CAMB: A comprehensive industrial LLM benchmark on civil aviation maintenance
作者: Feng Zhang, Chengjie Pang, Yuehan Zhang, Chenyu Luo
分类: cs.CL
发布日期: 2025-08-28
🔗 代码/项目: GITHUB
💡 一句话要点
提出CAMB:一个全面的民用航空维护工业LLM基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 民用航空维护 基准测试 检索增强生成 领域知识 复杂推理
📋 核心要点
- 现有LLM评估侧重于数学和编码推理,缺乏针对民用航空维护等专业领域的评估工具。
- 论文提出CAMB基准测试,旨在标准化评估LLM在民用航空维护中的能力,识别知识和推理差距。
- 实验评估了现有向量嵌入模型和LLM在民用航空维护场景下的性能,验证了CAMB的有效性,并开源了基准测试。
📝 摘要(中文)
民用航空维护是一个具有严格行业标准的领域。其中,维护程序和故障排除是关键的、知识密集型的任务,需要复杂的推理。为了解决大型语言模型(LLM)在该垂直领域缺乏专业评估工具的问题,我们提出并开发了一个专门为民用航空维护设计的工业级基准测试。该基准测试具有双重目的:它提供了一个标准化的工具来衡量LLM在民用航空维护中的能力,识别领域知识和复杂推理方面的具体差距。通过查明这些不足,该基准测试为有针对性的改进工作(例如,领域特定的微调、RAG优化或专门的提示工程)奠定了基础,最终促进了民用航空维护领域更智能解决方案的进步。我们的工作解决了当前LLM评估中的一个重大差距,即主要关注数学和编码推理任务。此外,鉴于检索增强生成(RAG)系统是目前实际应用中的主要解决方案,我们利用此基准来评估现有著名的向量嵌入模型和LLM在民用航空维护场景中的性能。通过实验探索和分析,我们证明了我们的基准测试在评估该领域模型性能方面的有效性,并且我们开源了这个评估基准测试和代码,以促进进一步的研究和开发。
🔬 方法详解
问题定义:论文旨在解决民用航空维护领域缺乏针对LLM的专业评估工具的问题。现有LLM评估主要集中在数学和编码推理,忽略了民航维护中知识密集型和推理复杂性高的任务需求。这导致无法有效评估和改进LLM在该领域的应用。
核心思路:论文的核心思路是构建一个专门针对民用航空维护的工业级基准测试CAMB。通过设计包含领域知识和复杂推理的测试用例,CAMB能够更准确地评估LLM在该领域的性能,并识别其知识和推理能力的不足之处。这为后续的领域特定微调、RAG优化等改进工作提供了基础。
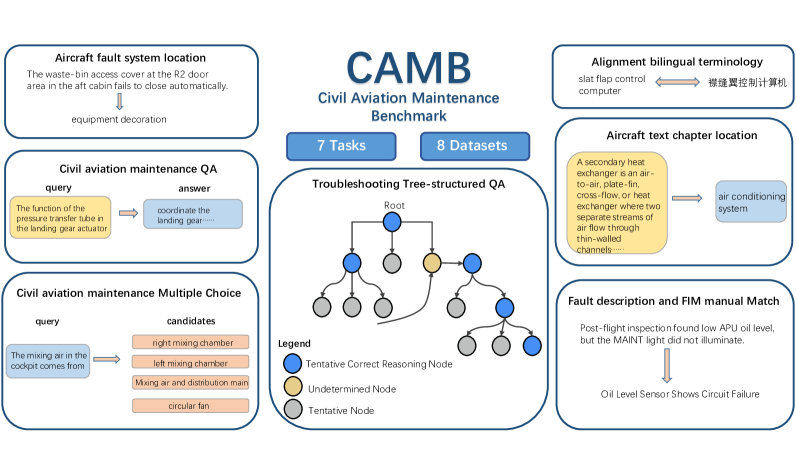
技术框架:CAMB基准测试包含一系列精心设计的测试用例,涵盖民用航空维护的各个方面,例如维护程序、故障排除等。该基准测试可以用于评估各种LLM和向量嵌入模型在民航维护场景下的性能。评估流程包括:1) 将测试用例输入LLM或RAG系统;2) 评估模型生成的答案的准确性和完整性;3) 分析模型的错误类型和原因,从而识别模型的不足之处。
关键创新:CAMB的关键创新在于其领域特定性和工业级标准。与通用的LLM基准测试不同,CAMB专门针对民用航空维护领域设计,能够更准确地反映LLM在该领域的实际应用能力。此外,CAMB的设计参考了行业标准和实际维护流程,使其更具实用价值。
关键设计:CAMB的设计细节包括:测试用例的选取和构建,评估指标的选择,以及评估流程的标准化。测试用例的选取需要覆盖民航维护的各个方面,并具有一定的难度和挑战性。评估指标需要能够准确反映LLM的性能,例如准确率、召回率、F1值等。评估流程需要标准化,以保证评估结果的可靠性和可重复性。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了CAMB基准测试的有效性。实验结果表明,CAMB能够有效区分不同LLM和向量嵌入模型在民用航空维护任务中的性能差异。此外,实验还揭示了现有LLM在民航维护领域存在的知识和推理能力不足,为后续的改进工作提供了方向。
🎯 应用场景
该研究成果可应用于民用航空维护领域,帮助评估和改进LLM在该领域的应用。例如,可以使用CAMB来评估不同LLM在民航维护任务中的性能,从而选择最合适的模型。此外,CAMB还可以用于指导LLM的领域特定微调和RAG优化,从而提高LLM在民航维护领域的智能化水平。未来,该研究可以扩展到其他专业领域,为LLM的行业应用提供更有效的评估工具。
📄 摘要(原文)
Civil aviation maintenance is a domain characterized by stringent industry standards. Within this field, maintenance procedures and troubleshooting represent critical, knowledge-intensive tasks that require sophisticated reasoning. To address the lack of specialized evaluation tools for large language models (LLMs) in this vertical, we propose and develop an industrial-grade benchmark specifically designed for civil aviation maintenance. This benchmark serves a dual purpose: It provides a standardized tool to measure LLM capabilities within civil aviation maintenance, identifying specific gaps in domain knowledge and complex reasoning. By pinpointing these deficiencies, the benchmark establishes a foundation for targeted improvement efforts (e.g., domain-specific fine-tuning, RAG optimization, or specialized prompt engineering), ultimately facilitating progress toward more intelligent solutions within civil aviation maintenance. Our work addresses a significant gap in the current LLM evaluation, which primarily focuses on mathematical and coding reasoning tasks. In addition, given that Retrieval-Augmented Generation (RAG) systems are currently the dominant solutions in practical applications , we leverage this benchmark to evaluate existing well-known vector embedding models and LLMs for civil aviation maintenance scenarios. Through experimental exploration and analysis, we demonstrate the effectiveness of our benchmark in assessing model performance within this domain, and we open-source this evaluation benchmark and code to foster further research and development:https://github.com/CamBenchmark/cambenchmark