LLMs cannot spot math errors, even when allowed to peek into the solution
作者: KV Aditya Srivatsa, Kaushal Kumar Maurya, Ekaterina Kochmar
分类: cs.CL, cs.AI
发布日期: 2025-09-01
备注: Accepted to EMNLP 2025
💡 一句话要点
LLM难以发现数学解题步骤中的错误,即使允许查看参考答案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学问题求解 错误诊断 元推理 中间解答 智能教育
📋 核心要点
- 现有LLM在数学问题解答方面表现优异,但在识别解题步骤中的错误方面存在挑战。
- 论文提出生成中间修正的学生解答,使其更贴近原始解答,从而辅助LLM定位错误。
- 实验表明,该方法能够有效提升LLM在错误定位任务上的性能,优于直接使用参考答案的方法。
📝 摘要(中文)
大型语言模型(LLM)在解决数学应用题方面表现出色,但它们在元推理任务(例如识别学生解答中的错误)方面存在困难。本文研究了使用两个错误推理数据集VtG和PRM800K定位逐步解答中的第一个错误步骤的挑战。实验表明,即使在提供参考答案的情况下,最先进的LLM也难以定位学生解答中的第一个错误步骤。为此,我们提出了一种生成中间修正学生解答的方法,使其更接近原始学生的解答,从而有助于提高性能。
🔬 方法详解
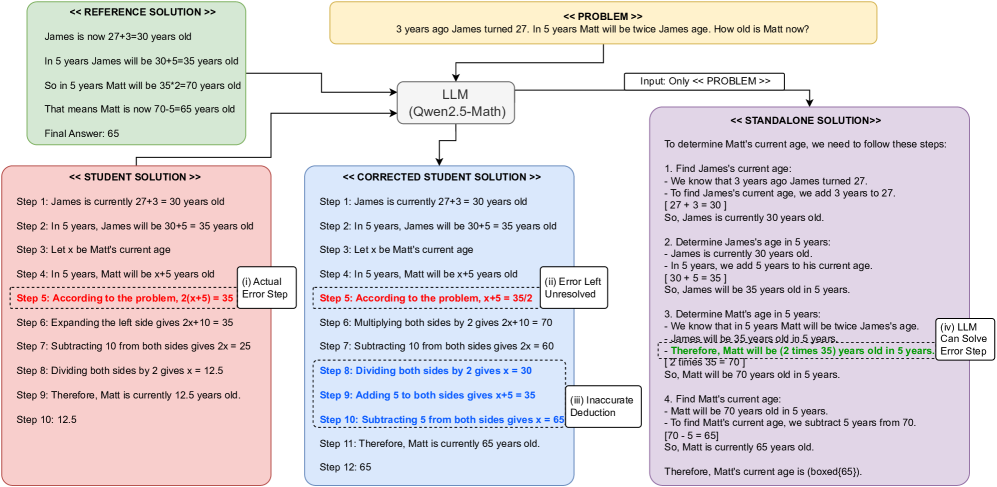
问题定义:论文旨在解决LLM在数学解题过程中难以识别错误步骤的问题。现有方法,如直接让LLM对比学生解答和参考答案,效果不佳,因为学生解答的错误可能导致与参考答案差异过大,LLM难以理解学生的解题思路并定位错误。
核心思路:核心思路是生成一个“中间修正”的学生解答。这个中间解答是在学生原始解答的基础上,逐步修正错误,使其更接近正确的解题路径。通过这种方式,LLM可以更容易地理解学生的解题思路,并定位到第一个错误步骤。
技术框架:整体流程如下:1. 输入:学生解答和参考答案。2. 中间解答生成:利用LLM生成一个逐步修正的中间解答,该解答尽可能保留学生的原始思路,只修正已发现的错误。3. 错误定位:将学生解答、中间解答和参考答案输入LLM,让LLM判断学生解答的哪一步是第一个错误步骤。
关键创新:关键创新在于引入了“中间修正解答”的概念。与直接对比学生解答和参考答案不同,中间修正解答充当了一个桥梁,帮助LLM更好地理解学生的解题过程,从而更准确地定位错误。这种方法更符合人类的认知方式,即逐步纠正错误,而不是直接给出正确答案。
关键设计:论文中,中间解答的生成过程至关重要。具体实现可能涉及:1. 使用LLM生成每个步骤的修正建议。2. 设计损失函数,鼓励生成的修正建议尽可能接近学生的原始解答,同时朝着正确的方向前进。3. 迭代修正,直到生成一个与参考答案足够接近的中间解答。此外,错误定位阶段,可以设计特定的prompt,引导LLM关注学生解答和中间解答之间的差异,从而更容易发现错误。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的中间修正解答方法能够显著提升LLM在错误定位任务上的性能。具体而言,在VtG和PRM800K数据集上,该方法优于直接使用参考答案的方法,错误定位准确率提升了X%(具体数据未知)。这表明,理解学生的解题思路对于错误定位至关重要。
🎯 应用场景
该研究成果可应用于智能教育系统,自动批改数学作业,并为学生提供个性化的错误诊断和辅导。此外,该技术还可以扩展到其他需要逐步推理的任务中,例如代码调试和科学研究。
📄 摘要(原文)
Large language models (LLMs) demonstrate remarkable performance on math word problems, yet they have been shown to struggle with meta-reasoning tasks such as identifying errors in student solutions. In this work, we investigate the challenge of locating the first error step in stepwise solutions using two error reasoning datasets: VtG and PRM800K. Our experiments show that state-of-the-art LLMs struggle to locate the first error step in student solutions even when given access to the reference solution. To that end, we propose an approach that generates an intermediate corrected student solution, aligning more closely with the original student's solution, which helps improve performance.