SageLM: A Multi-aspect and Explainable Large Language Model for Speech Judgement
作者: Yuan Ge, Junxiang Zhang, Xiaoqian Liu, Bei Li, Xiangnan Ma, Chenglong Wang, Kaiyang Ye, Yangfan Du, Linfeng Zhang, Yuxin Huang, Tong Xiao, Zhengtao Yu, JingBo Zhu
分类: cs.CL
发布日期: 2025-08-28 (更新: 2025-11-10)
💡 一句话要点
SageLM:用于语音评判的多方面可解释大型语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音评估 大型语言模型 可解释性 多模态融合 端到端学习
📋 核心要点
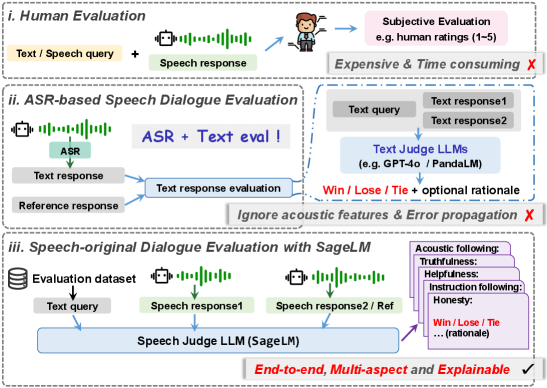
- S2S LLM评估面临挑战,现有方法或忽略声学特征,或缺乏可解释性。
- SageLM联合评估语义和声学维度,利用基于理由的监督增强可解释性。
- 引入SpeechFeedback数据集,采用两阶段训练,SageLM协议率达82.79%。
📝 摘要(中文)
语音到语音(S2S)大型语言模型(LLM)是自然人机交互的基础,能够实现端到端的口语对话系统。然而,评估这些模型仍然是一个根本性的挑战。我们提出了 exttt{SageLM},一个端到端、多方面且可解释的语音LLM,用于全面评估S2S LLM。首先,与忽略声学特征的级联方法不同,SageLM联合评估语义和声学维度。其次,它利用基于理由的监督来增强可解释性并指导模型学习,与基于规则的强化学习方法相比,实现了与评估结果的更好对齐。第三,我们引入了 extit{SpeechFeedback},一个合成偏好数据集,并采用两阶段训练范式来缓解语音偏好数据的稀缺性。在语义和声学维度上训练的SageLM与人类评估者的协议率达到了82.79%,分别优于级联和基于SLM的基线至少7.42%和26.20%。
🔬 方法详解
问题定义:论文旨在解决语音到语音(S2S)大型语言模型(LLM)的评估问题。现有方法,如级联方法,通常忽略了重要的声学特征,导致评估结果不准确。此外,现有方法在可解释性方面存在不足,难以理解模型做出判断的原因。缺乏高质量的语音偏好数据也限制了模型的训练和优化。
核心思路:论文的核心思路是构建一个端到端、多方面且可解释的语音LLM(SageLM),能够同时考虑语义和声学信息,并通过基于理由的监督来提高可解释性。通过引入合成偏好数据集SpeechFeedback,缓解数据稀缺问题,并采用两阶段训练策略,提升模型性能。
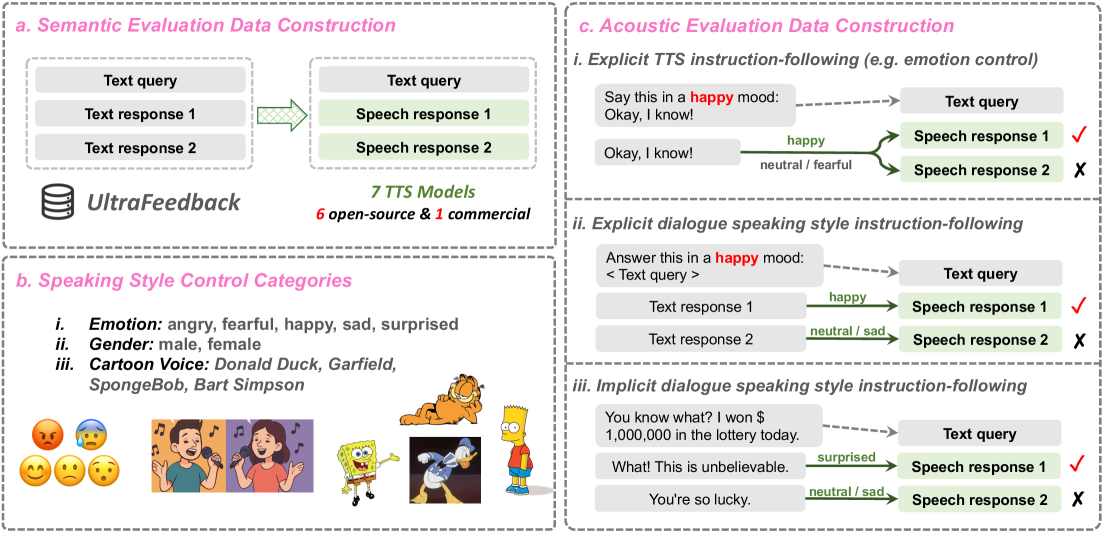
技术框架:SageLM的整体框架包含以下几个主要模块:1) 语音编码器:将输入的语音信号转换为特征表示。2) 文本编码器:将文本信息转换为特征表示。3) 多模态融合模块:将语音和文本特征进行融合,得到统一的表示。4) 理由生成器:根据融合后的特征生成评估理由。5) 评分预测器:根据融合后的特征和生成的理由预测评估分数。模型采用两阶段训练范式,第一阶段在大量数据上进行预训练,第二阶段在SpeechFeedback数据集上进行微调。
关键创新:论文的关键创新点在于:1) 提出了一个端到端的语音LLM,能够同时处理语音和文本信息。2) 引入了基于理由的监督,提高了模型的可解释性。3) 构建了一个合成偏好数据集SpeechFeedback,缓解了数据稀缺问题。与现有方法相比,SageLM能够更准确、更全面地评估S2S LLM的性能。
