JudgeAgent: Beyond Static Benchmarks for Knowledge-Driven and Dynamic LLM Evaluation
作者: Zhichao Shi, Xuhui Jiang, Chengjin Xu, Cangli Yao, Shengjia Ma, Yinghan Shen, Zixuan Li, Jian Guo, Yuanzhuo Wang
分类: cs.CL, cs.AI
发布日期: 2025-09-02 (更新: 2026-01-15)
🔗 代码/项目: GITHUB
💡 一句话要点
提出JudgeAgent,用于知识驱动和动态的大语言模型评估,突破静态基准限制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 知识驱动 动态评估 LLM Agent 上下文图
📋 核心要点
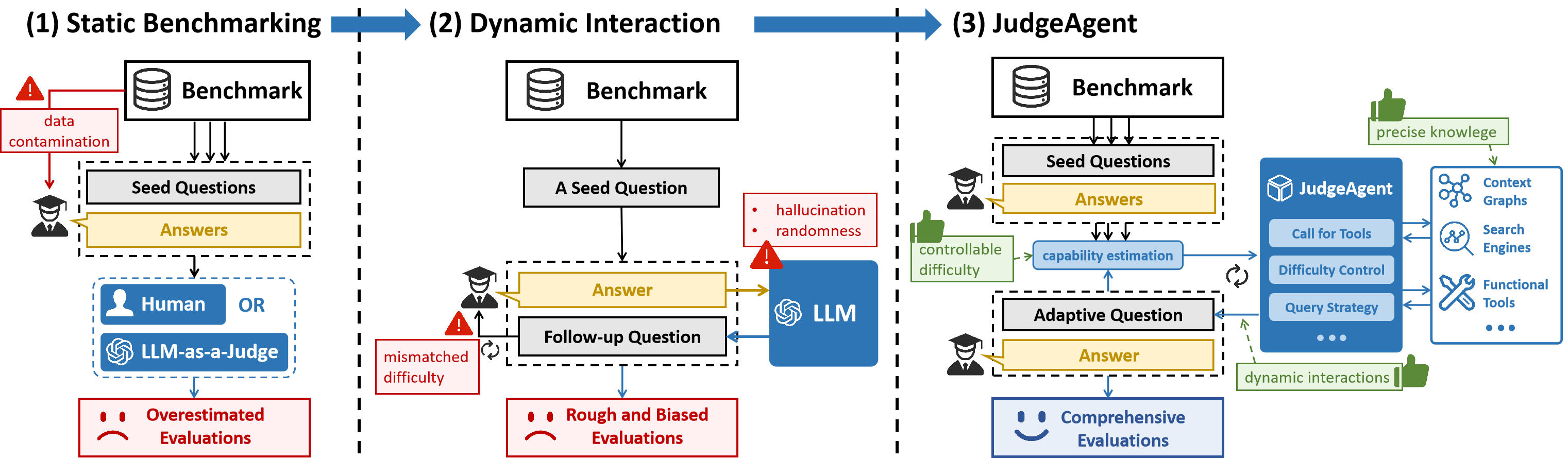
- 现有LLM评估依赖静态基准,存在知识覆盖不足和难度不匹配的问题,导致评估结果片面,阻碍模型优化。
- JudgeAgent利用LLM Agent和上下文图,动态生成问题并进行多轮难度自适应访谈,实现更全面的知识评估。
- 实验表明JudgeAgent能够进行更全面的评估,并促进有效的模型迭代,验证了知识驱动动态评估的潜力。
📝 摘要(中文)
当前大型语言模型(LLM)的评估方法主要依赖于静态基准,这带来了两个主要挑战:知识覆盖范围有限以及固定难度与被评估的LLM不匹配。这些限制导致对LLM知识的评估过于表面化,从而阻碍了有针对性的模型优化。为了弥合这一差距,我们提出了JudgeAgent,一个知识驱动和动态的LLM评估框架。为了解决知识覆盖范围有限的挑战,JudgeAgent利用配备上下文图的LLM Agent,系统地遍历知识结构以生成问题。此外,为了减轻数据污染和难度不匹配,它采用了难度自适应和多轮访谈机制。因此,JudgeAgent可以实现更全面的评估,并促进LLM的更有效改进。实验结果表明,JudgeAgent能够进行更全面的评估,并促进有效的模型迭代,突出了这种知识驱动和动态评估范式的潜力。源代码可在https://github.com/DataArcTech/JudgeAgent上找到。
🔬 方法详解
问题定义:现有的大语言模型(LLM)评估方法主要依赖于静态基准数据集,这些数据集的知识覆盖范围有限,无法全面评估LLM的知识掌握程度。此外,静态基准的难度是固定的,可能与被评估的LLM的能力不匹配,导致评估结果不够准确,难以指导模型优化。数据污染也是一个潜在的问题,即模型可能已经在训练过程中见过了测试数据,导致评估结果虚高。
