On the Alignment of Large Language Models with Global Human Opinion
作者: Yang Liu, Masahiro Kaneko, Chenhui Chu
分类: cs.CL
发布日期: 2025-09-01 (更新: 2025-11-19)
备注: 28 pages, 26 figures
💡 一句话要点
提出基于世界价值观调查的框架,评估大语言模型与全球人类意见的对齐程度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 意见对齐 世界价值观调查 多语言 文化敏感性 提示工程 全球化 价值观
📋 核心要点
- 现有研究缺乏对大语言模型在全球范围内与不同国家、历史时期人类意见对齐情况的系统评估,忽略了语言在引导模型意见中的作用。
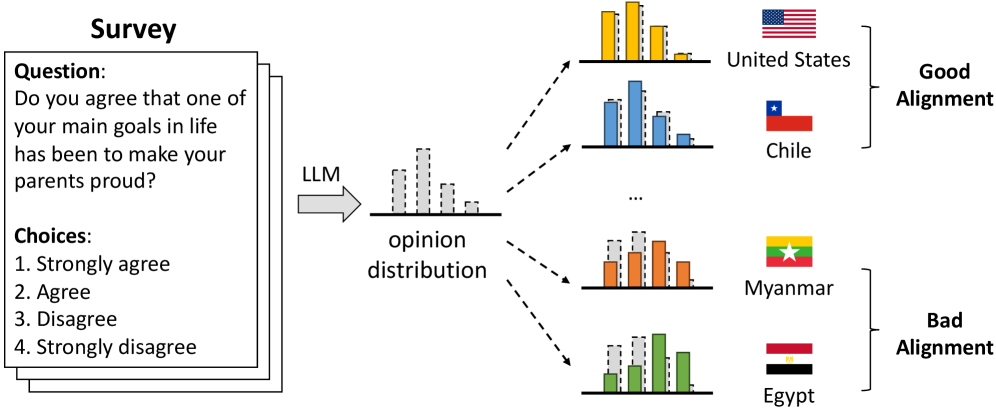
- 论文提出基于世界价值观调查(WVS)的评估框架,通过改变提示语言来引导LLMs与特定国家或历史时期的意见对齐。
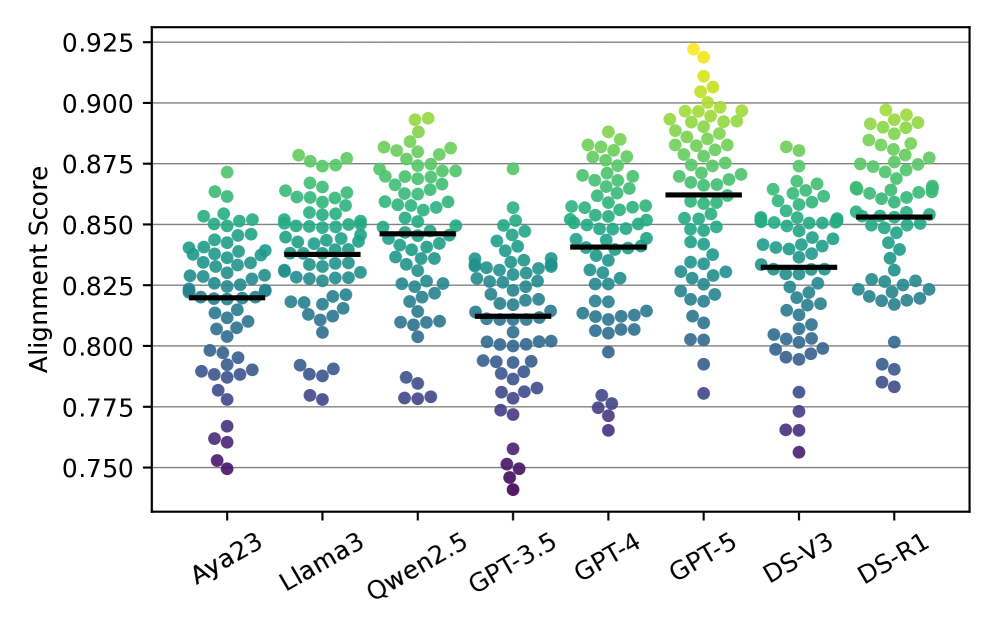
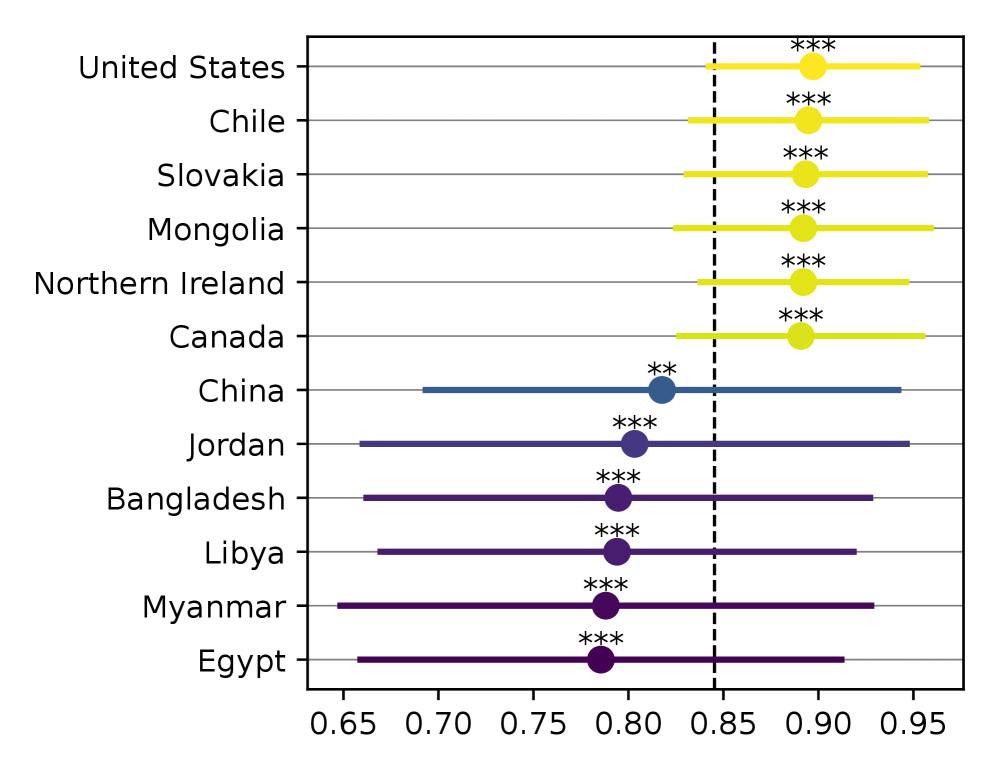
- 实验表明,LLMs对少数国家意见过度对齐,对多数国家对齐不足;使用目标国家语言的提示能有效提升意见对齐效果。
📝 摘要(中文)
目前的大语言模型(LLMs)能够支持多语言场景,允许用户以母语与LLMs交互。当LLMs回答用户提出的主观问题时,它们应该与特定人口群体或历史时期的观点保持一致,而这些观点受到用户与模型交互所用语言的影响。现有的研究主要集中于研究LLMs在美国或少数几个国家的人口群体中所代表的观点,缺乏全球范围内的国家样本以及对不同历史时期人类观点的研究,也缺乏对使用语言引导LLMs的讨论。此外,他们也忽略了提示语言对LLMs意见对齐的潜在影响。在本研究中,我们的目标是填补这些空白。为此,我们创建了一个基于世界价值观调查(WVS)的评估框架,以系统地评估LLMs与全球不同国家、语言和历史时期的人类意见的对齐程度。我们发现,LLMs仅与少数几个国家的意见适当或过度对齐,而与大多数国家的意见对齐不足。此外,将提示的语言更改为与问卷中使用的语言相匹配,可以比现有的引导方法更有效地引导LLMs与相应国家的意见对齐。同时,LLMs更倾向于与当代人口的意见对齐。据我们所知,我们的研究是首次对LLMs中跨全球、语言和时间维度上的意见对齐主题进行全面调查。我们的代码和数据可在https://github.com/ku-nlp/global-opinion-alignment和https://github.com/nlply/global-opinion-alignment公开获取。
🔬 方法详解
问题定义:现有研究主要关注LLMs在美国等少数国家的人群意见对齐,缺乏全球视角和历史维度的考察。同时,忽略了prompt语言本身对LLM输出观点的影响,导致LLM在不同文化背景下的表现不稳定,无法准确反映特定人群或历史时期的观点。
