Extracting OPQRST in Electronic Health Records using Large Language Models with Reasoning
作者: Zhimeng Luo, Abhibha Gupta, Adam Frisch, Daqing He
分类: cs.CL, cs.AI
发布日期: 2025-09-02
💡 一句话要点
提出基于LLM的推理方法,用于从电子病历中提取OPQRST信息,提升临床决策效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电子病历 信息抽取 大型语言模型 文本生成 临床决策支持
📋 核心要点
- 电子病历信息抽取面临数据复杂和非结构化的挑战,传统机器学习方法难以有效捕获关键信息。
- 论文提出将信息抽取任务重构为文本生成,利用LLM进行推理,模拟医生认知过程,提高可解释性。
- 通过修改NER指标并引入语义相似度量,更准确地评估生成文本的临床相关性,提升信息抽取的准确性和可用性。
📝 摘要(中文)
由于电子病历(EHRs)数据的复杂性和非结构化特性,从中提取关键患者信息面临巨大挑战。传统的机器学习方法通常无法有效捕获相关细节,使得临床医生难以在患者护理中有效利用这些工具。本文提出了一种新方法,利用大型语言模型(LLMs)的能力从EHRs中提取OPQRST评估信息。我们将任务从序列标注重新定义为文本生成,使模型能够提供模仿医生认知过程的推理步骤,从而增强可解释性并适应医疗环境中标记数据有限的挑战。此外,我们通过修改传统的命名实体识别(NER)指标,并整合BERT Score等语义相似性度量,来评估机器生成文本在临床环境中的准确性。我们的贡献展示了人工智能在医疗保健领域的显著进步,提供了一种可扩展的解决方案,提高了从EHRs中提取信息的准确性和可用性,从而帮助临床医生做出更明智的决策并改善患者护理结果。
🔬 方法详解
问题定义:论文旨在解决从电子病历(EHRs)中准确、高效地提取OPQRST(Onset, Provocation, Quality, Radiation, Severity, Time)评估信息的问题。现有方法,特别是传统的机器学习方法,难以有效处理EHRs中数据的复杂性和非结构化特性,导致信息抽取准确率低,可解释性差,难以满足临床医生的实际需求。
核心思路:论文的核心思路是将OPQRST信息抽取任务从传统的序列标注问题重新定义为文本生成问题。通过利用大型语言模型(LLMs)的强大生成能力和推理能力,模型可以生成类似于医生进行临床评估时的推理过程,从而更准确地提取相关信息。这种方法不仅提高了准确率,还增强了模型的可解释性。
技术框架:该方法主要包含以下几个阶段:1) 数据预处理:对EHRs文本数据进行清洗和标准化处理。2) 模型构建:使用预训练的大型语言模型(LLMs),并针对OPQRST信息抽取任务进行微调。3) 文本生成:利用微调后的LLM,根据EHRs文本生成包含OPQRST信息的文本描述。4) 评估:使用改进的NER指标和语义相似度量(如BERT Score)评估生成文本的准确性和临床相关性。
关键创新:论文最重要的技术创新点在于将信息抽取任务转化为文本生成任务,并利用LLM的推理能力模拟医生的认知过程。此外,针对临床文本的特殊性,论文还提出了改进的评估指标,能够更准确地评估生成文本的质量。
关键设计:论文的关键设计包括:1) 选择合适的预训练LLM,并进行针对性的微调。2) 设计合适的prompt,引导LLM生成包含OPQRST信息的文本。3) 改进传统的NER评估指标,引入语义相似度量,更准确地评估生成文本的临床相关性。具体的参数设置、损失函数和网络结构等细节在论文中可能未详细说明,属于未知信息。
🖼️ 关键图片
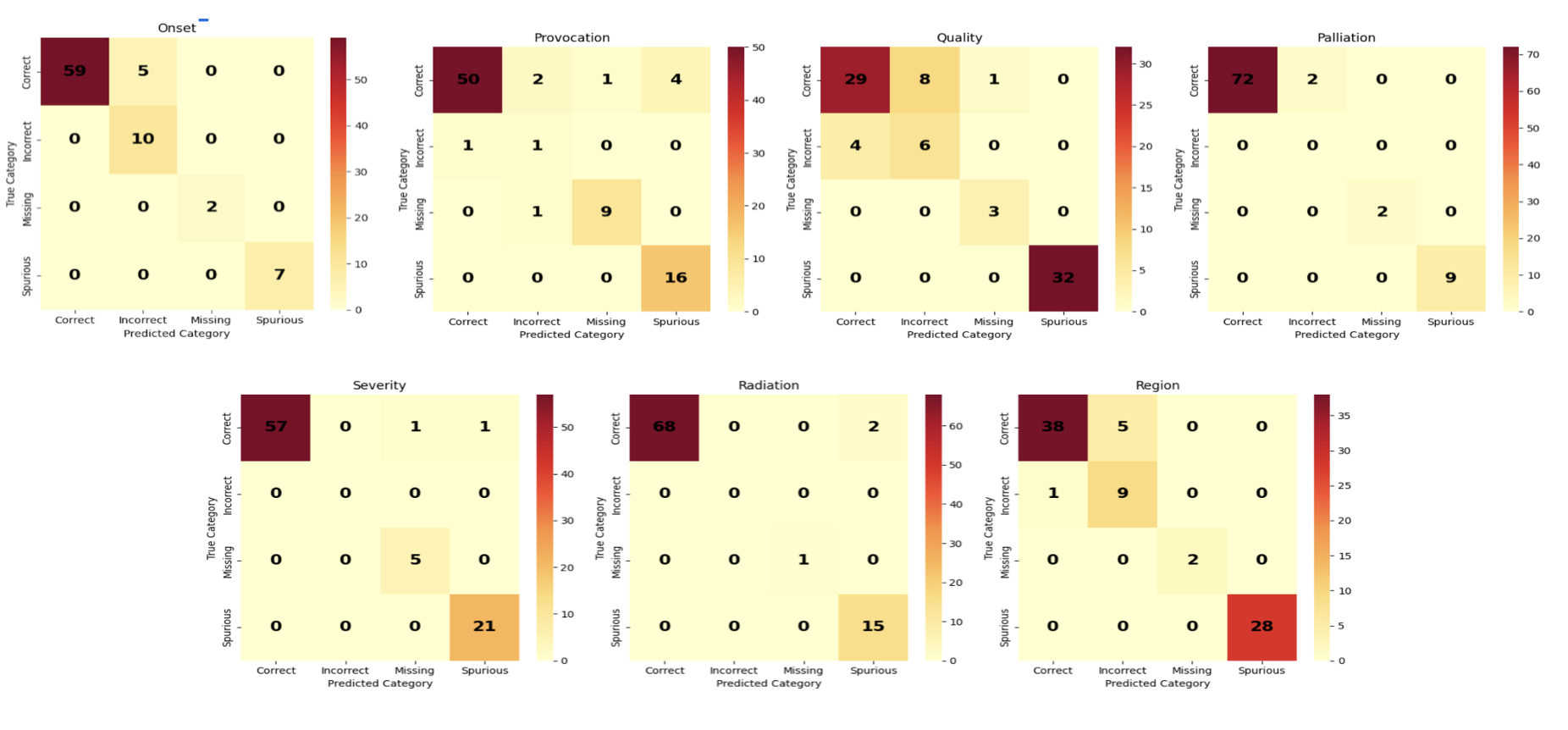

📊 实验亮点
