CAT: Causal Attention Tuning For Injecting Fine-grained Causal Knowledge into Large Language Models
作者: Kairong Han, Wenshuo Zhao, Ziyu Zhao, JunJian Ye, Lujia Pan, Kun Kuang
分类: cs.CL, cs.AI
发布日期: 2025-09-01 (更新: 2025-09-09)
备注: Accepted to EMNLP2025 Main conference
🔗 代码/项目: GITHUB
💡 一句话要点
提出因果注意力调整(CAT)方法,将细粒度因果知识注入大型语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果推理 大型语言模型 注意力机制 分布外泛化 因果知识注入
📋 核心要点
- 现有LLM易捕获虚假相关性,导致在分布外场景表现不佳,无法有效利用因果知识。
- CAT方法通过注入细粒度因果知识到注意力机制,引导模型关注因果结构,减轻噪声和偏差。
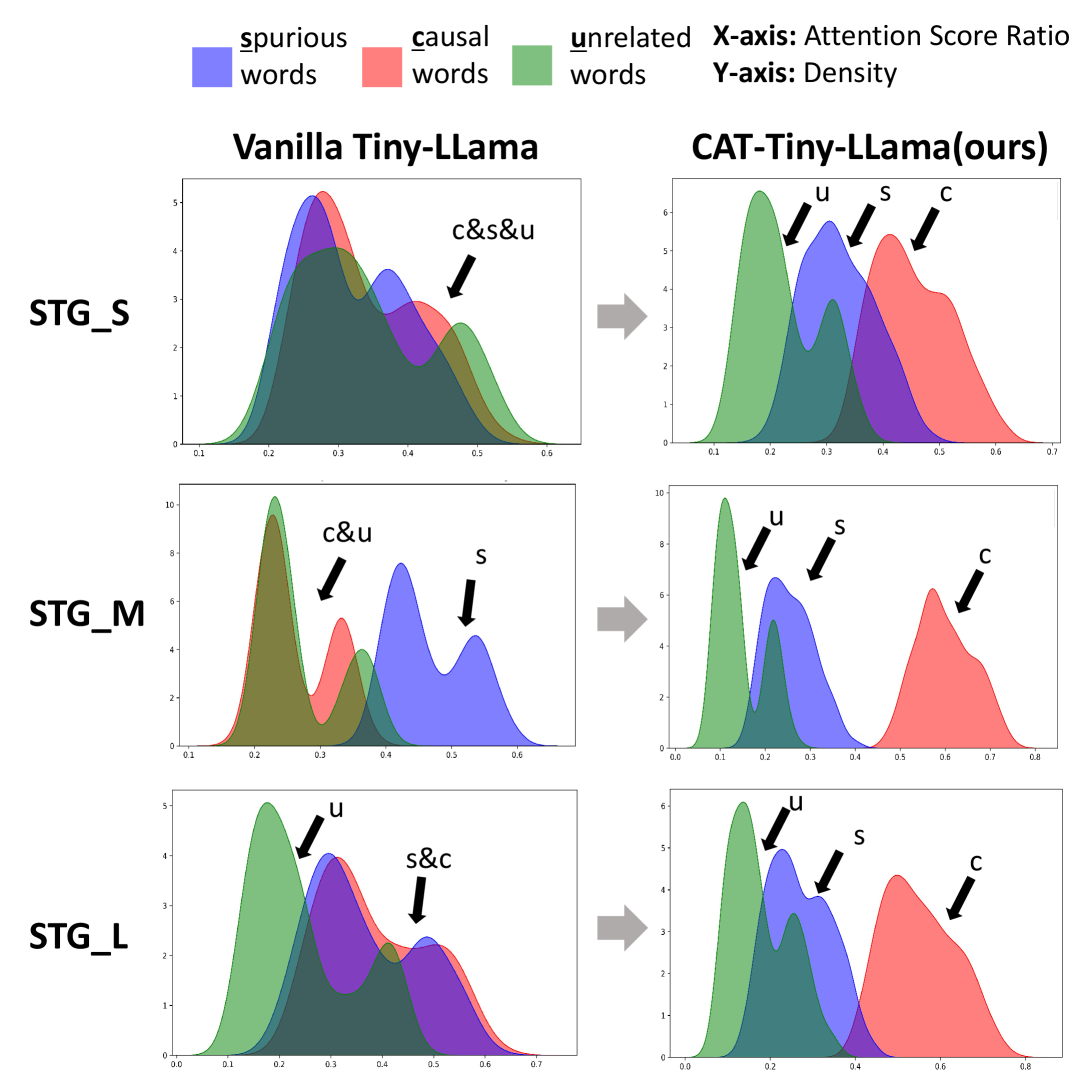
- 实验表明,CAT在STG和下游任务上均有显著提升,尤其在分布外场景中表现出更强的鲁棒性。
📝 摘要(中文)
大型语言模型(LLMs)在各个领域取得了显著成功。然而,一个根本问题仍然存在:LLMs能否有效地利用因果知识进行预测和生成?通过实证研究,我们发现直接在大型数据集上训练的LLMs通常捕获的是虚假相关性,而不是真实的因果关系,导致次优的性能,尤其是在分布外(OOD)场景中。为了解决这个挑战,我们提出了一种新颖的方法,即因果注意力调整(CAT),将细粒度的因果知识注入到注意力机制中。我们提出了一个自动化的流程,利用人类先验知识自动生成token级别的因果信号,并引入了Re-Attention机制来指导训练,帮助模型关注因果结构,同时减轻注意力分数中的噪声和偏差。在我们提出的Spurious Token Game(STG)基准测试和多个下游任务上的实验结果表明,我们的方法有效地利用了因果知识进行预测,并在OOD场景中保持了鲁棒性。CAT在STG数据集上平均提高了5.76%,在下游任务上平均提高了1.56%。值得注意的是,Llama-3.1-8B模型在STG_M上的OOD性能从64.5%提高到90.5%,Qwen在STG_H数据集上的OOD性能从25.4%提高到55.9%。
🔬 方法详解
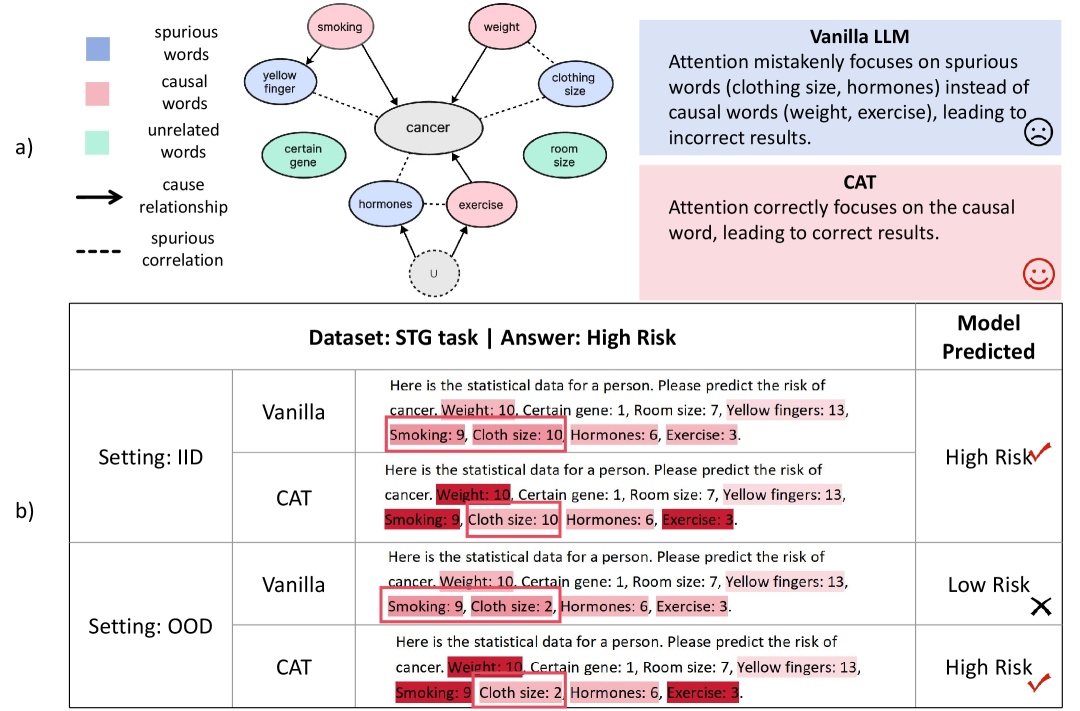
问题定义:大型语言模型在处理因果推理任务时,容易受到训练数据中虚假相关性的影响,导致模型在分布外(OOD)场景下的泛化能力较差。现有的方法难以有效地将因果知识融入到模型的学习过程中,使得模型无法区分因果关系和相关关系。
