Trusted Uncertainty in Large Language Models: A Unified Framework for Confidence Calibration and Risk-Controlled Refusal
作者: Markus Oehri, Giulia Conti, Kaviraj Pather, Alexandre Rossi, Laia Serra, Adrian Parody, Rogvi Johannesen, Aviaja Petersen, Arben Krasniqi
分类: cs.CL
发布日期: 2025-09-01 (更新: 2025-12-29)
备注: 10 pages, 5 figures
💡 一句话要点
提出UniCR框架,通过校准不确定性证据实现大语言模型风险可控的拒绝回答。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 不确定性量化 置信度校准 风险控制 拒绝回答 共形预测 长文本生成
📋 核心要点
- 现有大语言模型缺乏有效的不确定性量化方法,难以判断何时应该拒绝回答。
- UniCR框架融合多种不确定性证据,校准为置信度,并根据用户设定的风险预算进行拒绝回答。
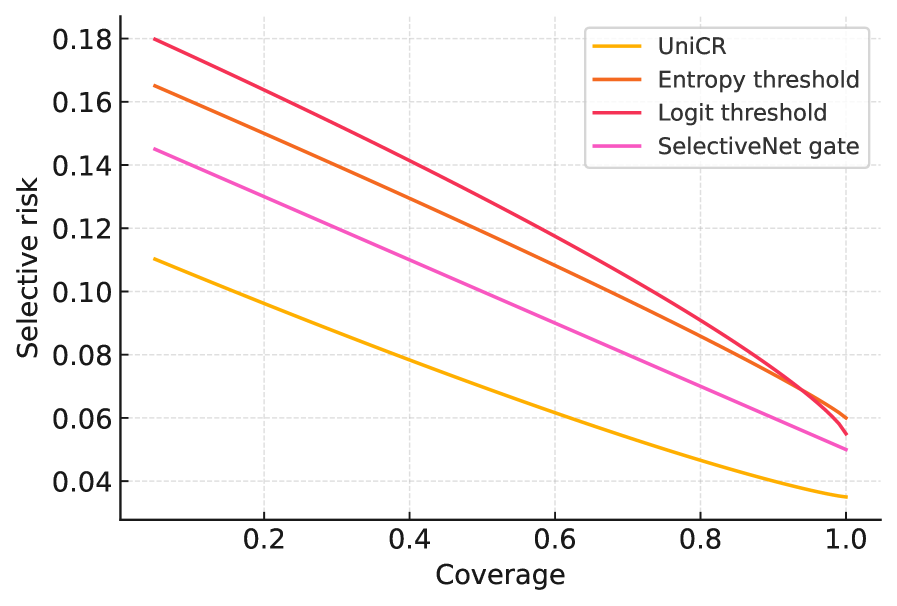
- 实验表明,UniCR在多个任务上提升了校准性能,降低了风险-覆盖率曲线,提高了固定风险下的覆盖率。
📝 摘要(中文)
本文提出UniCR,一个统一的框架,它将异构的不确定性证据(包括序列似然、自洽性差异、检索兼容性以及工具或验证器反馈)转化为校准后的正确概率,并通过原则性的拒绝回答来强制执行用户指定的误差预算。UniCR学习一个轻量级的校准头,采用温度缩放和适当的评分方法,通过黑盒特征支持仅API模型,并使用共形风险控制提供无分布保证。对于长文本生成,我们通过监督从检索证据中获得的原子事实性分数,将置信度与语义保真度对齐,从而减少自信的幻觉,同时保持覆盖率。在短文本问答、代码生成(带有执行测试)和检索增强的长文本问答上的实验表明,与熵或logit阈值、事后校准器和端到端选择性基线相比,在校准指标上有一致的改进,风险-覆盖率曲线下的面积更小,并且在固定风险下覆盖率更高。分析表明,证据矛盾、语义差异和工具不一致是拒绝回答的主要驱动因素,从而产生信息丰富的面向用户的拒绝消息。最终结果是一个可移植的配方,将证据融合到校准概率,再到风险控制的决策,从而提高可信度,而无需微调基础模型,并且在分布偏移下仍然有效。
🔬 方法详解
问题定义:大语言模型在实际部署中,不仅需要生成答案,更需要判断何时不应该回答,即进行风险可控的拒绝回答。现有方法通常依赖于简单的阈值判断,或者事后校准,无法有效利用多种不确定性证据,且难以保证在分布偏移下的性能。
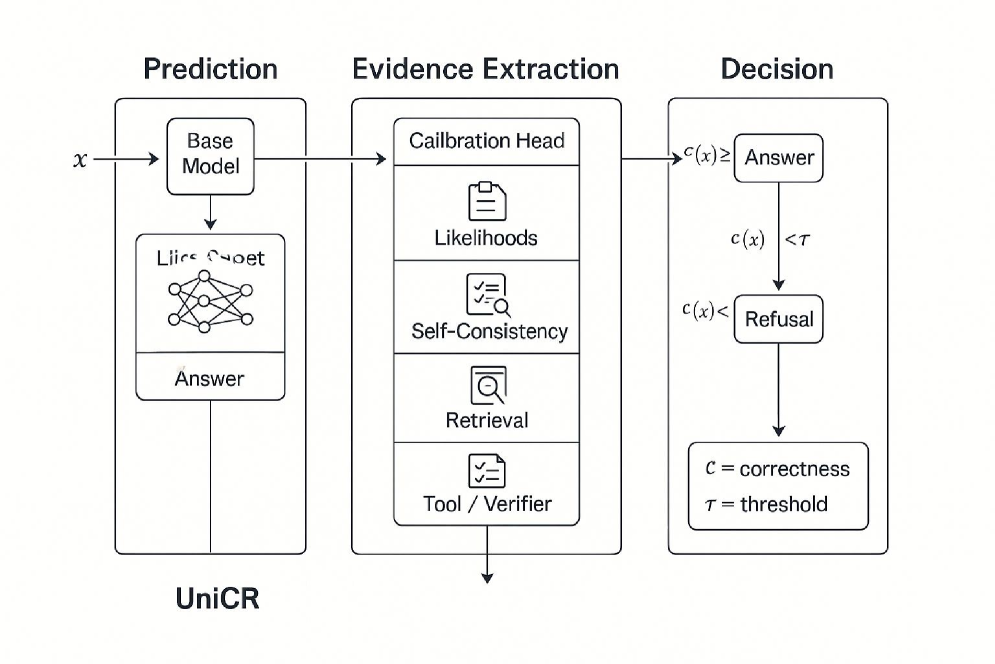
核心思路:UniCR的核心思路是将多种异构的不确定性证据(如序列似然、自洽性、检索兼容性等)融合起来,通过一个轻量级的校准头,将其转化为校准后的正确概率。然后,根据用户设定的风险预算,利用共形风险控制方法,决定何时拒绝回答。这样可以在保证风险的前提下,尽可能提高覆盖率。
技术框架:UniCR框架主要包含以下几个模块:1) 不确定性证据提取:从模型输出、检索结果、工具反馈等来源提取多种不确定性证据。2) 校准头学习:学习一个轻量级的校准头,将异构的证据融合为校准后的置信度。校准头采用温度缩放和适当的评分方法。3) 风险控制:利用共形风险控制方法,根据用户设定的风险预算,决定何时拒绝回答。
关键创新:UniCR的关键创新在于:1) 统一的框架:能够融合多种异构的不确定性证据,并将其转化为校准后的置信度。2) 轻量级的校准头:无需微调基础模型,即可实现有效的校准。3) 共形风险控制:提供无分布保证,即使在分布偏移下也能保持性能。
关键设计:校准头采用温度缩放和适当的评分方法,损失函数包括校准损失和覆盖率损失。共形风险控制方法利用历史数据估计风险,并根据用户设定的风险预算,动态调整拒绝回答的阈值。对于长文本生成,使用原子事实性分数作为监督信号,以对齐置信度与语义保真度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,UniCR在短文本问答、代码生成和检索增强的长文本问答等任务上,相比于现有方法,在校准指标上有一致的改进,风险-覆盖率曲线下的面积更小,并且在固定风险下覆盖率更高。例如,在长文本问答任务中,UniCR能够有效减少自信的幻觉,同时保持较高的覆盖率。
