DeepMEL: A Multi-Agent Collaboration Framework for Multimodal Entity Linking
作者: Fang Wang, Tianwei Yan, Zonghao Yang, Minghao Hu, Jun Zhang, Zhunchen Luo, Xiaoying Bai
分类: cs.CL, cs.AI, cs.MA
发布日期: 2025-08-21
💡 一句话要点
DeepMEL:提出一种多智能体协作框架,用于解决多模态实体链接任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态实体链接 多智能体协作 跨模态融合 大型语言模型 大型视觉模型
📋 核心要点
- 现有方法在多模态实体链接中存在上下文信息不完整、跨模态融合粗糙等问题,限制了性能。
- DeepMEL提出多智能体协作框架,通过角色分工和动态协调,实现文本和视觉模态的有效对齐和消歧。
- 实验结果表明,DeepMEL在多个数据集上取得了SOTA性能,准确率提升显著,验证了框架的有效性。
📝 摘要(中文)
多模态实体链接(MEL)旨在将文本和视觉提及与多模态知识图谱中的实体相关联。现有方法面临着上下文信息不完整、跨模态融合粗糙以及难以联合大型语言模型(LLM)和大型视觉模型(LVM)等挑战。为了解决这些问题,我们提出了一种基于多智能体协作推理的新框架DeepMEL,通过角色专业化分工策略,实现文本和视觉模态的有效对齐和消歧。DeepMEL集成了四个专业智能体,即Modal-Fuser、Candidate-Adapter、Entity-Clozer和Role-Orchestrator,通过专业角色和动态协调完成端到端的跨模态链接。DeepMEL采用双模态对齐路径,将LLM生成的细粒度文本语义与LVM提取的结构化图像表示相结合,显著缩小模态差距。我们设计了一种自适应迭代策略,结合基于工具的检索和语义推理能力,动态优化候选集并平衡召回率和精度。DeepMEL还将MEL任务统一为结构化的完形填空提示,以降低解析复杂性并增强语义理解。在五个公共基准数据集上的大量实验表明,DeepMEL实现了最先进的性能,ACC提高了1%-57%。消融研究验证了所有模块的有效性。
🔬 方法详解
问题定义:论文旨在解决多模态实体链接(MEL)任务,即如何将文本和视觉信息与知识图谱中的实体进行关联。现有方法的痛点在于无法充分利用上下文信息,跨模态融合方式较为粗糙,并且难以有效结合大型语言模型(LLM)和大型视觉模型(LVM)。
核心思路:论文的核心思路是采用多智能体协作的方式,将MEL任务分解为多个子任务,并由不同的智能体负责。通过智能体之间的协作和信息交互,实现更有效的跨模态对齐和实体消歧。这种设计借鉴了人类解决复杂问题的模式,即分工合作,协同完成。
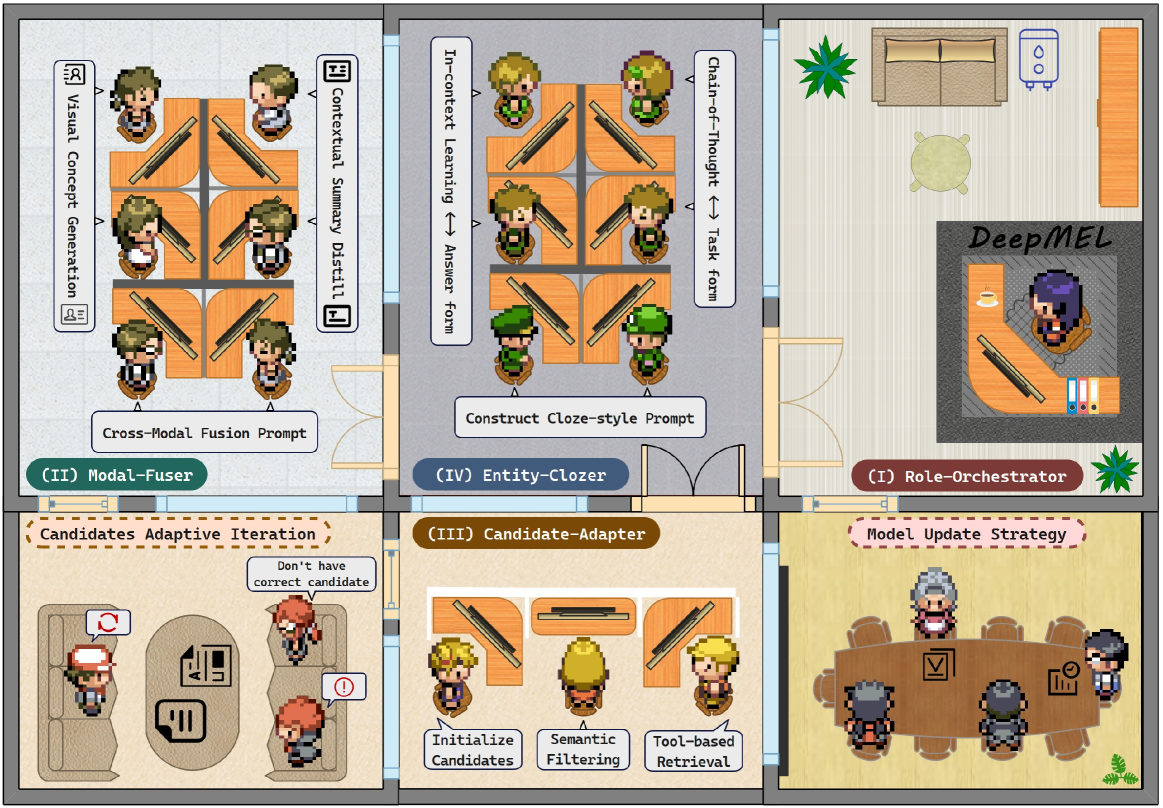
技术框架:DeepMEL框架包含四个主要智能体:Modal-Fuser(模态融合器)、Candidate-Adapter(候选适配器)、Entity-Clozer(实体完形填空器)和Role-Orchestrator(角色协调器)。Modal-Fuser负责融合文本和视觉信息;Candidate-Adapter负责动态优化候选实体集合;Entity-Clozer将MEL任务转化为完形填空任务,进行实体预测;Role-Orchestrator负责协调各个智能体的行为,控制迭代过程。整体流程是,首先由Modal-Fuser进行模态融合,然后Candidate-Adapter生成候选实体,接着Entity-Clozer进行实体预测,最后Role-Orchestrator根据预测结果调整各个智能体的行为,进行迭代优化。
关键创新:DeepMEL的关键创新在于多智能体协作框架的设计。通过将MEL任务分解为多个子任务,并由不同的智能体负责,可以更有效地利用各种信息,实现更精确的实体链接。此外,论文还提出了双模态对齐路径,将LLM生成的细粒度文本语义与LVM提取的结构化图像表示相结合,显著缩小了模态差距。将MEL任务转化为结构化的完形填空提示,降低了解析复杂性,增强了语义理解。
关键设计:论文设计了一种自适应迭代策略,结合基于工具的检索和语义推理能力,动态优化候选集并平衡召回率和精度。具体来说,Role-Orchestrator会根据Entity-Clozer的预测结果,调整Candidate-Adapter的候选集生成策略,以及Modal-Fuser的模态融合权重。此外,Entity-Clozer采用了一种结构化的完形填空提示,将实体链接任务转化为一个语言模型可以更容易处理的任务。
