ProactiveEval: A Unified Evaluation Framework for Proactive Dialogue Agents
作者: Tianjian Liu, Fanqi Wan, Jiajian Guo, Xiaojun Quan
分类: cs.CL, cs.AI, cs.HC
发布日期: 2025-08-28
备注: 21 pages, 6 Figures
💡 一句话要点
ProactiveEval:用于评估主动对话Agent的统一评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主动对话 评估框架 大型语言模型 目标规划 对话引导 自动化评估 人机交互
📋 核心要点
- 现有主动对话评估侧重特定领域,缺乏统一框架,难以全面评估LLM的主动对话能力。
- ProactiveEval框架将主动对话分解为目标规划和对话引导,并自动生成多样化评估数据。
- 实验表明DeepSeek-R1和Claude-3.7-Sonnet在目标规划和对话引导方面表现突出,推理能力影响主动行为。
📝 摘要(中文)
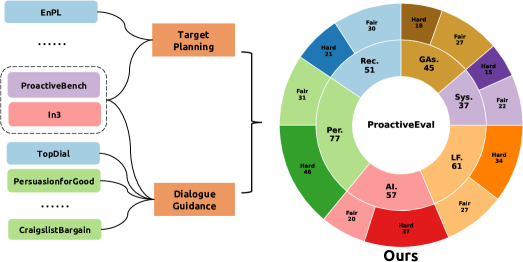
主动对话已成为推进大型语言模型(LLM)发展中一个关键且具有挑战性的研究问题。目前的研究主要集中在特定领域或面向任务的场景,导致评估体系的碎片化,限制了对模型主动对话能力的全面探索。本文提出了ProactiveEval,一个旨在评估LLM主动对话能力的统一框架。该框架将主动对话分解为目标规划和对话引导,从而在各个领域建立评估指标。此外,它还支持自动生成多样且具有挑战性的评估数据。基于该框架,我们开发了涵盖6个不同领域的328个评估环境。通过对22种不同类型的LLM进行实验,结果表明DeepSeek-R1和Claude-3.7-Sonnet分别在目标规划和对话引导任务上表现出色。最后,我们研究了推理能力如何影响主动行为,并讨论了其对未来模型开发的意义。
🔬 方法详解
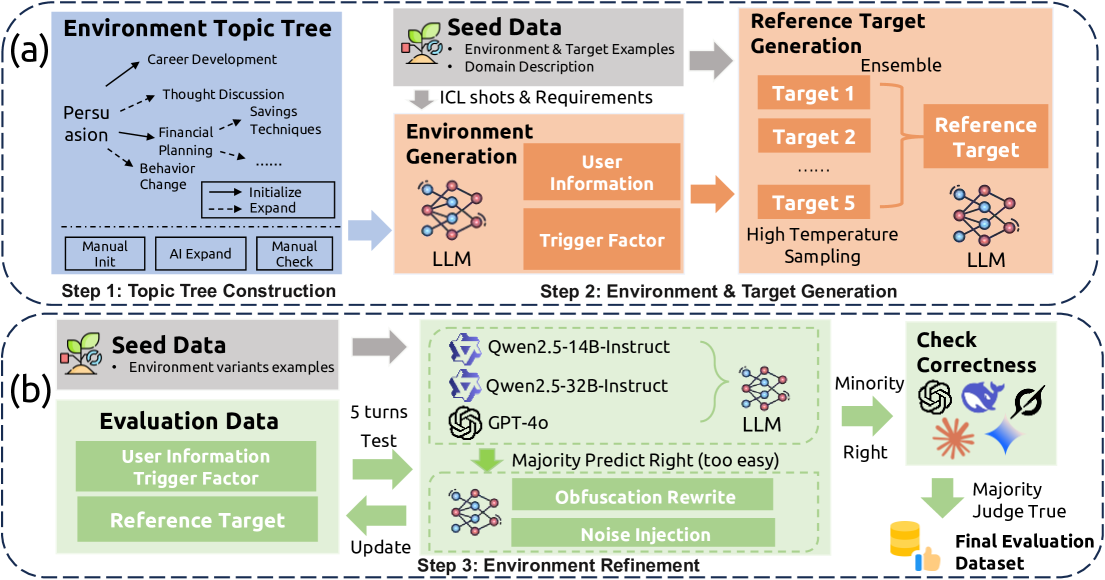
问题定义:现有主动对话Agent的评估主要集中在特定领域或任务,缺乏一个统一的、跨领域的评估框架。这导致无法全面、客观地评估LLM在主动对话方面的能力,阻碍了相关研究的进展。现有方法难以生成多样且具有挑战性的评估数据,进一步限制了对模型能力的探索。
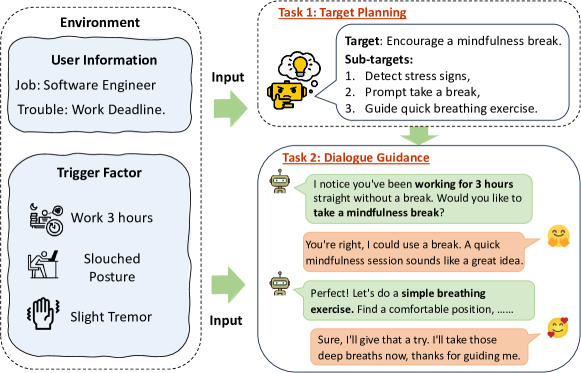
核心思路:ProactiveEval的核心思路是将主动对话分解为两个关键组成部分:目标规划和对话引导。目标规划指的是Agent在对话开始前确定对话目标的能力,而对话引导指的是Agent在对话过程中引导对话朝着目标前进的能力。通过分别评估这两个方面,可以更全面地了解Agent的主动对话能力。同时,框架设计了自动生成评估数据的方法,以保证评估的多样性和挑战性。
技术框架:ProactiveEval框架包含以下几个主要模块:1) 评估环境构建模块:负责构建各种领域下的对话环境,包括用户画像、对话背景等。2) 数据生成模块:自动生成多样化的评估数据,包括正例和负例。3) 评估指标定义模块:针对目标规划和对话引导分别定义评估指标,例如目标达成率、对话流畅度等。4) 模型评估模块:使用生成的评估数据和定义的评估指标,对LLM进行评估。
关键创新:ProactiveEval的关键创新在于提出了一个统一的、跨领域的评估框架,能够全面评估LLM的主动对话能力。此外,该框架还支持自动生成多样化的评估数据,避免了人工标注的成本和偏差。将主动对话分解为目标规划和对话引导,使得评估更加细粒度和可解释。
