The Percept-V Challenge: Can Multimodal LLMs Crack Simple Perception Problems?
作者: Samrajnee Ghosh, Naman Agarwal, Hemanshu Garg, Chinmay Mittal, Mausam, Parag Singla
分类: cs.CL, cs.CV
发布日期: 2025-08-28 (更新: 2026-01-22)
💡 一句话要点
提出Percept-V数据集,评估多模态大语言模型在基础视觉感知任务上的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉感知 数据集 基准测试 TVPS-4
📋 核心要点
- 现有基准测试侧重于MLLM的高级推理和知识技能,缺乏对基础视觉感知能力的充分评估。
- 论文构建Percept-V数据集,包含程序生成的简单视觉感知任务,旨在评估MLLM的感知能力。
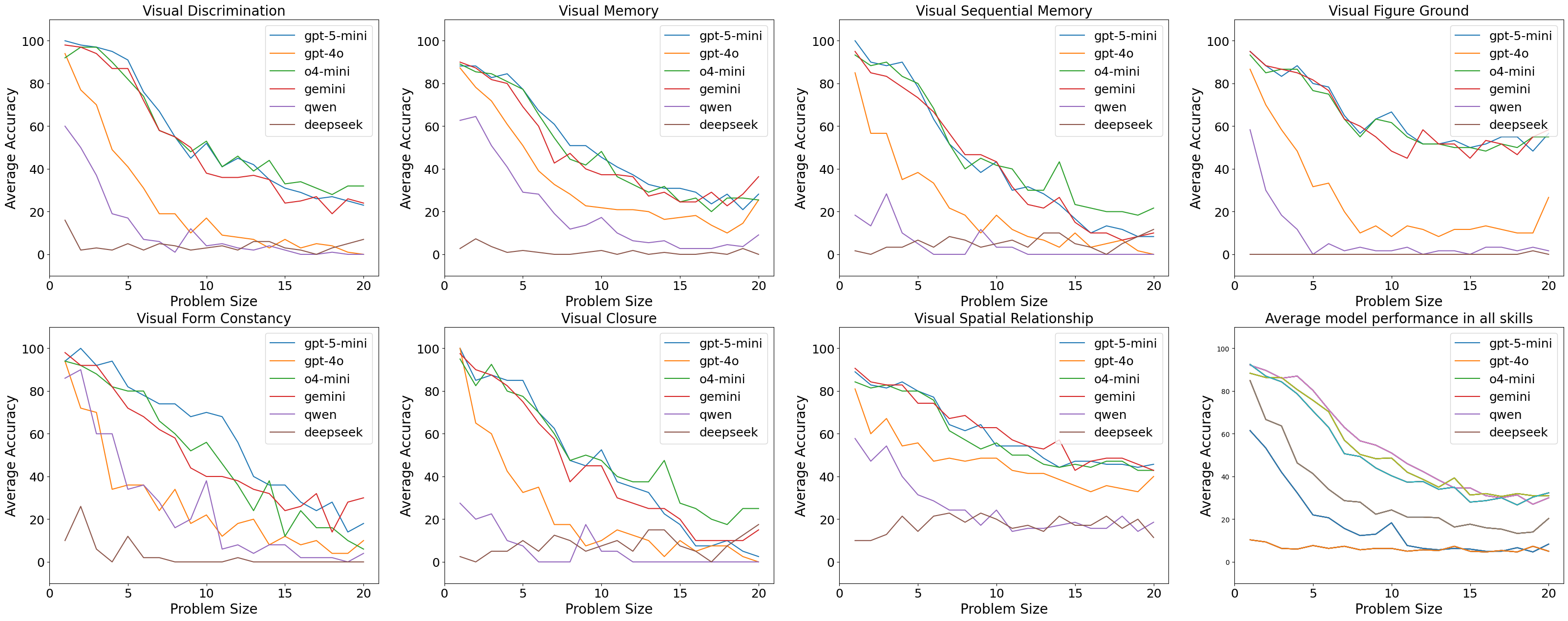
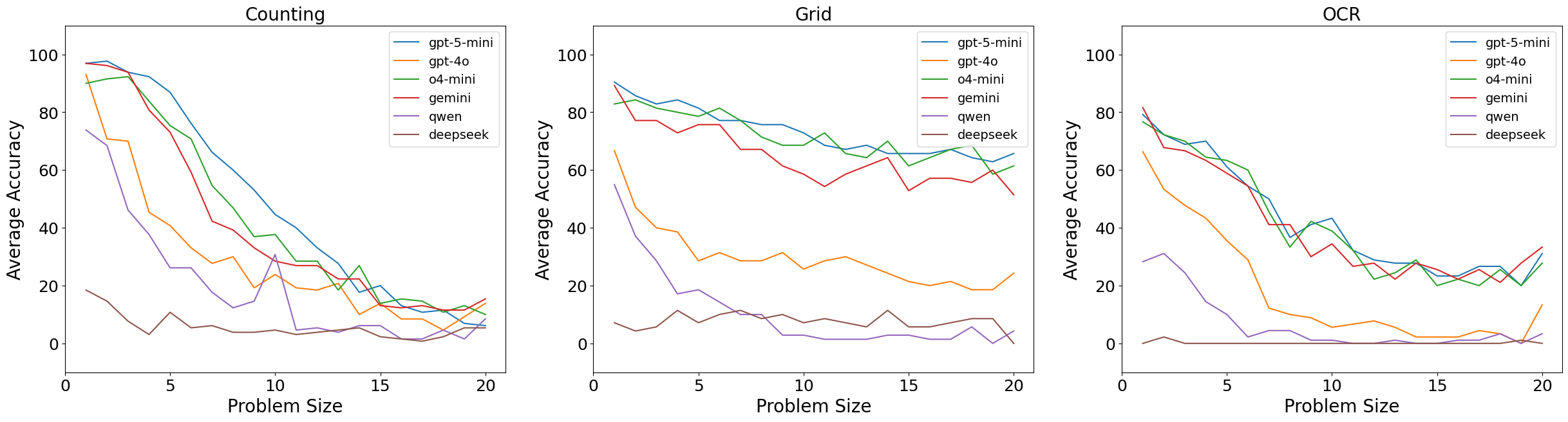
- 实验表明,现有MLLM在Percept-V上的表现远低于人类水平,尤其是在处理包含多个对象的图像时。
📝 摘要(中文)
认知科学研究将视觉感知,即理解和理解视觉输入的能力,视为早期智力发展的标志之一。TVPS-4框架将人类感知分为七种技能,如视觉辨别和形式恒常性,并对其进行测试。多模态大语言模型(MLLM)在基本感知方面能与人类相媲美吗?尽管有许多基准测试评估MLLM在高级推理和知识技能方面的能力,但专注于简单感知评估的研究有限。为此,我们引入了Percept-V,一个包含6000个程序生成的无污染图像的数据集,分为30个领域,每个领域测试一个或多个TVPS-4技能。我们的重点是感知,因此我们使我们的领域非常简单,解决它们所需的推理和知识最少。由于现代MLLM可以解决更复杂的任务,我们先验地期望它们能够非常容易地解决这些领域。与我们的信念相反,我们的实验表明,与Percept-V上非常高的人类表现相比,SoTA专有和开源MLLM的表现较弱。我们发现,随着图像中对象数量的增加,性能下降得相当快。我们的实验还确定了所有模型都难以掌握的感知技能。
🔬 方法详解
问题定义:论文旨在评估多模态大语言模型(MLLM)在基础视觉感知任务上的能力。现有MLLM的评估主要集中在高级推理和知识技能上,缺乏对简单视觉感知能力的系统性评估。这使得我们难以了解MLLM在处理基本视觉信息方面的真实水平,以及它们是否具备像人类一样的早期智力发展特征。
