Addressing Tokenization Inconsistency in Steganography and Watermarking Based on Large Language Models
作者: Ruiyi Yan, Yugo Murawaki
分类: cs.CL
发布日期: 2025-08-28
💡 一句话要点
针对LLM隐写与水印中Token化不一致问题,提出阶梯验证与回滚方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 隐写术 数字水印 Token化不一致性 鲁棒性 阶梯验证 后验回滚
📋 核心要点
- 现有基于LLM的隐写与水印技术易受Token化不一致性影响,导致鲁棒性下降,亟需解决。
- 针对Token化不一致性问题,论文提出阶梯验证隐写方法和后验回滚水印方法,直接消除不一致性。
- 实验结果表明,所提方法在隐写术中提升了流畅性、不可感知性和抗隐写分析能力,在水印中提高了可检测性和鲁棒性。
📝 摘要(中文)
大型语言模型显著提升了文本生成的能力和效率。一方面,它们提高了基于文本的隐写术的质量。另一方面,它们也强调了水印作为防止恶意滥用的保障的重要性。本研究关注隐写术和水印中Alice和Bob之间的Token化不一致性(TI),TI会削弱鲁棒性。我们的研究表明,导致TI的问题token具有两个关键特征:低频性和临时性。基于这些发现,我们提出了两种针对TI消除的定制解决方案:用于隐写术的阶梯验证方法和用于水印的后验回滚方法。实验表明,(1)与隐写术中的传统消歧方法相比,直接解决TI可以提高流畅性、不可感知性和抗隐写分析能力;(2)对于水印,解决TI可以提高可检测性和抵抗攻击的鲁棒性。
🔬 方法详解
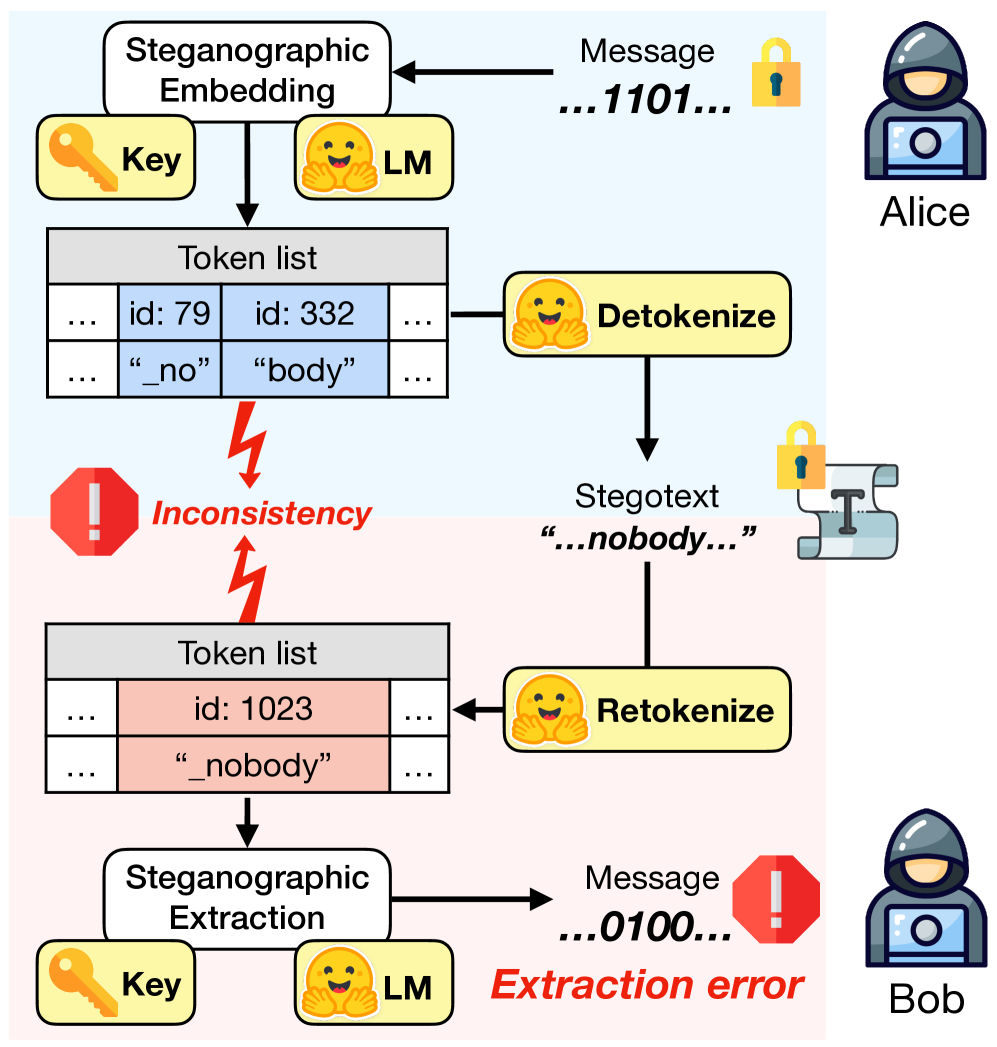
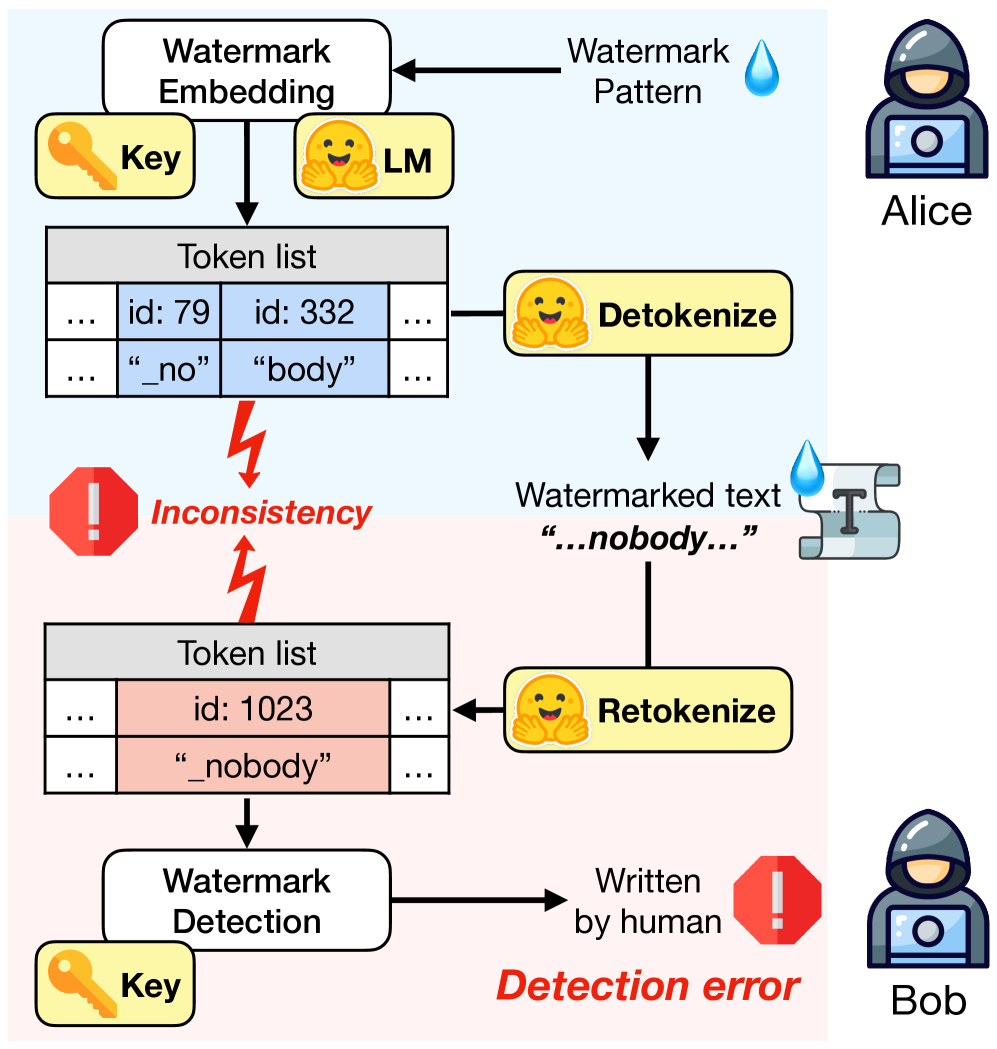
问题定义:论文旨在解决基于大型语言模型(LLM)的文本隐写术和水印技术中,由于Alice(发送方)和Bob(接收方)使用的tokenizers不同而导致的token化不一致性(Tokenization Inconsistency, TI)问题。现有的隐写和水印方法没有充分考虑TI,导致信息隐藏或提取的鲁棒性下降,容易受到攻击或解码失败。
