LongCat-Flash Technical Report
作者: Meituan LongCat Team, Bayan, Bei Li, Bingye Lei, Bo Wang, Bolin Rong, Chao Wang, Chao Zhang, Chen Gao, Chen Zhang, Cheng Sun, Chengcheng Han, Chenguang Xi, Chi Zhang, Chong Peng, Chuan Qin, Chuyu Zhang, Cong Chen, Congkui Wang, Dan Ma, Daoru Pan, Defei Bu, Dengchang Zhao, Deyang Kong, Dishan Liu, Feiye Huo, Fengcun Li, Fubao Zhang, Gan Dong, Gang Liu, Gang Xu, Ge Li, Guoqiang Tan, Guoyuan Lin, Haihang Jing, Haomin Fu, Haonan Yan, Haoxing Wen, Haozhe Zhao, Hong Liu, Hongmei Shi, Hongyan Hao, Hongyin Tang, Huantian Lv, Hui Su, Jiacheng Li, Jiahao Liu, Jiahuan Li, Jiajun Yang, Jiaming Wang, Jian Yang, Jianchao Tan, Jiaqi Sun, Jiaqi Zhang, Jiawei Fu, Jiawei Yang, Jiaxi Hu, Jiayu Qin, Jingang Wang, Jiyuan He, Jun Kuang, Junhui Mei, Kai Liang, Ke He, Kefeng Zhang, Keheng Wang, Keqing He, Liang Gao, Liang Shi, Lianhui Ma, Lin Qiu, Lingbin Kong, Lingtong Si, Linkun Lyu, Linsen Guo, Liqi Yang, Lizhi Yan, Mai Xia, Man Gao, Manyuan Zhang, Meng Zhou, Mengxia Shen, Mingxiang Tuo, Mingyang Zhu, Peiguang Li, Peng Pei, Peng Zhao, Pengcheng Jia, Pingwei Sun, Qi Gu, Qianyun Li, Qingyuan Li, Qiong Huang, Qiyuan Duan, Ran Meng, Rongxiang Weng, Ruichen Shao, Rumei Li, Shizhe Wu, Shuai Liang, Shuo Wang, Suogui Dang, Tao Fang, Tao Li, Tefeng Chen, Tianhao Bai, Tianhao Zhou, Tingwen Xie, Wei He, Wei Huang, Wei Liu, Wei Shi, Wei Wang, Wei Wu, Weikang Zhao, Wen Zan, Wenjie Shi, Xi Nan, Xi Su, Xiang Li, Xiang Mei, Xiangyang Ji, Xiangyu Xi, Xiangzhou Huang, Xianpeng Li, Xiao Fu, Xiao Liu, Xiao Wei, Xiaodong Cai, Xiaolong Chen, Xiaoqing Liu, Xiaotong Li, Xiaowei Shi, Xiaoyu Li, Xili Wang, Xin Chen, Xing Hu, Xingyu Miao, Xinyan He, Xuemiao Zhang, Xueyuan Hao, Xuezhi Cao, Xunliang Cai, Xurui Yang, Yan Feng, Yang Bai, Yang Chen, Yang Yang, Yaqi Huo, Yerui Sun, Yifan Lu, Yifan Zhang, Yipeng Zang, Yitao Zhai, Yiyang Li, Yongjing Yin, Yongkang Lv, Yongwei Zhou, Yu Yang, Yuchen Xie, Yueqing Sun, Yuewen Zheng, Yuhuai Wei, Yulei Qian, Yunfan Liang, Yunfang Tai, Yunke Zhao, Zeyang Yu, Zhao Zhang, Zhaohua Yang, Zhenchao Zhang, Zhikang Xia, Zhiye Zou, Zhizhao Zeng, Zhongda Su, Zhuofan Chen, Zijian Zhang, Ziwen Wang, Zixu Jiang, Zizhe Zhao, Zongyu Wang, Zunhai Su