论文通过实验验证了所提出方法的有效性,但具体的性能数据、对比基线和提升幅度等信息在摘要中未明确给出,属于未知信息。摘要强调该方法提高了信息抽取的准确性和可用性,并能辅助临床医生做出更明智的决策。
🎯 应用场景
该研究成果可广泛应用于临床决策支持系统,辅助医生快速准确地获取患者的关键信息,提高诊断效率和治疗效果。此外,该方法还可用于构建智能化的电子病历管理系统,提升医疗服务的质量和效率,并为医学研究提供更丰富的数据资源。未来,该技术有望扩展到其他医疗信息抽取任务,例如药物不良反应监测、疾病风险预测等。
📄 摘要(原文)
The extraction of critical patient information from Electronic Health Records (EHRs) poses significant challenges due to the complexity and unstructured nature of the data. Traditional machine learning approaches often fail to capture pertinent details efficiently, making it difficult for clinicians to utilize these tools effectively in patient care. This paper introduces a novel approach to extracting the OPQRST assessment from EHRs by leveraging the capabilities of Large Language Models (LLMs). We propose to reframe the task from sequence labeling to text generation, enabling the models to provide reasoning steps that mimic a physician's cognitive processes. This approach enhances interpretability and adapts to the limited availability of labeled data in healthcare settings. Furthermore, we address the challenge of evaluating the accuracy of machine-generated text in clinical contexts by proposing a modification to traditional Named Entity Recognition (NER) metrics. This includes the integration of semantic similarity measures, such as the BERT Score, to assess the alignment between generated text and the clinical intent of the original records. Our contributions demonstrate a significant advancement in the use of AI in healthcare, offering a scalable solution that improves the accuracy and usability of information extraction from EHRs, thereby aiding clinicians in making more informed decisions and enhancing patient care outcomes.