Enhancing Uncertainty Estimation in LLMs with Expectation of Aggregated Internal Belief
作者: Zeguan Xiao, Diyang Dou, Boya Xiong, Yun Chen, Guanhua Chen
分类: cs.CL
发布日期: 2025-09-01 (更新: 2025-12-23)
备注: Accepted by AAAI 2026
💡 一句话要点
EAGLE:利用LLM内部信念聚合期望提升不确定性估计
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性估计 置信度校准 自我评估 内部信念聚合
📋 核心要点
- 现有LLM存在过度自信问题,尤其是在RLHF训练后,导致不准确的置信度估计。
- EAGLE通过聚合LLM中间层的内部信念,并计算期望,得到更准确的置信度分数。
- 实验表明,EAGLE在多个数据集和LLM上显著提升了校准性能,优于现有方法。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言任务中取得了显著成功,但常常表现出过度自信,并生成看似合理但不正确的答案。这种过度自信,尤其是在经过人类反馈强化学习(RLHF)的模型中,对可靠的不确定性估计和安全部署构成了重大挑战。本文提出EAGLE(AGgregated internaL bEief的期望),一种新颖的基于自我评估的校准方法,它利用LLMs的内部隐藏状态来导出更准确的置信度分数。我们的方法不是依赖于模型的最终输出,而是从自我评估期间的多个中间层提取内部信念。通过聚合这些层级的信念并计算所得置信度分数分布的期望,EAGLE产生一个更真实地反映模型内部确定性的精细置信度分数。在不同的数据集和LLMs上的大量实验表明,EAGLE显著提高了优于现有基线的校准性能。我们还提供了对EAGLE的深入分析,包括对不确定性模式的逐层检查、对自我评估提示影响的研究以及对自我评估分数范围影响的分析。
🔬 方法详解
问题定义:大型语言模型(LLMs)在生成文本时常常表现出过度自信,即使在给出错误答案时也如此。这种不准确的置信度估计会严重影响LLM在安全关键型应用中的可靠性。现有方法主要依赖于模型最终输出的概率分布来估计不确定性,但这些方法往往无法准确反映模型内部的真实信念状态。
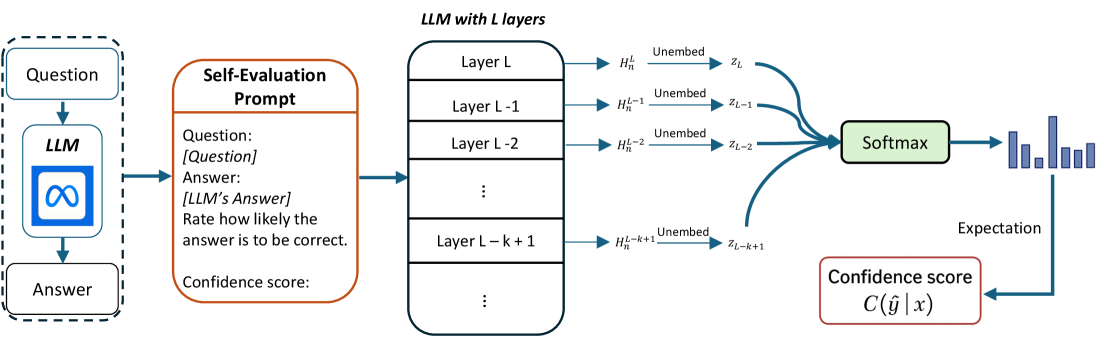
核心思路:EAGLE的核心思想是,LLM在生成答案的过程中,其内部的多个中间层都蕴含着关于答案正确性的信念。通过聚合这些来自不同层的信念,并计算其期望,可以得到一个更准确、更可靠的置信度分数。这种方法避免了仅仅依赖最终输出的局限性,从而更好地反映了模型内部的真实不确定性。
技术框架:EAGLE方法主要包含以下几个阶段:1) 自我评估提示:使用特定的提示语引导LLM对自身生成的答案进行评估。2) 中间层信念提取:从LLM的多个中间层提取隐藏状态,并将这些隐藏状态视为模型在不同阶段对答案的信念。3) 信念聚合:将来自不同层的信念进行聚合,例如通过加权平均或更复杂的神经网络。4) 期望计算:计算聚合后的信念分布的期望,得到最终的置信度分数。
关键创新:EAGLE最重要的创新点在于其利用了LLM内部多个中间层的信念信息,而不是仅仅依赖于最终输出。这种方法能够更全面地捕捉模型在生成答案过程中的不确定性,从而提高置信度估计的准确性。与现有方法相比,EAGLE更深入地挖掘了LLM内部的信息,并将其用于不确定性估计。
关键设计:EAGLE的关键设计包括:1) 层选择策略:选择哪些中间层进行信念提取,这会影响最终的置信度估计。论文可能探索了不同的层选择策略,例如均匀选择、基于重要性的选择等。2) 信念聚合方法:如何将来自不同层的信念进行聚合,例如使用简单的加权平均或训练一个专门的聚合网络。3) 自我评估提示设计:设计什么样的提示语能够更有效地引导LLM进行自我评估,并提取出更准确的信念信息。4) 期望计算方法:使用何种方法计算聚合后信念分布的期望,例如直接计算均值或使用蒙特卡洛采样。
