Better by Comparison: Retrieval-Augmented Contrastive Reasoning for Automatic Prompt Optimization
作者: Juhyeon Lee, Wonduk Seo, Hyunjin An, Seunghyun Lee, Yi Bu
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-09-02 (更新: 2025-10-03)
备注: Preprint
💡 一句话要点
提出CRPO:一种检索增强的对比推理框架,用于自动提示优化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动提示优化 对比推理 检索增强 大型语言模型 提示工程
📋 核心要点
- 现有自动提示优化方法侧重于直接改进或微调,忽略了利用LLM的对比学习能力。
- CRPO框架通过检索参考提示-响应对,利用对比推理优化提示,提升LLM生成质量。
- 实验表明,CRPO在HelpSteer2基准上显著优于现有方法,验证了其有效性。
📝 摘要(中文)
自动提示优化是提升大型语言模型(LLMs)提示质量的一种新兴策略,旨在生成更准确和有用的响应。然而,现有工作主要集中于直接提示改进或模型微调,忽略了利用LLMs内在推理能力从对比示例中学习的潜力。本文提出了对比推理提示优化(CRPO),一种将提示优化形式化为检索增强推理过程的新框架。该方法从HelpSteer2数据集中检索top k个参考提示-响应对,HelpSteer2是一个开源集合,其中每个响应都标注了helpfulness、correctness、coherence、complexity和verbosity。CRPO构建了两种互补的优化范式:(1)分层对比推理,LLM比较高质量、中等质量和低质量的示例(包括提示和响应),通过反思性推理来改进自身的生成;(2)多指标对比推理,LLM分析每个评估维度上的最佳示例,并将它们的优势整合到优化的提示中。通过显式对比高质量和低质量的示例,CRPO使模型能够推断出为什么某些提示成功而另一些提示失败,从而实现更鲁棒和可解释的优化。在HelpSteer2基准上的实验结果表明,CRPO显著优于基线方法。研究结果突出了对比的、检索增强的推理在推进自动提示优化方面的潜力。
🔬 方法详解
问题定义:论文旨在解决自动提示优化问题,现有方法主要通过直接改进或微调提示,缺乏利用LLM的推理能力从对比示例中学习。这些方法难以理解提示成功或失败的根本原因,导致优化效果有限,可解释性差。
核心思路:论文的核心思路是将提示优化视为一个检索增强的对比推理过程。通过检索高质量和低质量的提示-响应对,让LLM学习对比示例,从而理解不同提示的优缺点,并生成更有效的提示。这种方法借鉴了人类学习的方式,通过对比分析来提升理解和推理能力。
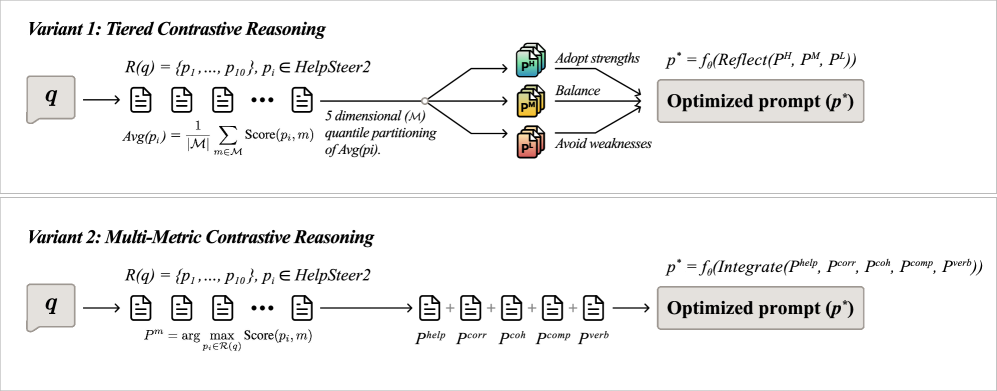
技术框架:CRPO框架包含以下主要模块:1) 检索模块:从HelpSteer2数据集中检索top k个参考提示-响应对。2) 分层对比推理模块:LLM比较高质量、中等质量和低质量的示例,通过反思性推理来改进自身的生成。3) 多指标对比推理模块:LLM分析每个评估维度(helpfulness、correctness等)上的最佳示例,并将它们的优势整合到优化的提示中。最终,LLM生成优化后的提示。
关键创新:CRPO的关键创新在于将对比推理与检索增强相结合,用于自动提示优化。与现有方法相比,CRPO能够显式地对比高质量和低质量的示例,使模型能够推断出为什么某些提示成功而另一些提示失败,从而实现更鲁棒和可解释的优化。这种方法更接近人类的推理过程,能够更好地利用LLM的内在能力。
关键设计:在检索模块中,使用余弦相似度来衡量提示之间的相似性。在分层对比推理模块中,使用不同的温度系数来控制生成的多样性。在多指标对比推理模块中,使用加权平均来整合不同评估维度上的最佳示例。具体的损失函数和网络结构细节未在论文中详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
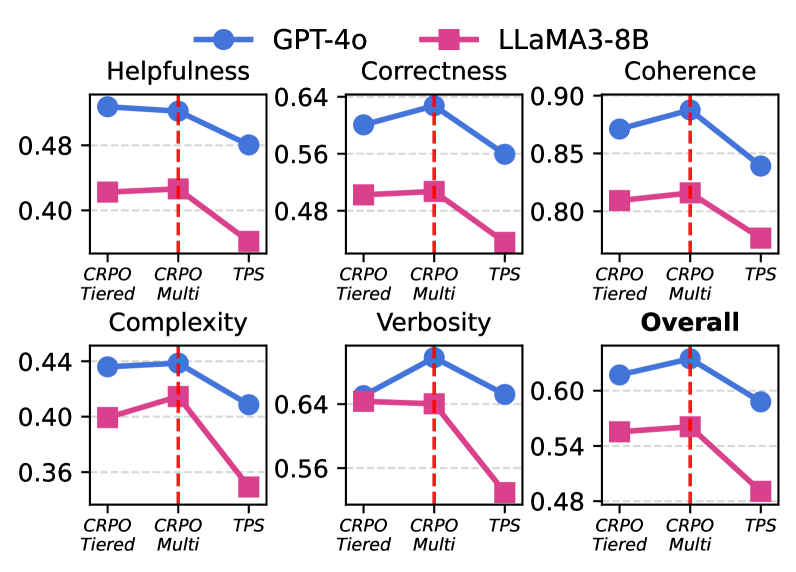
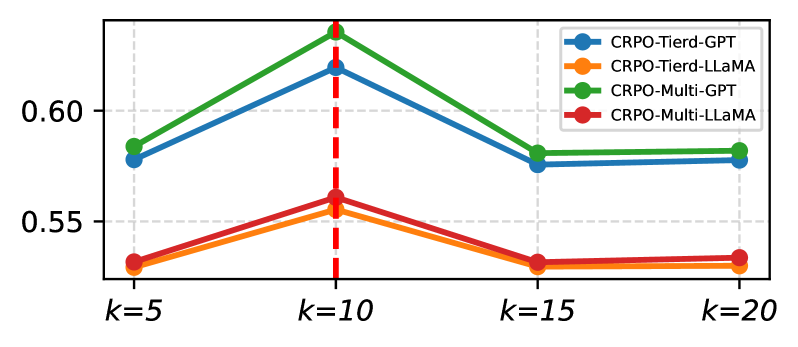