核心思路:CAT的核心思路是通过调整注意力机制,使模型更加关注token级别的因果关系,从而提高模型在因果推理任务中的性能和鲁棒性。该方法利用人类先验知识自动生成因果信号,并使用Re-Attention机制引导模型学习,以减轻噪声和偏差的影响。
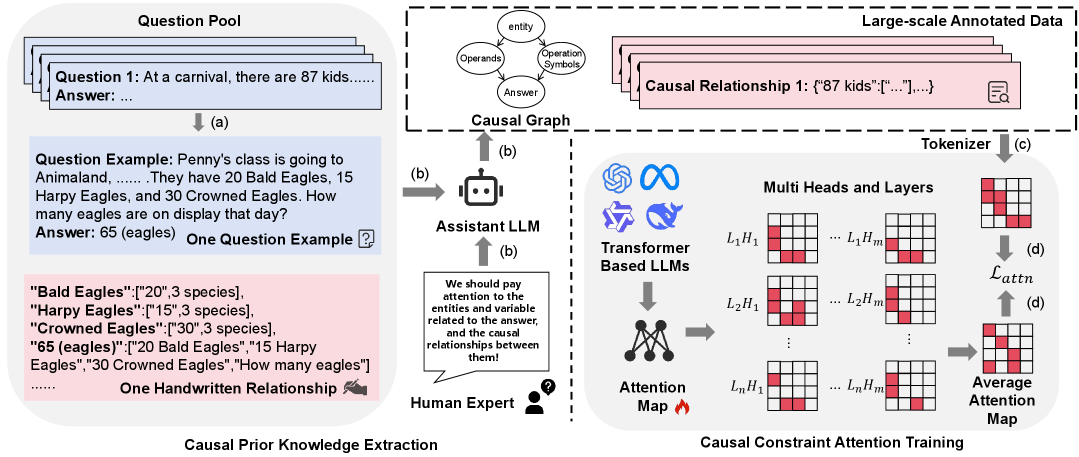
技术框架:CAT方法包含以下几个主要步骤:1) 因果信号生成:利用人类先验知识,自动生成token级别的因果信号,用于指导模型的训练。2) Re-Attention机制:引入Re-Attention机制,将因果信号融入到注意力机制中,引导模型关注因果结构。3) 模型训练:使用带有因果信号的Re-Attention机制训练大型语言模型。4) 评估:在Spurious Token Game(STG)基准测试和多个下游任务上评估模型的性能。
关键创新:CAT方法的关键创新在于:1) 细粒度的因果知识注入:将因果知识注入到token级别的注意力机制中,使得模型能够更加精细地理解因果关系。2) 自动化的因果信号生成:利用人类先验知识自动生成因果信号,避免了手动标注的成本和偏差。3) Re-Attention机制:通过Re-Attention机制,有效地将因果信号融入到注意力机制中,引导模型学习。
关键设计:CAT方法的关键设计包括:1) 因果信号的表示:使用向量表示token级别的因果信号,并将其融入到注意力机制中。2) Re-Attention的计算方式:通过对原始注意力分数进行加权和调整,使得模型更加关注因果相关的token。3) 损失函数的设计:设计合适的损失函数,以鼓励模型学习因果关系,并减轻噪声和偏差的影响。具体的参数设置和网络结构细节可以在论文的实现代码中找到。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CAT方法在Spurious Token Game(STG)基准测试和多个下游任务上均取得了显著的性能提升。例如,在STG数据集上,CAT方法平均提高了5.76%,在下游任务上平均提高了1.56%。更重要的是,CAT方法显著提高了模型在分布外(OOD)场景下的鲁棒性。Llama-3.1-8B模型在STG_M上的OOD性能从64.5%提高到90.5%,Qwen在STG_H数据集上的OOD性能从25.4%提高到55.9%。
🎯 应用场景
该研究成果可应用于各种需要因果推理的场景,例如医疗诊断、金融风险评估、政策制定等。通过提高LLM的因果推理能力,可以帮助人们做出更明智的决策,并减少因果混淆带来的负面影响。未来,该方法可以进一步扩展到其他类型的模型和任务中,以提高人工智能系统的可靠性和可解释性。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable success across various domains. However, a fundamental question remains: Can LLMs effectively utilize causal knowledge for prediction and generation? Through empirical studies, we find that LLMs trained directly on large-scale data often capture spurious correlations rather than true causal relationships, leading to suboptimal performance, especially in out-of-distribution (OOD) scenarios. To address this challenge, we propose Causal Attention Tuning (CAT), a novel approach that injects fine-grained causal knowledge into the attention mechanism. We propose an automated pipeline that leverages human priors to automatically generate token-level causal signals and introduce the Re-Attention mechanism to guide training, helping the model focus on causal structures while mitigating noise and biases in attention scores. Experimental results on our proposed Spurious Token Game (STG) benchmark and multiple downstream tasks demonstrate that our approach effectively leverages causal knowledge for prediction and remains robust in OOD scenarios. The CAT achieves an average improvement of 5.76% on the STG dataset and 1.56% on downstream tasks. Notably, the OOD performance of the Llama-3.1-8B model on STG_M increased from 64.5% to 90.5%, and Qwen's OOD performance on the STG_H dataset improved from 25.4% to 55.9%. Implementation details can be found at https://github.com/Kairong-Han/CAT.