🖼️ 关键图片
📊 实验亮点
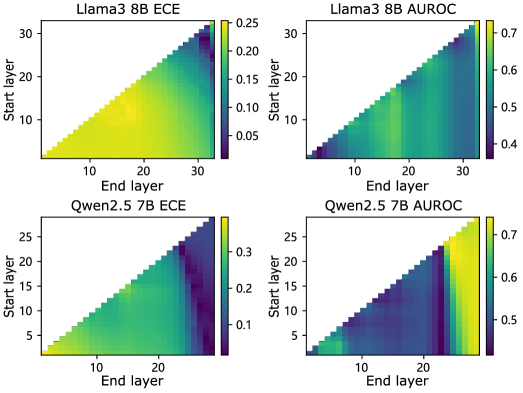
实验结果表明,EAGLE在多个数据集和LLM上显著提高了校准性能。例如,在某些数据集上,EAGLE可以将Expected Calibration Error (ECE) 降低 20% 以上,显著优于现有的温度缩放等基线方法。此外,论文还对EAGLE进行了深入分析,包括层级不确定性模式、自我评估提示的影响以及自我评估分数范围的影响。
🎯 应用场景
EAGLE方法可以应用于各种需要可靠不确定性估计的LLM应用场景,例如:医疗诊断、金融风险评估、自动驾驶等。通过提高LLM的置信度校准,可以减少模型在关键决策中的错误,提高系统的安全性和可靠性。此外,EAGLE还可以用于提升LLM的可解释性,帮助用户更好地理解模型的决策过程。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable success across a wide range of natural language tasks, but often exhibit overconfidence and generate plausible yet incorrect answers. This overconfidence, especially in models undergone Reinforcement Learning from Human Feedback (RLHF), poses significant challenges for reliable uncertainty estimation and safe deployment. In this paper, we propose EAGLE (Expectation of AGgregated internaL bEief), a novel self-evaluation-based calibration method that leverages the internal hidden states of LLMs to derive more accurate confidence scores. Instead of relying on the model's final output, our approach extracts internal beliefs from multiple intermediate layers during self-evaluation. By aggregating these layer-wise beliefs and calculating the expectation over the resulting confidence score distribution, EAGLE produces a refined confidence score that more faithfully reflects the model's internal certainty. Extensive experiments on diverse datasets and LLMs demonstrate that EAGLE significantly improves calibration performance over existing baselines. We also provide an in-depth analysis of EAGLE, including a layer-wise examination of uncertainty patterns, a study of the impact of self-evaluation prompts, and an analysis of the effect of self-evaluation score range.