Quantifying Label-Induced Bias in Large Language Model Self- and Cross-Evaluations
作者: Muskan Saraf, Sajjad Rezvani Boroujeni, Justin Beaudry, Hossein Abedi, Tom Bush
分类: cs.CL, cs.AI
发布日期: 2025-08-28 (更新: 2025-10-09)
💡 一句话要点
揭示大语言模型评估中标签诱导的偏见,强调盲评的重要性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 文本评估 标签偏见 盲评 模型基准测试
📋 核心要点
- 现有研究缺乏对LLM作为评估者时,其判断有效性的深入探索,尤其是在标签信息可能引入偏见的情况下。
- 该研究设计了受控实验,通过操纵标签信息,观察LLM在自我评估和交叉评估中的偏见模式。
- 实验结果表明,LLM的评估结果会受到标签信息的显著影响,即使内容质量相同,不同的标签也会导致评估结果的巨大差异。
📝 摘要(中文)
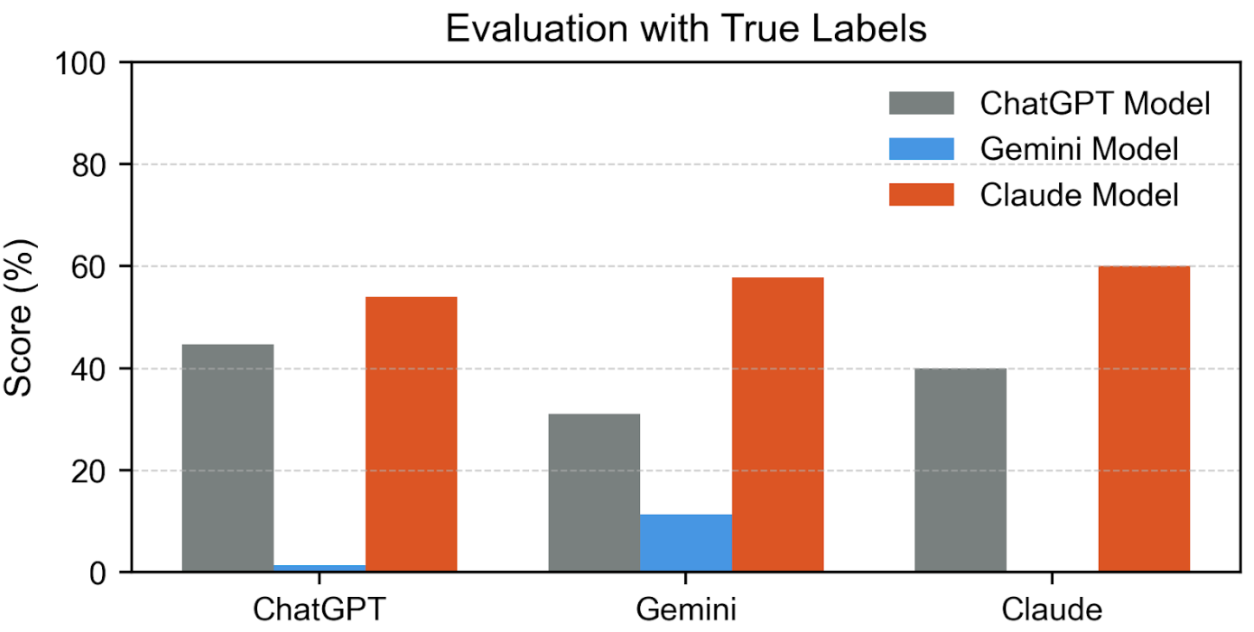
本研究调查了大型语言模型(LLM)在自我评估和交叉评估中存在的系统性偏见。研究对象包括ChatGPT、Gemini和Claude三个主流LLM。通过设计受控实验,让这三个模型在四种标签条件下(无归属、真实归属、两种虚假归属)评估彼此生成的博客文章。评估方式包括整体偏好投票和细粒度的质量评分(连贯性、信息量和简洁性),所有分数均归一化为百分比以便直接比较。结果表明,模型判断存在显著不对称性:“Claude”标签始终提升分数,而“Gemini”标签则系统性地降低分数。虚假归属经常颠倒偏好排名,导致投票结果变化高达50个百分点,质量评分变化高达12个百分点。Gemini在真实标签下表现出严重的自我贬低,而Claude则表现出更强的自我偏好。这些结果表明,感知的模型身份会显著扭曲高层次判断和细粒度质量评估,与内容质量无关。研究结果挑战了LLM作为评估者的可靠性,并强调了盲评协议和多样化的多模型验证框架对于确保自动化文本评估和LLM基准测试的公平性和有效性的关键需求。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在文本质量评估中存在的标签诱导偏见问题。现有方法,即直接使用LLM进行评估,可能受到模型身份标签的影响,导致评估结果不准确,无法真实反映文本质量。这种偏见会影响LLM基准测试的公平性和可靠性,阻碍LLM的健康发展。
核心思路:核心思路是通过控制实验,操纵评估文本的标签信息(作者身份),观察LLM在不同标签下的评估结果。通过比较不同标签下的评估差异,量化标签诱导的偏见程度。这种方法能够有效隔离标签信息对评估结果的影响,从而揭示LLM评估的潜在偏见。
技术框架:整体实验框架包括以下几个阶段:1) 使用ChatGPT、Gemini和Claude生成博客文章;2) 设计四种标签条件:无归属、真实归属、两种虚假归属;3) 让三个模型在四种标签条件下评估彼此生成的博客文章;4) 采用两种评估方式:整体偏好投票和细粒度的质量评分(连贯性、信息量和简洁性);5) 对所有分数进行归一化处理,以便直接比较。
关键创新:关键创新在于设计了受控的标签操纵实验,能够有效量化LLM评估中标签诱导的偏见。通过比较不同标签下的评估结果,揭示了LLM评估的潜在偏见模式,例如“Claude”标签的提升效应和“Gemini”标签的降低效应。
关键设计:关键设计包括:1) 使用三种主流LLM(ChatGPT、Gemini和Claude)作为研究对象,增加了研究的代表性;2) 设计了四种标签条件,全面考察了标签信息对评估结果的影响;3) 采用两种评估方式(整体偏好投票和细粒度的质量评分),从不同角度评估文本质量;4) 对所有分数进行归一化处理,方便比较不同模型和标签下的评估结果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,“Claude”标签始终提升分数,而“Gemini”标签则系统性地降低分数。虚假归属经常颠倒偏好排名,导致投票结果变化高达50个百分点,质量评分变化高达12个百分点。Gemini在真实标签下表现出严重的自我贬低,而Claude则表现出更强的自我偏好。这些数据清晰地展示了标签信息对LLM评估结果的显著影响。
