On the Theoretical Limitations of Embedding-Based Retrieval
作者: Orion Weller, Michael Boratko, Iftekhar Naim, Jinhyuk Lee
分类: cs.IR, cs.CL, cs.LG
发布日期: 2025-08-28
💡 一句话要点
揭示基于嵌入检索的理论局限性:即使简单查询也可能失效
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 向量嵌入 信息检索 理论局限性 学习理论 数据集构建
📋 核心要点
- 现有向量嵌入检索方法在处理复杂查询时面临理论限制,但常被认为可通过改进训练数据和模型规模解决。
- 论文指出即使是简单查询,由于嵌入维度限制,也可能导致检索结果不理想,揭示了单向量嵌入范式的根本局限。
- 通过理论分析和实验验证,包括构建LIMIT数据集,证明了现有模型在简单任务上也可能失效,呼吁新的检索方法。
📝 摘要(中文)
近年来,向量嵌入被广泛应用于各种检索任务,包括推理、指令跟随和代码生成等。这些新兴基准对嵌入提出了更高的要求,期望其能够处理任何查询和任何相关性概念。尽管之前的研究已经指出了向量嵌入的理论局限性,但通常认为这些困难仅仅源于不切实际的查询,并且可以通过更好的训练数据和更大的模型来克服。本文证明,即使在现实场景中使用极其简单的查询,也可能遇到这些理论限制。我们结合学习理论中的已知结果,表明能够作为查询结果返回的top-k文档子集的数量受到嵌入维度的限制。实验结果表明,即使限制k=2并直接在测试集上优化自由参数化嵌入,这一结论仍然成立。我们创建了一个名为LIMIT的现实数据集,用于测试基于这些理论结果的模型,并观察到即使是最先进的模型也无法在该数据集上取得良好表现,尽管任务本身非常简单。这项工作揭示了现有单向量范式下嵌入模型的局限性,并呼吁未来的研究开发能够解决这一根本限制的方法。
🔬 方法详解
问题定义:论文关注的是基于嵌入的检索方法在处理各种查询时存在的理论局限性。现有方法,即使通过增加训练数据和模型规模来改进,仍然可能在简单的查询场景下失效。痛点在于,单向量嵌入范式本身存在固有的表达能力限制,无法有效区分所有可能的top-k文档子集。
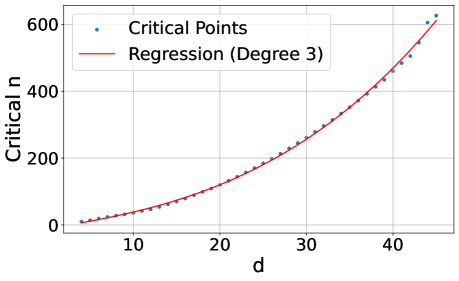
核心思路:论文的核心思路是连接学习理论中的已知结果,证明能够作为查询结果返回的top-k文档子集的数量受到嵌入维度的限制。这意味着,即使查询非常简单,如果需要区分的文档子集数量超过嵌入维度所能表达的范围,检索性能就会受到影响。因此,论文认为单向量嵌入范式存在根本性的局限。
技术框架:论文主要通过理论分析和实验验证来支持其观点。首先,论文从理论上推导了嵌入维度与可区分的top-k文档子集数量之间的关系。然后,论文设计了一系列实验,包括在合成数据集和真实数据集上的测试,以验证理论分析的正确性。此外,论文还构建了一个名为LIMIT的现实数据集,专门用于测试模型在理论限制下的表现。
关键创新:论文最重要的技术创新点在于,它将学习理论中的结果与嵌入检索的实际问题联系起来,揭示了单向量嵌入范式在表达能力上的根本局限性。之前的研究主要关注如何通过改进训练数据和模型结构来提高嵌入检索的性能,而本文则从理论层面指出了这种方法的局限性,为未来的研究方向提供了新的思路。
关键设计:LIMIT数据集的设计是关键。该数据集旨在测试模型在区分相似文档时的能力,这些文档在语义上非常接近,但需要根据细微的差异进行区分。论文还设计了实验,直接在测试集上优化自由参数化嵌入,以排除训练数据和模型结构的影响,从而更清晰地展示了嵌入维度的限制。
🖼️ 关键图片
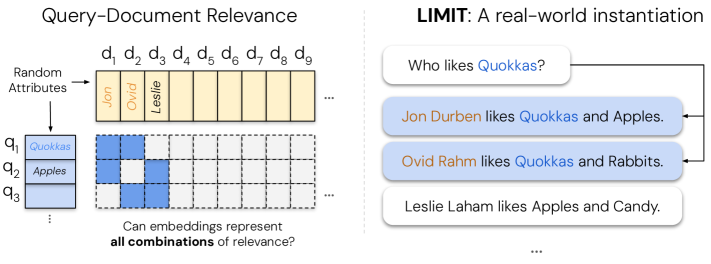
📊 实验亮点
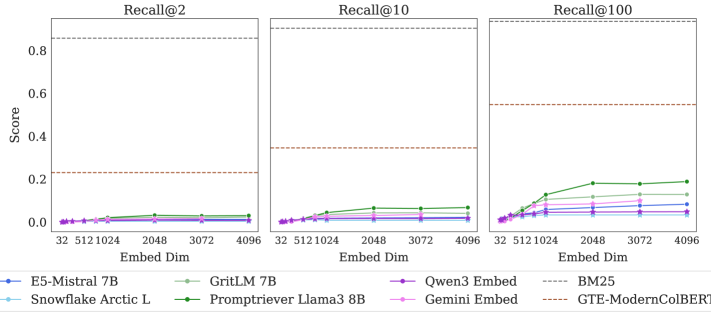
论文通过实验验证了嵌入维度对检索性能的影响。即使限制k=2,并直接在测试集上优化自由参数化嵌入,也观察到性能瓶颈。在LIMIT数据集上,即使是最先进的模型也无法取得良好表现,这表明现有模型在处理需要细粒度区分的任务时存在局限性。
🎯 应用场景
该研究成果对信息检索、推荐系统、问答系统等领域具有重要意义。它提醒研究人员在设计和应用基于嵌入的检索方法时,需要考虑嵌入维度的限制,并探索新的检索范式,例如使用更复杂的嵌入结构或引入外部知识。
📄 摘要(原文)
Vector embeddings have been tasked with an ever-increasing set of retrieval tasks over the years, with a nascent rise in using them for reasoning, instruction-following, coding, and more. These new benchmarks push embeddings to work for any query and any notion of relevance that could be given. While prior works have pointed out theoretical limitations of vector embeddings, there is a common assumption that these difficulties are exclusively due to unrealistic queries, and those that are not can be overcome with better training data and larger models. In this work, we demonstrate that we may encounter these theoretical limitations in realistic settings with extremely simple queries. We connect known results in learning theory, showing that the number of top-k subsets of documents capable of being returned as the result of some query is limited by the dimension of the embedding. We empirically show that this holds true even if we restrict to k=2, and directly optimize on the test set with free parameterized embeddings. We then create a realistic dataset called LIMIT that stress tests models based on these theoretical results, and observe that even state-of-the-art models fail on this dataset despite the simple nature of the task. Our work shows the limits of embedding models under the existing single vector paradigm and calls for future research to develop methods that can resolve this fundamental limitation.