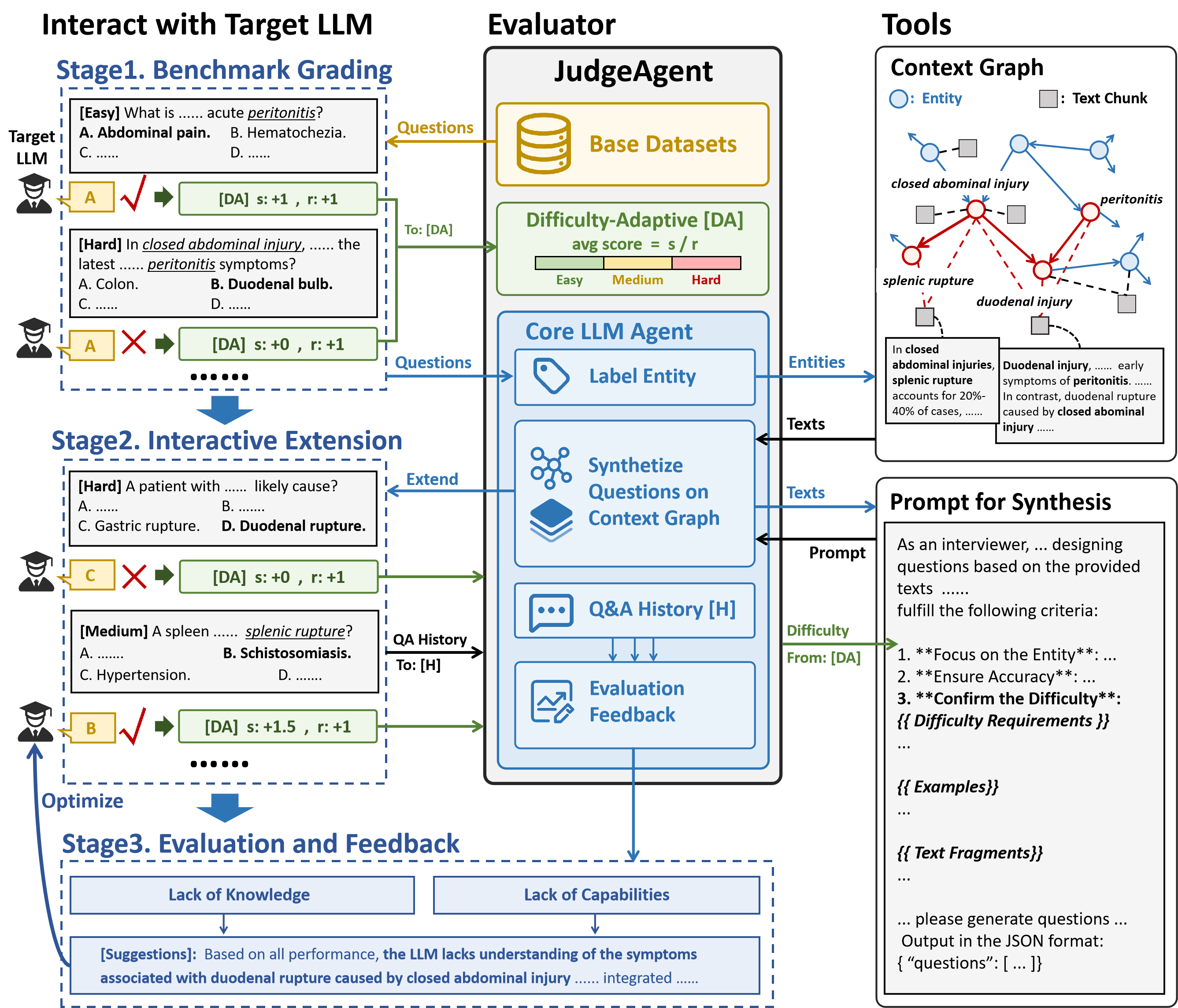
核心思路:JudgeAgent的核心思路是利用LLM Agent来动态生成问题,并采用难度自适应的多轮访谈机制,从而实现更全面、更准确的LLM评估。通过让Agent根据知识图谱自主探索知识,可以扩大评估的知识覆盖范围。通过难度自适应机制,可以根据LLM的回答情况动态调整问题的难度,从而更准确地评估LLM的能力。
技术框架:JudgeAgent的整体框架包含以下几个主要模块:1) 知识图谱构建模块:用于构建包含丰富知识的上下文图。2) 问题生成模块:利用LLM Agent根据上下文图生成问题。3) 难度自适应模块:根据LLM的回答情况动态调整问题的难度。4) 多轮访谈模块:进行多轮问答,深入评估LLM的知识掌握程度。5) 评估模块:对LLM的回答进行评估,给出综合评价。
关键创新:JudgeAgent的关键创新在于其知识驱动和动态评估的范式。与传统的静态基准评估方法相比,JudgeAgent能够更全面地覆盖知识,更准确地评估LLM的能力,并有效避免数据污染。通过LLM Agent自主探索知识和难度自适应机制,JudgeAgent能够模拟人类专家进行评估的过程,从而给出更客观、更可靠的评估结果。
关键设计:在问题生成模块中,使用了基于上下文图的提示工程(Prompt Engineering)技术,引导LLM Agent生成高质量的问题。在难度自适应模块中,采用了基于LLM的难度评估模型,根据LLM的回答情况自动调整问题的难度。多轮访谈的轮数和每次访谈的问题数量可以根据实际情况进行调整。评估模块使用了多种指标,包括准确率、召回率、F1值等,对LLM的回答进行综合评价。
🖼️ 关键图片
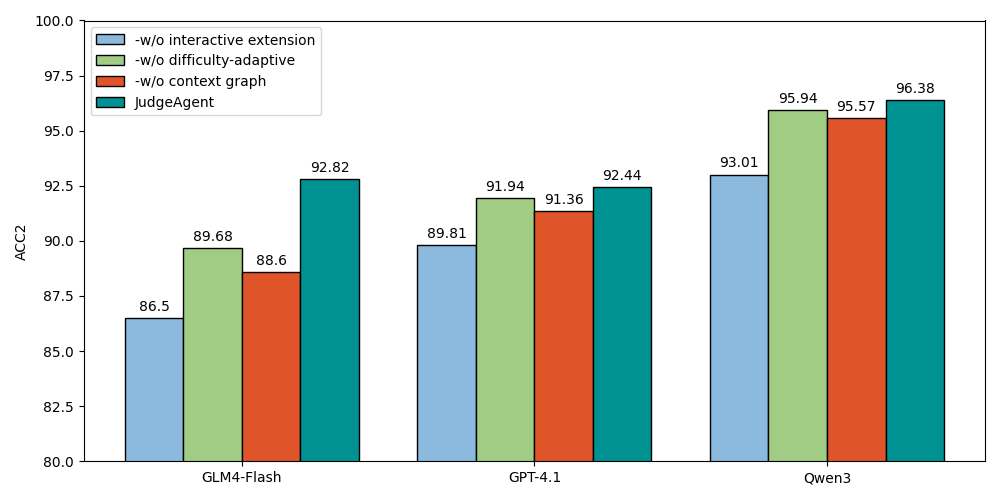
📊 实验亮点
JudgeAgent的实验结果表明,它能够进行更全面的评估,并促进有效的模型迭代。具体来说,JudgeAgent能够发现传统静态基准无法发现的LLM的知识盲区和漏洞。通过使用JudgeAgent进行评估,可以更有效地指导LLM的优化,从而提高LLM的性能和安全性。实验还表明,JudgeAgent能够有效避免数据污染,给出更客观的评估结果。
🎯 应用场景
JudgeAgent可应用于各种需要评估大语言模型能力的场景,例如模型选型、模型优化、模型安全评估等。它可以帮助开发者更全面、更准确地了解LLM的性能,从而选择合适的模型或进行有针对性的优化。此外,JudgeAgent还可以用于评估LLM的安全性,例如检测模型是否存在知识盲区或容易被攻击的漏洞。该研究的未来影响在于推动LLM评估方法的发展,促进LLM技术的进步。
📄 摘要(原文)
Current evaluation methods for large language models (LLMs) primarily rely on static benchmarks, presenting two major challenges: limited knowledge coverage and fixed difficulties that mismatch with the evaluated LLMs. These limitations lead to superficial assessments of LLM knowledge, thereby impeding the targeted model optimizations. To bridge this gap, we propose JudgeAgent, a knowledge-driven and dynamic evaluation framework for LLMs. To address the challenge of limited knowledge coverage, JudgeAgent leverages LLM agents equipped with context graphs to traverse knowledge structures systematically for question generation. Furthermore, to mitigate data contamination and difficulty mismatch, it adopts a difficulty-adaptive and multi-turn interview mechanism. Thereby, JudgeAgent can achieve comprehensive evaluations and facilitate more effective improvement of LLMs. Empirical results demonstrate that JudgeAgent enables more comprehensive evaluations and facilitates effective model iterations, highlighting the potential of this knowledge-driven and dynamic evaluation paradigm. The source code is available on https://github.com/DataArcTech/JudgeAgent.