Can Large Language Models Master Complex Card Games?
作者: Wei Wang, Fuqing Bie, Junzhe Chen, Dan Zhang, Shiyu Huang, Evgeny Kharlamov, Jie Tang
分类: cs.CL
发布日期: 2025-09-01 (更新: 2025-10-21)
备注: Accepted by NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
探索LLM在复杂卡牌游戏中的能力:通过精调实现类人智能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 卡牌游戏 监督精调 多任务学习 通用能力 游戏AI
📋 核心要点
- 现有AI在复杂卡牌游戏中仍面临挑战,缺乏通用性和泛化能力,难以同时精通多种规则迥异的游戏。
- 论文核心在于通过监督精调,使LLM学习卡牌游戏策略,并研究其在多游戏学习和通用能力保持方面的表现。
- 实验表明,LLM通过精调可达到强大游戏AI的水平,但通用能力会下降,可通过混合通用数据缓解。
📝 摘要(中文)
复杂游戏一直是测试人工智能算法进展的重要基准。大型语言模型(LLM)在各种任务中展现出卓越的能力,引发了LLM是否能在复杂游戏中取得类似成功的疑问。本文探讨了LLM在掌握复杂卡牌游戏方面的潜力。系统地评估了LLM在八种不同卡牌游戏中的学习能力,评估了在高质量游戏数据上进行微调的影响,并考察了模型在掌握这些游戏的同时保持通用能力的能力。研究结果表明:(1)LLM可以通过在高质量数据上进行监督微调来接近强大的游戏AI的性能;(2)LLM可以同时在多个复杂卡牌游戏中达到一定的熟练程度,规则相似的游戏性能增强,规则不同的游戏性能冲突;(3)LLM在掌握复杂游戏时,通用能力会下降,但可以通过整合一定量的通用指令数据来缓解这种下降。评估结果表明LLM具有很强的学习能力和通用性。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在复杂卡牌游戏中的学习能力。现有方法,如AlphaGo等,虽然在特定游戏中表现出色,但缺乏通用性,难以适应多种不同规则的卡牌游戏。此外,如何让LLM在学习特定游戏的同时保持其通用能力也是一个挑战。
核心思路:论文的核心思路是利用监督精调(Supervised Fine-tuning, SFT)的方式,让LLM学习高质量的游戏数据,从而掌握卡牌游戏的策略。同时,研究多任务学习(同时学习多个游戏)对LLM性能的影响,以及如何通过混合通用指令数据来缓解LLM在学习特定游戏后通用能力下降的问题。
技术框架:整体框架包括数据收集与处理、模型训练与评估两个主要阶段。首先,收集并清洗高质量的卡牌游戏数据,包括游戏状态、玩家行动等。然后,使用这些数据对LLM进行监督精调,使其学习游戏策略。最后,通过与其他游戏AI或人类玩家对战,以及在通用任务上进行评估,来衡量LLM的游戏水平和通用能力。
关键创新:论文的关键创新在于系统性地研究了LLM在复杂卡牌游戏中的学习能力,并探讨了多任务学习和通用能力保持的问题。不同于以往专注于单一游戏的AI研究,该论文关注LLM的泛化能力和通用性,使其能够适应多种不同的卡牌游戏。
关键设计:论文的关键设计包括:(1) 精心设计的游戏数据格式,确保LLM能够有效地学习游戏状态和行动之间的关系;(2) 使用监督精调方法,利用高质量的游戏数据来训练LLM;(3) 通过混合通用指令数据,缓解LLM在学习特定游戏后通用能力下降的问题;(4) 使用多种评估指标,包括游戏胜率和通用任务的性能,来全面评估LLM的学习效果。
🖼️ 关键图片
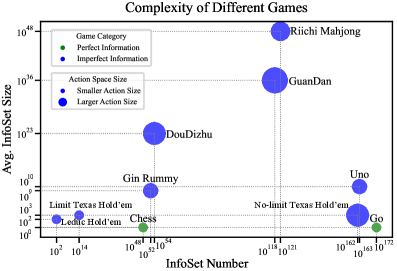
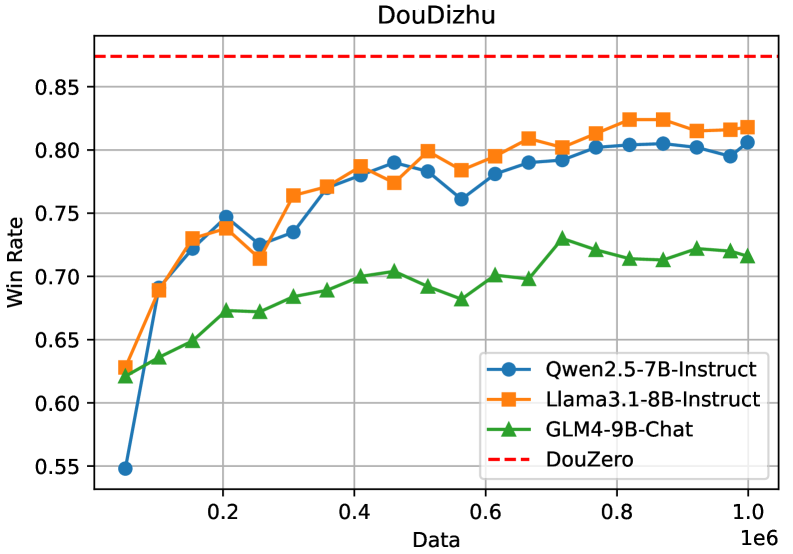

📊 实验亮点
实验结果表明,经过监督精调,LLM在某些卡牌游戏中可以达到接近甚至超过现有游戏AI的水平。同时,研究发现,LLM在学习多个游戏时,规则相似的游戏性能会相互促进,而规则不同的游戏则会产生冲突。此外,通过混合通用指令数据,可以有效缓解LLM在学习特定游戏后通用能力下降的问题,通用能力下降幅度降低10%-20%。
🎯 应用场景
该研究成果可应用于开发更智能的游戏AI,提升游戏体验。此外,该研究对于探索LLM在复杂决策任务中的应用具有重要意义,例如在金融交易、资源调度等领域,LLM可以学习复杂的规则和策略,做出更优的决策。未来,该研究可以进一步扩展到其他类型的复杂游戏和决策问题。
📄 摘要(原文)
Complex games have long been an important benchmark for testing the progress of artificial intelligence algorithms. AlphaGo, AlphaZero, and MuZero have defeated top human players in Go and Chess, garnering widespread societal attention towards artificial intelligence. Concurrently, large language models (LLMs) have exhibited remarkable capabilities across various tasks, raising the question of whether LLMs can achieve similar success in complex games. In this paper, we explore the potential of LLMs in mastering complex card games. We systematically assess the learning capabilities of LLMs across eight diverse card games, evaluating the impact of fine-tuning on high-quality gameplay data, and examining the models' ability to retain general capabilities while mastering these games. Our findings indicate that: (1) LLMs can approach the performance of strong game AIs through supervised fine-tuning on high-quality data, (2) LLMs can achieve a certain level of proficiency in multiple complex card games simultaneously, with performance augmentation for games with similar rules and conflicts for dissimilar ones, and (3) LLMs experience a decline in general capabilities when mastering complex games, but this decline can be mitigated by integrating a certain amount of general instruction data. The evaluation results demonstrate strong learning ability and versatility of LLMs. The code is available at https://github.com/THUDM/LLM4CardGame