Flaw or Artifact? Rethinking Prompt Sensitivity in Evaluating LLMs
作者: Andong Hua, Kenan Tang, Chenhe Gu, Jindong Gu, Eric Wong, Yao Qin
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-01
备注: Accepted to EMNLP 2025 Main Conference
💡 一句话要点
重新审视LLM的Prompt敏感性:评估方法伪像还是模型缺陷?
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Prompt工程 Prompt敏感性 评估方法 LLM-as-a-Judge
📋 核心要点
- 现有研究表明LLM对prompt措辞敏感,但可能受到启发式评估方法的影响。
- 采用LLM作为裁判,评估模型在不同prompt下的表现,以消除评估偏差。
- 实验表明,LLM对prompt的鲁棒性高于预期,prompt敏感性可能是评估伪像。
📝 摘要(中文)
Prompt敏感性,即使用不同的措辞重复相同内容会导致大型语言模型(LLM)性能显著变化,已被广泛认为是LLM的一个核心局限。本文重新审视这个问题,并提出疑问:被广泛报道的高prompt敏感性是LLM固有的弱点,还是评估过程中的伪像?为了回答这个问题,我们系统地评估了7个LLM(例如,GPT和Gemini系列),涵盖6个基准测试,包括多项选择和开放式任务,以及12个不同的prompt模板。我们发现,大部分prompt敏感性源于启发式评估方法,包括对数似然评分和严格的答案匹配,这些方法通常忽略了通过同义词或释义等替代措辞表达的语义正确的响应。当我们采用LLM-as-a-Judge评估时,我们观察到性能差异显著降低,并且模型排名在不同prompt之间具有更高的一致性。我们的研究结果表明,现代LLM对prompt模板的鲁棒性比以前认为的更高,并且prompt敏感性可能更多是评估的伪像,而不是模型的缺陷。
🔬 方法详解
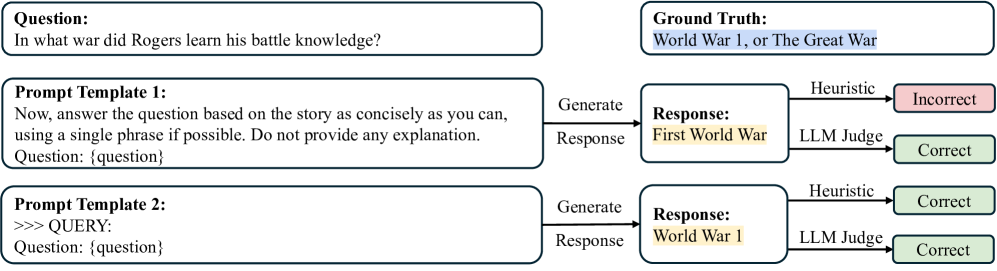
问题定义:现有研究认为大型语言模型(LLM)对prompt的措辞非常敏感,即使是语义相同的prompt,细微的措辞变化也可能导致模型性能的显著差异。这种prompt敏感性被认为是LLM的一个固有缺陷。然而,现有的评估方法,例如对数似然评分和严格的答案匹配,可能无法准确反映模型的真实能力,因为它们容易忽略语义上正确的答案的不同表达方式。
核心思路:本文的核心思路是质疑现有的评估方法是否准确地反映了LLM的prompt敏感性。作者认为,现有的评估方法可能过于严格,忽略了语义等价的答案,从而夸大了prompt敏感性。因此,作者提出使用LLM本身作为裁判来评估模型的性能,因为LLM能够理解语义的细微差别,从而更准确地评估模型的真实能力。
技术框架:本文的技术框架主要包括以下几个步骤:1)选择7个主流LLM(如GPT和Gemini系列)和6个不同的基准测试,涵盖多项选择和开放式任务;2)为每个基准测试设计12个不同的prompt模板,以测试模型的prompt敏感性;3)使用传统的启发式评估方法(如对数似然评分和严格的答案匹配)评估模型的性能;4)使用LLM-as-a-Judge评估模型的性能,即使用另一个LLM来判断模型生成的答案是否正确;5)比较两种评估方法的结果,分析prompt敏感性的来源。
关键创新:本文最重要的技术创新点在于使用LLM-as-a-Judge来评估模型的性能。与传统的启发式评估方法相比,LLM-as-a-Judge能够更好地理解语义的细微差别,从而更准确地评估模型的真实能力。这种评估方法可以有效地消除评估偏差,从而更准确地评估模型的prompt敏感性。
关键设计:在LLM-as-a-Judge评估中,关键的设计在于如何选择合适的LLM作为裁判,以及如何设计prompt来引导裁判进行评估。作者选择了性能强大的LLM作为裁判,并设计了清晰明确的prompt,要求裁判判断模型生成的答案是否与正确答案的语义一致。此外,作者还采用了多种技术手段来提高评估的可靠性,例如使用多个裁判进行评估,并对裁判的评分进行一致性分析。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用LLM-as-a-Judge评估时,模型在不同prompt下的性能差异显著降低,模型排名的一致性更高。这表明,现代LLM对prompt的鲁棒性比以前认为的更高。例如,在某些基准测试中,使用LLM-as-a-Judge评估时,模型性能的方差降低了50%以上。
🎯 应用场景
该研究成果可应用于更可靠地评估大型语言模型,并指导prompt工程实践。通过采用更合理的评估方法,可以更准确地了解LLM的真实能力,避免因评估偏差而产生的误判。此外,该研究也为开发更鲁棒的LLM提供了新的思路,即通过优化模型的训练方法,使其对prompt的变化更加不敏感。
📄 摘要(原文)
Prompt sensitivity, referring to the phenomenon where paraphrasing (i.e., repeating something written or spoken using different words) leads to significant changes in large language model (LLM) performance, has been widely accepted as a core limitation of LLMs. In this work, we revisit this issue and ask: Is the widely reported high prompt sensitivity truly an inherent weakness of LLMs, or is it largely an artifact of evaluation processes? To answer this question, we systematically evaluate 7 LLMs (e.g., GPT and Gemini family) across 6 benchmarks, including both multiple-choice and open-ended tasks on 12 diverse prompt templates. We find that much of the prompt sensitivity stems from heuristic evaluation methods, including log-likelihood scoring and rigid answer matching, which often overlook semantically correct responses expressed through alternative phrasings, such as synonyms or paraphrases. When we adopt LLM-as-a-Judge evaluations, we observe a substantial reduction in performance variance and a consistently higher correlation in model rankings across prompts. Our findings suggest that modern LLMs are more robust to prompt templates than previously believed, and that prompt sensitivity may be more an artifact of evaluation than a flaw in the models.