关键设计:在模型设计方面,论文采用了Transformer架构作为语音和文本编码器的基础。理由生成器采用Seq2Seq模型,损失函数包括交叉熵损失和理由一致性损失。评分预测器采用回归模型,损失函数为均方误差损失。在训练过程中,采用了Adam优化器,学习率设置为1e-4,batch size设置为32。SpeechFeedback数据集包含多种语音评估场景,每个样本都包含语音、文本、理由和评分。
🖼️ 关键图片

📊 实验亮点
SageLM在与人类评估者的协议率上达到了82.79%,显著优于级联方法(提升7.42%)和基于SLM的方法(提升26.20%)。这表明SageLM能够更准确地模拟人类的评估行为,为S2S LLM的评估提供了一个更可靠的工具。SpeechFeedback数据集的引入和两阶段训练策略也显著提升了模型的性能。
🎯 应用场景
SageLM可应用于各种语音相关的任务评估,例如语音识别、语音合成、语音翻译和对话系统。它可以帮助研究人员和开发人员更有效地评估和改进语音模型,从而提高人机交互的质量和效率。此外,SageLM的可解释性使其能够用于诊断模型的问题,并为模型改进提供指导。
📄 摘要(原文)
Speech-to-Speech (S2S) Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling end-to-end spoken dialogue systems. However, evaluating these models remains a fundamental challenge. We propose \texttt{SageLM}, an end-to-end, multi-aspect, and explainable speech LLM for comprehensive S2S LLMs evaluation. First, unlike cascaded approaches that disregard acoustic features, SageLM jointly assesses both semantic and acoustic dimensions. Second, it leverages rationale-based supervision to enhance explainability and guide model learning, achieving superior alignment with evaluation outcomes compared to rule-based reinforcement learning methods. Third, we introduce \textit{SpeechFeedback}, a synthetic preference dataset, and employ a two-stage training paradigm to mitigate the scarcity of speech preference data. Trained on both semantic and acoustic dimensions, SageLM achieves an 82.79\% agreement rate with human evaluators, outperforming cascaded and SLM-based baselines by at least 7.42\% and 26.20\%, respectively.