核心思路:论文的核心思路是构建一个专门用于评估MLLM视觉感知能力的数据集,并在此数据集上测试现有MLLM的性能。通过设计一系列简单但具有代表性的视觉感知任务,例如视觉辨别和形式恒常性,来考察MLLM在处理基本视觉信息时的表现。这种方法能够更直接地反映MLLM的视觉感知能力,并揭示其在这一方面的优势和不足。
技术框架:论文构建了名为Percept-V的数据集,包含6000个程序生成的图像,分为30个领域。每个领域都针对TVPS-4框架中的一项或多项视觉感知技能进行测试。数据集中的图像设计简单,以减少推理和知识需求,从而更专注于评估感知能力。论文使用该数据集对现有的SoTA专有和开源MLLM进行评估,并分析它们的性能表现。
关键创新:论文的关键创新在于构建了Percept-V数据集,该数据集专门用于评估MLLM的视觉感知能力。与现有的MLLM评估基准相比,Percept-V更侧重于简单和基础的视觉感知任务,能够更直接地反映MLLM在处理基本视觉信息方面的能力。此外,数据集采用程序生成的方式,保证了图像的无污染性,从而提高了评估结果的可靠性。
关键设计:Percept-V数据集的设计关键在于任务的简单性和多样性。每个任务都围绕TVPS-4框架中的一项或多项视觉感知技能展开,例如视觉辨别、形式恒常性、视觉记忆等。图像中的对象数量和复杂度被控制在较低水平,以减少推理和知识需求。数据集包含30个不同的领域,每个领域都包含多个不同的任务,从而保证了评估的全面性和多样性。具体的参数设置和网络结构取决于被评估的MLLM模型,论文主要关注模型的整体性能表现,而非特定参数的优化。
🖼️ 关键图片
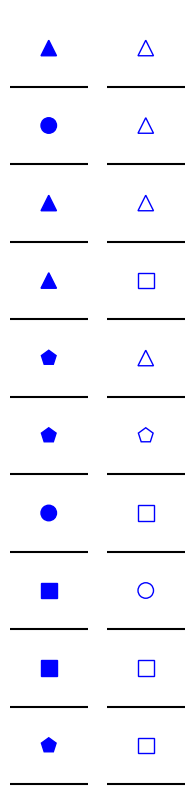
📊 实验亮点
实验结果表明,现有SoTA的MLLM在Percept-V数据集上的表现远低于人类水平。随着图像中对象数量的增加,MLLM的性能迅速下降。实验还发现,某些特定的视觉感知技能,例如形式恒常性,对所有模型来说都更具挑战性。这些结果揭示了现有MLLM在基础视觉感知能力方面的不足。
🎯 应用场景
该研究成果可应用于评估和改进多模态大语言模型的视觉感知能力,推动其在机器人、自动驾驶、图像搜索等领域的应用。通过更准确地理解视觉信息,MLLM可以更好地与环境交互,并执行更复杂的任务。此外,该数据集可以作为未来研究的基础,促进视觉感知领域的发展。
📄 摘要(原文)
Cognitive science research treats visual perception, the ability to understand and make sense of a visual input, as one of the early developmental signs of intelligence. Its TVPS-4 framework categorizes and tests human perception into seven skills such as visual discrimination, and form constancy. Do Multimodal Large Language Models (MLLMs) match up to humans in basic perception? Even though there are many benchmarks that evaluate MLLMs on advanced reasoning and knowledge skills, there is limited research that focuses evaluation on simple perception. In response, we introduce Percept-V, a dataset containing 6000 program-generated uncontaminated images divided into 30 domains, where each domain tests one or more TVPS-4 skills. Our focus is on perception, so we make our domains quite simple and the reasoning and knowledge required for solving them are minimal. Since modern-day MLLMs can solve much more complex tasks, our a-priori expectation is that they will solve these domains very easily. Contrary to our belief, our experiments show a weak performance of SoTA proprietary and open-source MLLMs compared to very high human performance on Percept-V. We find that as number of objects in the image increases, performance goes down rather fast. Our experiments also identify the perception skills that are considerably harder for all models.