分类: cs.CL, cs.AI, cs.DC, cs.LG
发布日期: 2025-09-01 (更新: 2025-09-19)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
LongCat-Flash:一个具有高效计算和高级Agent能力的5600亿参数MoE语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 零计算专家 捷径连接 Agent智能 高效推理 大规模预训练
📋 核心要点
- 现有大型语言模型在计算效率和Agent能力方面存在挑战,难以兼顾模型规模和推理速度。
- LongCat-Flash通过零计算专家和捷径连接MoE,实现了动态计算预算分配和计算-通信重叠,提升了效率。
- 实验表明,LongCat-Flash在Agent任务中表现出色,并以较低成本实现了高吞吐量的推理。
📝 摘要(中文)
本文介绍了LongCat-Flash,一个拥有5600亿参数的混合专家(MoE)语言模型,旨在实现计算效率和高级Agent能力。为了满足可扩展效率的需求,LongCat-Flash采用了两种新颖的设计:(a)零计算专家,能够动态分配计算预算,并根据上下文需求激活186亿到313亿(平均270亿)参数,从而优化资源使用。(b)捷径连接的MoE,扩大了计算-通信重叠窗口,与同等规模的模型相比,在推理效率和吞吐量方面表现出显著的提升。我们为大型模型开发了一个全面的缩放框架,该框架结合了超参数迁移、模型增长初始化、多管齐下的稳定性套件和确定性计算,以实现稳定且可复现的训练。值得注意的是,通过可扩展的架构设计和基础设施努力之间的协同作用,我们在30天内完成了超过20万亿token的模型训练,同时以每百万输出token 0.70美元的成本实现了每秒超过100个token(TPS)的推理速度。为了将LongCat-Flash培养成具有Agent智能的模型,我们对优化的混合数据进行了大规模预训练,然后针对推理、代码和指令进行了有针对性的中期和后期训练,并进一步通过合成数据和工具使用任务进行了增强。全面的评估表明,作为一个非思考的基础模型,LongCat-Flash在其他领先模型中表现出极具竞争力的性能,并在Agent任务中具有卓越的优势。LongCat-Flash的模型检查点已开源,以促进社区研究。
🔬 方法详解
问题定义:现有大型语言模型在扩展规模的同时,面临着计算效率和推理速度的挑战。传统的稠密模型参数量巨大,推理成本高昂。混合专家模型(MoE)虽然能提升效率,但专家之间的通信开销和计算资源的静态分配仍然存在优化空间。
核心思路:LongCat-Flash的核心思路是通过动态调整激活的专家数量和优化专家间的通信,在保证模型性能的同时,显著提升计算效率和推理速度。零计算专家机制允许模型根据输入动态调整计算量,而捷径连接MoE则减少了专家间的通信延迟。
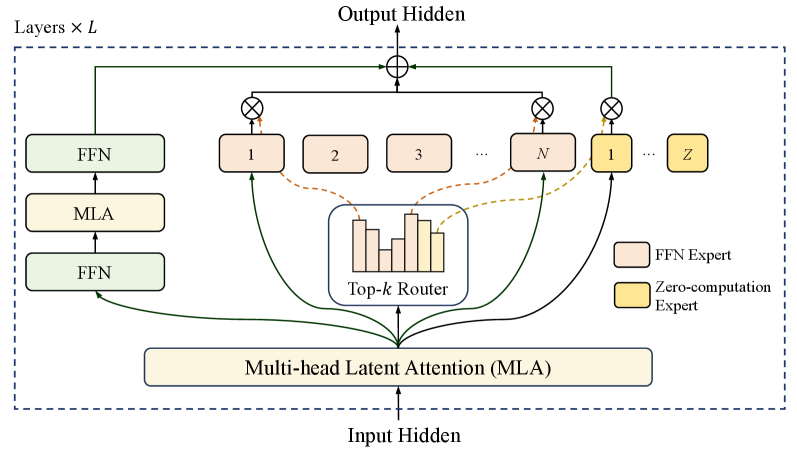
技术框架:LongCat-Flash采用混合专家模型(MoE)架构,包含多个专家网络和一个门控网络。门控网络根据输入token选择激活哪些专家。零计算专家机制允许部分专家在某些token上不进行计算,从而节省计算资源。捷径连接MoE通过添加shortcut连接,减少了专家间的通信延迟,提高了推理效率。整体训练流程包括预训练、中期训练和后期训练,并使用合成数据和工具使用任务进行增强。
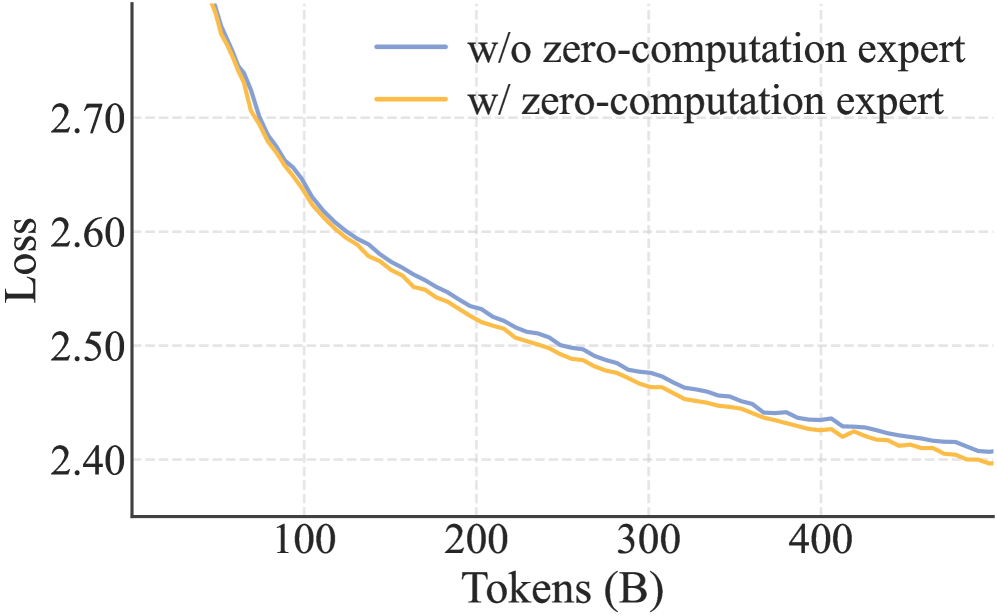
关键创新:LongCat-Flash的关键创新在于零计算专家和捷径连接MoE。零计算专家允许模型动态调整计算预算,根据输入token的复杂程度选择激活的专家数量。捷径连接MoE通过添加shortcut连接,减少了专家间的通信延迟,提高了推理效率。这两种机制的结合使得LongCat-Flash在保证模型性能的同时,显著提升了计算效率和推理速度。
关键设计:LongCat-Flash使用了5600亿参数,其中平均每个token激活270亿参数。训练过程中采用了超参数迁移、模型增长初始化、多管齐下的稳定性套件和确定性计算,以保证训练的稳定性和可复现性。模型训练了超过20万亿token,并在推理时实现了每秒超过100个token(TPS)的速度,成本为每百万输出token 0.70美元。
🖼️ 关键图片
📊 实验亮点
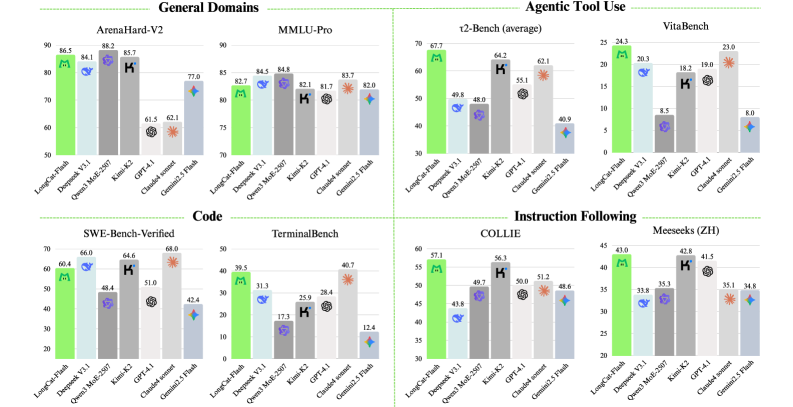