关键设计:框架的关键设计包括:1) 评估环境的多样性:涵盖了6个不同的领域,保证了评估的泛化能力。2) 数据生成策略:采用了多种数据增强技术,生成了多样化的评估数据。3) 评估指标的合理性:针对目标规划和对话引导分别设计了合理的评估指标,能够准确反映模型的能力。4) 评估流程的自动化:整个评估流程是自动化的,减少了人工干预。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DeepSeek-R1在目标规划任务上表现出色,而Claude-3.7-Sonnet在对话引导任务上表现突出。通过对22种不同LLM的评估,验证了ProactiveEval框架的有效性和通用性。研究还发现,模型的推理能力与主动行为之间存在显著相关性,表明提升模型的推理能力有助于提高其主动对话能力。
🎯 应用场景
ProactiveEval可应用于开发更智能、更主动的对话Agent,例如智能客服、虚拟助手、教育机器人等。通过该框架,可以系统地评估和提升LLM在主动对话方面的能力,使其能够更好地理解用户需求、主动引导对话、提供个性化服务,从而提升用户体验和满意度。该研究还有助于推动人机交互领域的发展。
📄 摘要(原文)
Proactive dialogue has emerged as a critical and challenging research problem in advancing large language models (LLMs). Existing works predominantly focus on domain-specific or task-oriented scenarios, which leads to fragmented evaluations and limits the comprehensive exploration of models' proactive conversation abilities. In this work, we propose ProactiveEval, a unified framework designed for evaluating proactive dialogue capabilities of LLMs. This framework decomposes proactive dialogue into target planning and dialogue guidance, establishing evaluation metrics across various domains. Moreover, it also enables the automatic generation of diverse and challenging evaluation data. Based on the proposed framework, we develop 328 evaluation environments spanning 6 distinct domains. Through experiments with 22 different types of LLMs, we show that DeepSeek-R1 and Claude-3.7-Sonnet exhibit exceptional performance on target planning and dialogue guidance tasks, respectively. Finally, we investigate how reasoning capabilities influence proactive behaviors and discuss their implications for future model development.