🖼️ 关键图片

📊 实验亮点
DeepMEL在五个公共基准数据集上取得了显著的性能提升,ACC指标平均提升了1%-57%。例如,在某个数据集上,DeepMEL的ACC达到了SOTA水平,超过了现有最佳方法多个百分点。消融实验验证了各个模块的有效性,证明了多智能体协作框架的优越性。
🎯 应用场景
DeepMEL可应用于多种需要多模态信息融合的场景,例如:图像检索、视频理解、社交媒体分析、智能客服等。通过将文本和视觉信息与知识图谱中的实体进行关联,可以提高信息检索的准确性和效率,增强对复杂场景的理解能力,并为用户提供更智能化的服务。未来,该研究可以进一步扩展到其他模态,例如音频、3D模型等,以支持更广泛的应用场景。
📄 摘要(原文)
Multimodal Entity Linking (MEL) aims to associate textual and visual mentions with entities in a multimodal knowledge graph. Despite its importance, current methods face challenges such as incomplete contextual information, coarse cross-modal fusion, and the difficulty of jointly large language models (LLMs) and large visual models (LVMs). To address these issues, we propose DeepMEL, a novel framework based on multi-agent collaborative reasoning, which achieves efficient alignment and disambiguation of textual and visual modalities through a role-specialized division strategy. DeepMEL integrates four specialized agents, namely Modal-Fuser, Candidate-Adapter, Entity-Clozer and Role-Orchestrator, to complete end-to-end cross-modal linking through specialized roles and dynamic coordination. DeepMEL adopts a dual-modal alignment path, and combines the fine-grained text semantics generated by the LLM with the structured image representation extracted by the LVM, significantly narrowing the modal gap. We design an adaptive iteration strategy, combines tool-based retrieval and semantic reasoning capabilities to dynamically optimize the candidate set and balance recall and precision. DeepMEL also unifies MEL tasks into a structured cloze prompt to reduce parsing complexity and enhance semantic comprehension. Extensive experiments on five public benchmark datasets demonstrate that DeepMEL achieves state-of-the-art performance, improving ACC by 1%-57%. Ablation studies verify the effectiveness of all modules.