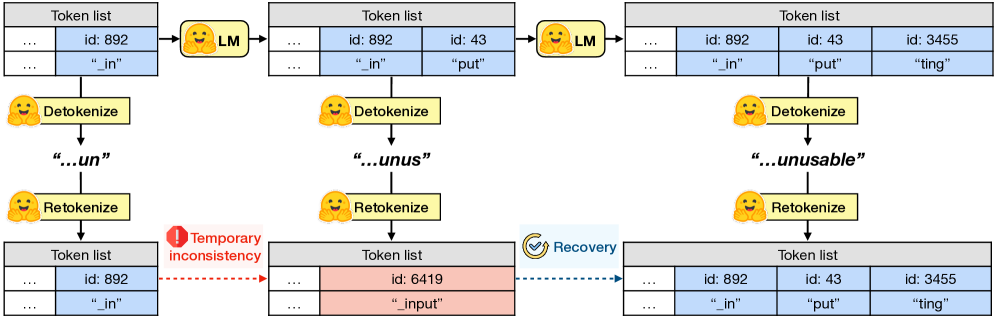
核心思路:论文的核心思路是直接识别并消除导致TI的token。作者发现,这些问题token通常具有两个特点:低频性(infrequency)和临时性(temporariness)。基于此,针对隐写术和水印分别设计了不同的解决方案,以确保信息的可靠传递和提取。
技术框架:对于隐写术,论文提出了阶梯验证方法(stepwise verification method)。该方法在编码过程中,Alice逐步验证生成的token是否会导致Bob解码失败,如果发现TI,则回溯并选择其他token。对于水印,论文提出了后验回滚方法(post-hoc rollback method)。该方法在解码后,Bob检测是否存在TI,如果存在,则尝试回滚到之前的token,以恢复正确的水印信息。
关键创新:论文的关键创新在于直接针对token化不一致性进行处理,而不是像传统方法那样依赖于复杂的编码或解码算法。通过识别和消除问题token,可以更有效地提高隐写术和水印的鲁棒性。此外,论文还发现了问题token的两个关键特征(低频性和临时性),为TI的识别提供了理论基础。
关键设计:在阶梯验证方法中,Alice需要模拟Bob的tokenizer进行验证,这需要维护一个Bob的tokenizer的副本。在后验回滚方法中,Bob需要记录解码过程中的token序列,以便在检测到TI时进行回滚。具体的参数设置和损失函数(如果存在)在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,与传统的消歧方法相比,直接解决TI可以显著提高隐写术的流畅性、不可感知性和抗隐写分析能力。对于水印,解决TI可以提高可检测性和抵抗攻击的鲁棒性。具体的性能提升数据在摘要中未给出,属于未知信息。
🎯 应用场景
该研究成果可应用于数字版权保护、信息隐藏、数据溯源等领域。通过提高基于LLM的隐写术和水印技术的鲁棒性,可以更有效地保护数字内容的安全,防止恶意篡改和非法传播。未来,该技术有望在社交媒体、在线教育、金融服务等领域发挥重要作用。
📄 摘要(原文)
Large language models have significantly enhanced the capacities and efficiency of text generation. On the one hand, they have improved the quality of text-based steganography. On the other hand, they have also underscored the importance of watermarking as a safeguard against malicious misuse. In this study, we focus on tokenization inconsistency (TI) between Alice and Bob in steganography and watermarking, where TI can undermine robustness. Our investigation reveals that the problematic tokens responsible for TI exhibit two key characteristics: infrequency and temporariness. Based on these findings, we propose two tailored solutions for TI elimination: a stepwise verification method for steganography and a post-hoc rollback method for watermarking. Experiments show that (1) compared to traditional disambiguation methods in steganography, directly addressing TI leads to improvements in fluency, imperceptibility, and anti-steganalysis capacity; (2) for watermarking, addressing TI enhances detectability and robustness against attacks.