LongCat-Flash在30天内完成了超过20万亿token的模型训练,并在推理时实现了每秒超过100个token(TPS)的速度,成本为每百万输出token 0.70美元。在Agent任务中表现出极具竞争力的性能,证明了其在计算效率和Agent能力方面的优势。
🎯 应用场景
LongCat-Flash适用于需要高效计算和高级Agent能力的各种应用场景,例如智能助手、对话系统、代码生成、知识问答等。其高效的推理能力使其能够部署在资源受限的设备上,并支持大规模的在线服务。该研究有望推动Agent智能的发展,并为构建更智能、更高效的人工智能系统提供新的思路。
📄 摘要(原文)
We introduce LongCat-Flash, a 560-billion-parameter Mixture-of-Experts (MoE) language model designed for both computational efficiency and advanced agentic capabilities. Stemming from the need for scalable efficiency, LongCat-Flash adopts two novel designs: (a) Zero-computation Experts, which enables dynamic computational budget allocation and activates 18.6B-31.3B (27B on average) per token depending on contextual demands, optimizing resource usage. (b) Shortcut-connected MoE, which enlarges the computation-communication overlap window, demonstrating notable gains in inference efficiency and throughput compared to models of a comparable scale. We develop a comprehensive scaling framework for large models that combines hyperparameter transfer, model-growth initialization, a multi-pronged stability suite, and deterministic computation to achieve stable and reproducible training. Notably, leveraging the synergy among scalable architectural design and infrastructure efforts, we complete model training on more than 20 trillion tokens within 30 days, while achieving over 100 tokens per second (TPS) for inference at a cost of \$0.70 per million output tokens. To cultivate LongCat-Flash towards agentic intelligence, we conduct a large-scale pre-training on optimized mixtures, followed by targeted mid- and post-training on reasoning, code, and instructions, with further augmentation from synthetic data and tool use tasks. Comprehensive evaluations demonstrate that, as a non-thinking foundation model, LongCat-Flash delivers highly competitive performance among other leading models, with exceptional strengths in agentic tasks. The model checkpoint of LongCat-Flash is open-sourced to foster community research. LongCat Chat: https://longcat.ai Hugging Face: https://huggingface.co/meituan-longcat GitHub: https://github.com/meituan-longcat