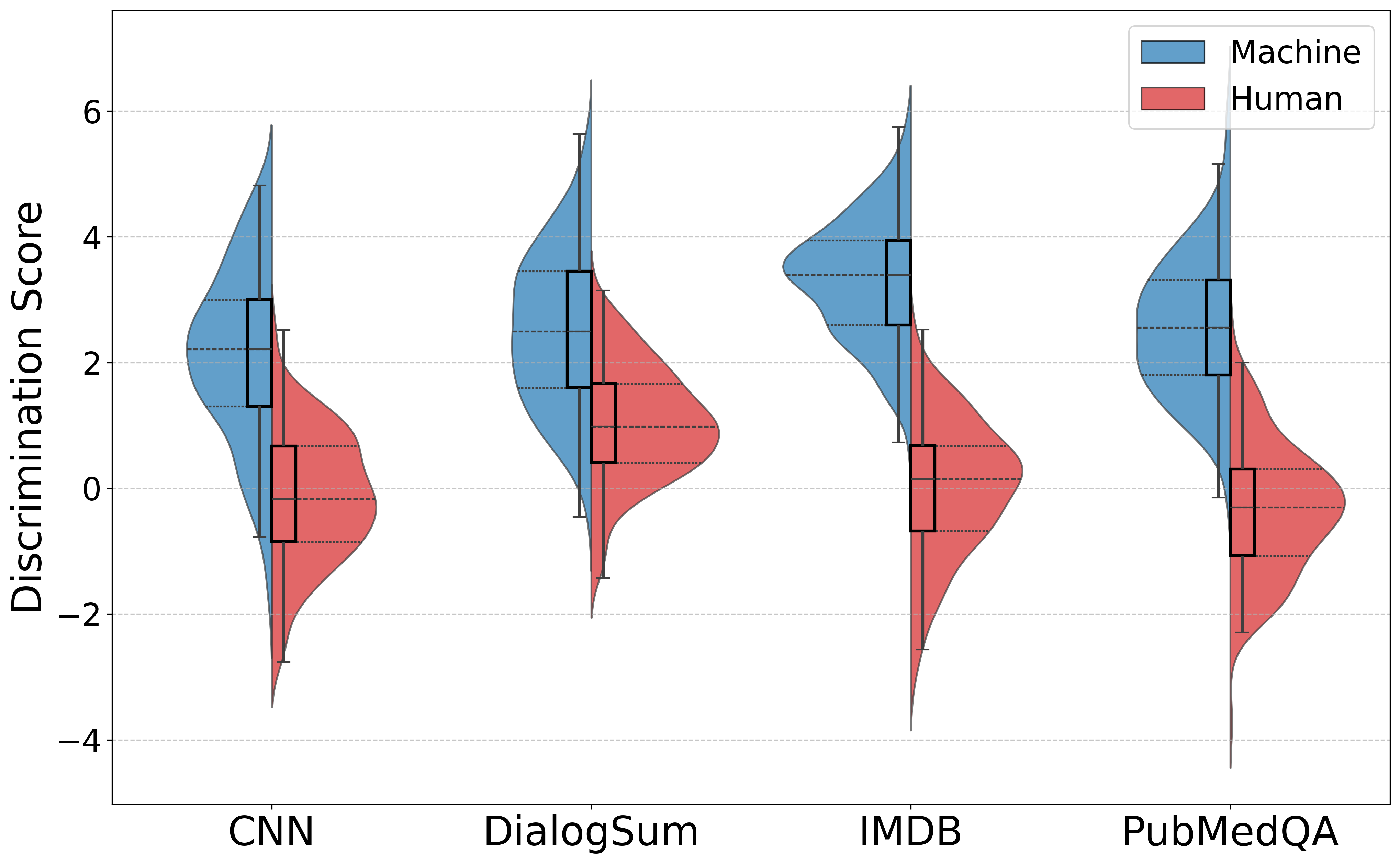
MoSEs框架在AI生成文本检测任务上取得了显著的性能提升,平均检测性能比基线方法提高了11.34%。更重要的是,在低资源情况下,MoSEs的性能提升高达39.15%,表明其具有很强的泛化能力和鲁棒性。这些实验结果充分证明了MoSEs框架在文体感知和动态阈值估计方面的优势。
🎯 应用场景
MoSEs可应用于内容安全、学术诚信、舆情监控等领域。通过准确识别AI生成的文本,可以有效防止虚假信息的传播,维护网络空间的健康秩序。该技术还有助于检测学术论文中的抄袭行为,保障学术研究的原创性。未来,MoSEs可以与其他安全技术结合,构建更强大的AI生成内容检测系统。
📄 摘要(原文)
The rapid advancement of large language models has intensified public concerns about the potential misuse. Therefore, it is important to build trustworthy AI-generated text detection systems. Existing methods neglect stylistic modeling and mostly rely on static thresholds, which greatly limits the detection performance. In this paper, we propose the Mixture of Stylistic Experts (MoSEs) framework that enables stylistics-aware uncertainty quantification through conditional threshold estimation. MoSEs contain three core components, namely, the Stylistics Reference Repository (SRR), the Stylistics-Aware Router (SAR), and the Conditional Threshold Estimator (CTE). For input text, SRR can activate the appropriate reference data in SRR and provide them to CTE. Subsequently, CTE jointly models the linguistic statistical properties and semantic features to dynamically determine the optimal threshold. With a discrimination score, MoSEs yields prediction labels with the corresponding confidence level. Our framework achieves an average improvement 11.34% in detection performance compared to baselines. More inspiringly, MoSEs shows a more evident improvement 39.15% in the low-resource case. Our code is available at https://github.com/creator-xi/MoSEs.