🎯 应用场景
UniCR框架可应用于各种需要高可靠性的大语言模型应用场景,例如医疗诊断、金融风控、法律咨询等。通过风险可控的拒绝回答,可以避免模型在不确定情况下给出错误答案,从而提高系统的整体安全性与可信度。该框架还可用于提升代码生成工具的可靠性,以及改进检索增强的问答系统。
📄 摘要(原文)
Deployed language models must decide not only what to answer but also when not to answer. We present UniCR, a unified framework that turns heterogeneous uncertainty evidence including sequence likelihoods, self-consistency dispersion, retrieval compatibility, and tool or verifier feedback into a calibrated probability of correctness and then enforces a user-specified error budget via principled refusal. UniCR learns a lightweight calibration head with temperature scaling and proper scoring, supports API-only models through black-box features, and offers distribution-free guarantees using conformal risk control. For long-form generation, we align confidence with semantic fidelity by supervising on atomic factuality scores derived from retrieved evidence, reducing confident hallucinations while preserving coverage. Experiments on short-form QA, code generation with execution tests, and retrieval-augmented long-form QA show consistent improvements in calibration metrics, lower area under the risk-coverage curve, and higher coverage at fixed risk compared to entropy or logit thresholds, post-hoc calibrators, and end-to-end selective baselines. Analyses reveal that evidence contradiction, semantic dispersion, and tool inconsistency are the dominant drivers of abstention, yielding informative user-facing refusal messages. The result is a portable recipe of evidence fusion to calibrated probability to risk-controlled decision that improves trustworthiness without fine-tuning the base model and remains valid under distribution shift.