核心思路:论文的核心思路是利用世界价值观调查(WVS)提供的多国家、多语言、多时期的价值观数据,构建一个评估LLM意见对齐的框架。通过控制prompt的语言,引导LLM输出与特定国家或历史时期相符的观点,从而提升LLM的文化敏感性和观点可控性。
技术框架:该研究的技术框架主要包含以下几个阶段:1) 数据收集与处理:从世界价值观调查(WVS)中提取不同国家、不同时期的价值观数据,并进行清洗和整理。2) Prompt构建:设计包含价值观相关问题的prompt,并将其翻译成WVS中使用的多种语言。3) LLM推理:使用不同语言的prompt输入LLM,获取LLM的回答。4) 意见对齐评估:将LLM的回答与WVS中的人类意见进行比较,评估LLM的意见对齐程度。
关键创新:该研究的关键创新在于:1) 首次系统性地评估了LLM在全球范围内的意见对齐情况,弥补了现有研究的不足。2) 提出了利用prompt语言引导LLM意见对齐的方法,为提升LLM的文化敏感性和观点可控性提供了新的思路。3) 构建了基于世界价值观调查(WVS)的评估框架,为后续研究提供了可复用的工具和数据。
关键设计:关键设计包括:1) Prompt的设计:prompt需要包含明确的价值观相关问题,并确保其在不同语言之间的语义一致性。2) 意见对齐的评估指标:需要选择合适的指标来衡量LLM的回答与WVS中人类意见的相似度。3) 实验设置:需要控制实验变量,例如LLM的选择、prompt的语言、WVS数据的选择等,以确保实验结果的可靠性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLMs对少数国家意见过度对齐,对多数国家对齐不足。更重要的是,将prompt的语言更改为与WVS问卷中使用的语言相匹配,可以显著提升LLMs与相应国家意见的对齐程度,效果优于现有的引导方法。同时,LLMs更倾向于与当代人口的意见对齐。
🎯 应用场景
该研究成果可应用于开发更具文化敏感性和观点可控性的大语言模型,例如,在跨文化交流、国际关系分析、个性化推荐等领域。通过调整prompt的语言,可以使LLM更好地理解和适应不同文化背景下的用户需求,从而提供更准确、更符合用户期望的服务。此外,该研究也为评估和改进LLM的社会责任感提供了新的思路。
📄 摘要(原文)
Today's large language models (LLMs) are capable of supporting multilingual scenarios, allowing users to interact with LLMs in their native languages. When LLMs respond to subjective questions posed by users, they are expected to align with the views of specific demographic groups or historical periods, shaped by the language in which the user interacts with the model. Existing studies mainly focus on researching the opinions represented by LLMs among demographic groups in the United States or a few countries, lacking worldwide country samples and studies on human opinions in different historical periods, as well as lacking discussion on using language to steer LLMs. Moreover, they also overlook the potential influence of prompt language on the alignment of LLMs' opinions. In this study, our goal is to fill these gaps. To this end, we create an evaluation framework based on the World Values Survey (WVS) to systematically assess the alignment of LLMs with human opinions across different countries, languages, and historical periods around the world. We find that LLMs appropriately or over-align the opinions with only a few countries while under-aligning the opinions with most countries. Furthermore, changing the language of the prompt to match the language used in the questionnaire can effectively steer LLMs to align with the opinions of the corresponding country more effectively than existing steering methods. At the same time, LLMs are more aligned with the opinions of the contemporary population. To our knowledge, our study is the first comprehensive investigation of the topic of opinion alignment in LLMs across global, language, and temporal dimensions. Our code and data are publicly available at https://github.com/ku-nlp/global-opinion-alignment and https://github.com/nlply/global-opinion-alignment.