🎯 应用场景
该研究成果可应用于改进LLM的评估方法,例如采用盲评协议,避免标签信息对评估结果的干扰。此外,该研究还可用于开发更公平、更可靠的LLM基准测试方法,促进LLM技术的健康发展。未来的研究可以探索如何减轻或消除LLM评估中的偏见,提高LLM评估的准确性和可靠性。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed as evaluators of text quality, yet the validity of their judgments remains underexplored. This study investigates systematic bias in self- and cross-model evaluations across three prominent LLMs: ChatGPT, Gemini, and Claude. We designed a controlled experiment in which blog posts authored by each model were evaluated by all three models under four labeling conditions: no attribution, true attribution, and two false-attribution scenarios. Evaluations employed both holistic preference voting and granular quality ratings across three dimensions Coherence, Informativeness, and Conciseness with all scores normalized to percentages for direct comparison. Our findings reveal pronounced asymmetries in model judgments: the "Claude" label consistently elevated scores regardless of actual authorship, while the "Gemini" label systematically depressed them. False attribution frequently reversed preference rankings, producing shifts of up to 50 percentage points in voting outcomes and up to 12 percentage points in quality ratings. Notably, Gemini exhibited severe self-deprecation under true labels, while Claude demonstrated intensified self-preference. These results demonstrate that perceived model identity can substantially distort both high-level judgments and fine-grained quality assessments, independent of content quality. Our findings challenge the reliability of LLM-as-judge paradigms and underscore the critical need for blind evaluation protocols and diverse multi-model validation frameworks to ensure fairness and validity in automated text evaluation and LLM benchmarking.