实验结果表明,CRPO在HelpSteer2基准上显著优于基线方法。具体性能数据和提升幅度未在摘要中明确给出(未知),但强调了CRPO在自动提示优化方面的有效性。该研究验证了对比推理和检索增强在提示优化中的潜力。
🎯 应用场景
CRPO可应用于各种需要提示工程的LLM应用场景,例如问答系统、文本摘要、代码生成等。通过自动优化提示,可以显著提升LLM的性能和用户体验,降低人工提示工程的成本。该研究对于提升LLM的通用性和易用性具有重要意义。
📄 摘要(原文)
Automatic prompt optimization has recently emerged as a strategy for improving the quality of prompts used in Large Language Models (LLMs), with the goal of generating more accurate and useful responses. However, most prior work focuses on direct prompt refinement or model fine-tuning, overlooking the potential of leveraging LLMs' inherent reasoning capability to learn from contrasting examples. In this paper, we present Contrastive Reasoning Prompt Optimization (CRPO), a novel framework that formulates prompt optimization as a retrieval-augmented reasoning process. Our approach retrieves top k reference prompt-response pairs from the HelpSteer2 dataset, an open source collection where each response is annotated for helpfulness, correctness, coherence, complexity, and verbosity, and constructs two complementary optimization paradigms: (1) tiered contrastive reasoning, where the LLM compares high-, medium-, and low-quality exemplars (both prompts and responses) to refine its own generation through reflective reasoning, and (2) multi-metric contrastive reasoning, where the LLM analyzes the best exemplars along each evaluation dimension and integrates their strengths into an optimized prompt. By explicitly contrasting high and low quality exemplars, CRPO enables the model to deduce why certain prompts succeed while others fail, thereby achieving more robust and interpretable optimization. Experimental results on the HelpSteer2 benchmark demonstrate that CRPO significantly outperforms baselines. Our findings highlight the promise of contrastive, retrieval-augmented reasoning for advancing automatic prompt optimization.