How Instruction-Tuning Imparts Length Control: A Cross-Lingual Mechanistic Analysis
作者: Elisabetta Rocchetti, Alfio Ferrara
分类: cs.CL, cs.AI
发布日期: 2025-09-02
💡 一句话要点
指令调优通过专门化模型深层组件实现跨语言长度控制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令调优 长度控制 大型语言模型 归因分析 跨语言 文本生成 注意力机制
📋 核心要点
- 大型语言模型难以精确控制生成文本的长度,这是一个显著的挑战。
- 通过分析指令调优前后模型内部组件的贡献,揭示长度控制的机制。
- 指令调优通过专门化模型深层组件,显著提升了长度控制能力,且不同语言存在差异。
📝 摘要(中文)
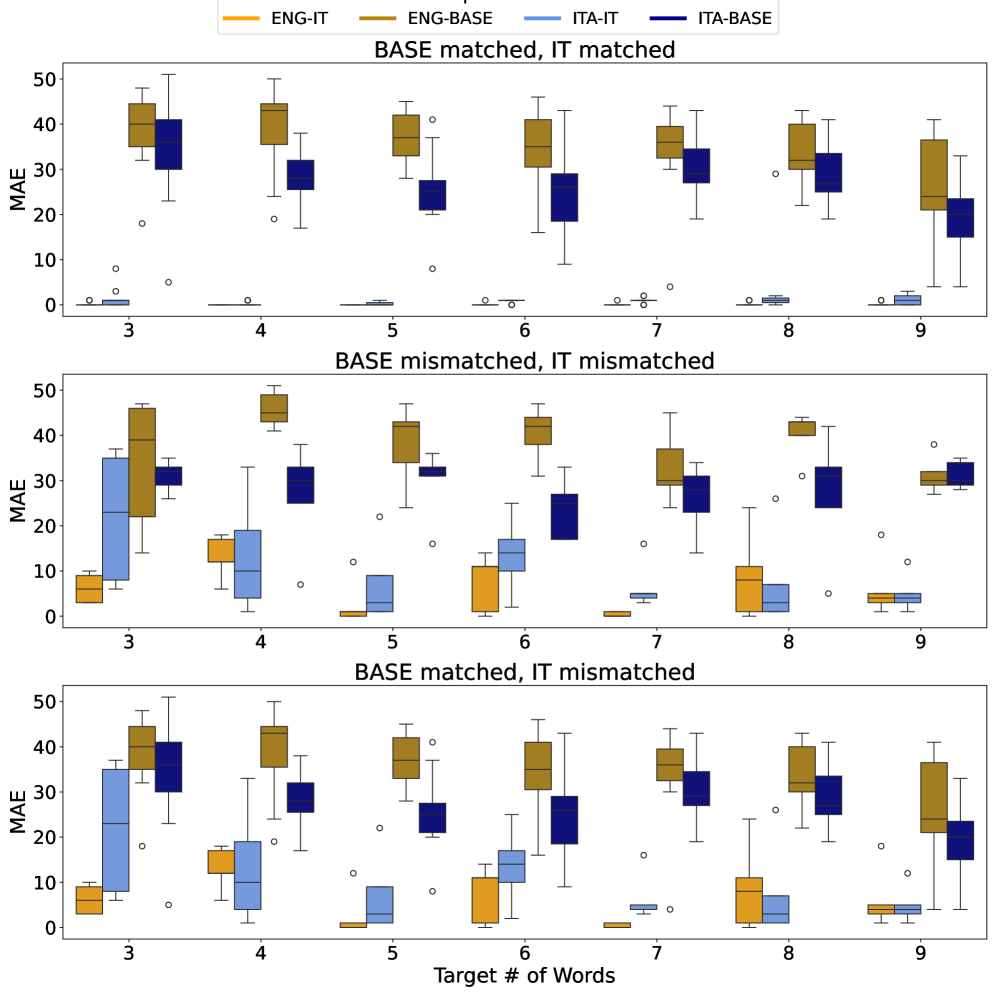
大型语言模型(LLMs)在生成文本时,如何精确地遵守显式的长度约束(例如,生成具有精确字数的文本)仍然是一个重要的挑战。本研究旨在调查基础模型及其指令调优(instruction-tuned)版本在英语和意大利语的长度控制文本生成方面的差异。我们使用累积加权归因(Cumulative Weighted Attribution,一种源自直接Logit归因的指标)分析了性能和内部组件的贡献。我们的研究结果表明,指令调优主要通过专门化模型更深层的组件来显著提高长度控制能力。具体而言,IT模型后期的注意力头(attention heads)显示出越来越积极的贡献,尤其是在英语中。在意大利语中,虽然注意力贡献有所减弱,但最后一层的MLP表现出更强的积极作用,表明存在一种补偿机制。这些结果表明,指令调优重新配置了后期的层以符合任务要求,组件级别的策略可能会适应语言环境。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在文本生成过程中难以精确控制文本长度的问题。现有方法在满足用户指定的长度约束方面表现不佳,缺乏对模型内部机制的深入理解,难以解释和优化长度控制能力。
核心思路:论文的核心思路是通过比较基础模型和指令调优后的模型,分析模型内部组件对长度控制的贡献。通过量化不同组件的重要性,揭示指令调优如何改变模型的行为,从而实现更好的长度控制。论文假设指令调优会专门化模型的某些组件,使其更擅长处理长度约束。
技术框架:论文采用了一种基于归因分析的技术框架。首先,使用基础模型和指令调优后的模型生成文本。然后,使用累积加权归因(Cumulative Weighted Attribution)方法,计算模型中不同组件(如注意力头和MLP层)对生成文本长度的贡献。最后,比较不同模型和语言的归因结果,分析指令调优对模型内部机制的影响。
关键创新:论文的关键创新在于使用累积加权归因方法,深入分析了指令调优对模型内部组件的影响,揭示了指令调优如何通过专门化模型深层组件来提高长度控制能力。此外,论文还发现了不同语言之间长度控制机制的差异,为跨语言长度控制的研究提供了新的视角。
关键设计:论文使用了直接Logit归因(Direct Logit Attribution)方法来计算每个token对最终输出的影响。累积加权归因是基于直接Logit归因的改进,用于衡量模型组件对生成文本长度的整体贡献。论文分析了Transformer模型的注意力头和MLP层,并比较了英语和意大利语的结果。具体的参数设置和网络结构与所使用的预训练语言模型有关,论文中未明确给出详细的参数设置。
🖼️ 关键图片


📊 实验亮点
研究表明,指令调优显著提高了长度控制能力。在英语中,指令调优后的模型后期注意力头表现出更积极的贡献。在意大利语中,虽然注意力贡献减弱,但最后一层MLP表现出更强的积极作用,表明存在补偿机制。这些结果表明,指令调优重新配置了后期的层以符合任务要求。
🎯 应用场景
该研究成果可应用于需要精确长度控制的文本生成任务,例如自动摘要、机器翻译、内容创作等。通过理解指令调优如何影响模型的长度控制能力,可以设计更有效的指令调优策略,提高生成文本的质量和可控性。此外,该研究还可以促进跨语言文本生成技术的发展,使模型能够更好地适应不同语言的长度约束。
📄 摘要(原文)
Adhering to explicit length constraints, such as generating text with a precise word count, remains a significant challenge for Large Language Models (LLMs). This study aims at investigating the differences between foundation models and their instruction-tuned counterparts, on length-controlled text generation in English and Italian. We analyze both performance and internal component contributions using Cumulative Weighted Attribution, a metric derived from Direct Logit Attribution. Our findings reveal that instruction-tuning substantially improves length control, primarily by specializing components in deeper model layers. Specifically, attention heads in later layers of IT models show increasingly positive contributions, particularly in English. In Italian, while attention contributions are more attenuated, final-layer MLPs exhibit a stronger positive role, suggesting a compensatory mechanism. These results indicate that instruction-tuning reconfigures later layers for task adherence, with component-level strategies potentially adapting to linguistic context.