CARFT: Boosting LLM Reasoning via Contrastive Learning with Annotated Chain-of-Thought-based Reinforced Fine-Tuning
作者: Wenqiao Zhu, Ji Liu, Rongjuncheng Zhang, Haipang Wu, Yulun Zhang
分类: cs.CL, cs.AI
发布日期: 2025-08-21 (更新: 2025-09-08)
备注: 14 pages, to appear in EMNLP25
🔗 代码/项目: GITHUB
💡 一句话要点
CARFT:通过对比学习与基于CoT的强化微调提升LLM推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 强化学习 对比学习 思维链 微调 自然语言处理
📋 核心要点
- 现有基于强化学习的LLM微调方法忽略了标注的CoT,导致训练不稳定和性能下降。
- CARFT通过对比学习CoT表示,设计对比信号指导微调,充分利用标注CoT并稳定训练。
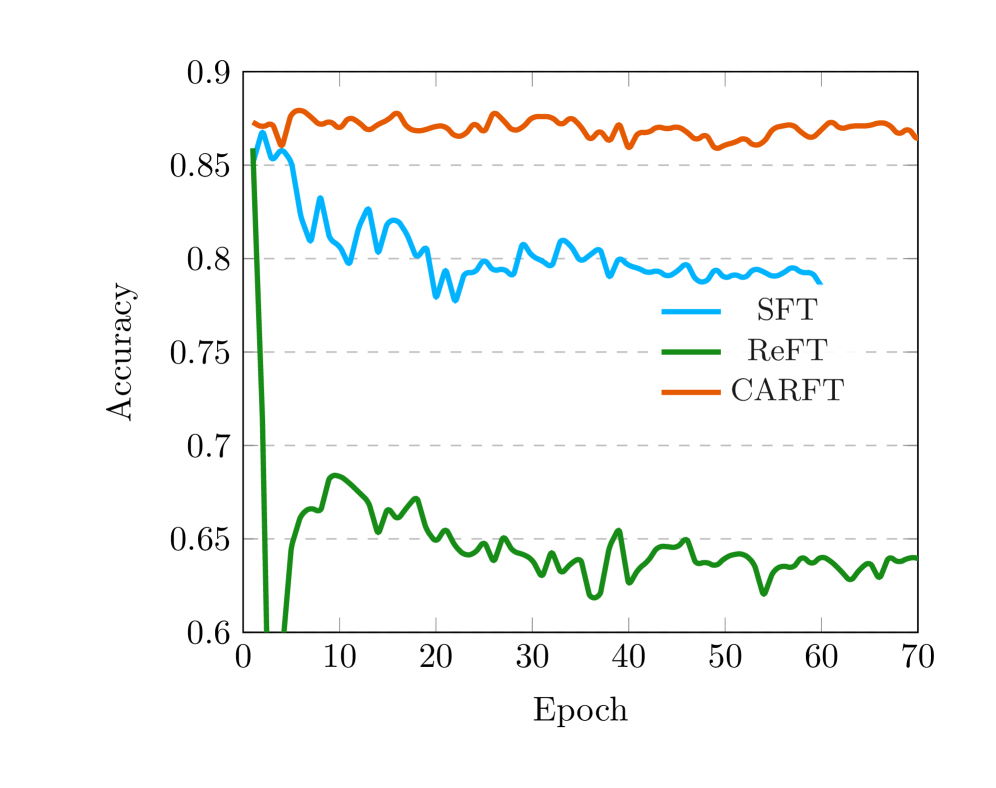
- 实验表明,CARFT在鲁棒性、性能和效率方面均优于现有方法,性能提升高达10.15%。
📝 摘要(中文)
大型语言模型(LLM)的推理能力在其广泛应用中至关重要。为了增强LLM的推理性能,研究者提出了多种基于强化学习(RL)的微调方法,以解决仅通过监督微调(SFT)训练的LLM泛化能力有限的问题。然而,这些方法存在两个主要局限性。首先,传统的基于RL的方法忽略了带标注的思维链(CoT),并引入了不稳定的推理路径采样,这通常会导致模型崩溃、训练过程不稳定和性能欠佳。其次,现有的SFT方法通常过度强调带标注的CoT,可能由于对潜在CoT的利用不足而导致性能下降。本文提出了一种基于带标注CoT的强化微调的对比学习方法,即CARFT,以增强LLM的推理性能,同时解决上述局限性。具体而言,我们提出学习每个CoT的表示。基于此表示,我们设计了新颖的对比信号来指导微调过程。我们的方法不仅充分利用了可用的带标注CoT,还通过结合额外的无监督学习信号来稳定微调过程。我们通过三个基线方法、两个基础模型和两个数据集进行了全面的实验和深入的分析,证明了CARFT在鲁棒性、性能(高达10.15%)和效率(高达30.62%)方面的显著优势。代码可在https://github.com/WNQzhu/CARFT获取。
🔬 方法详解
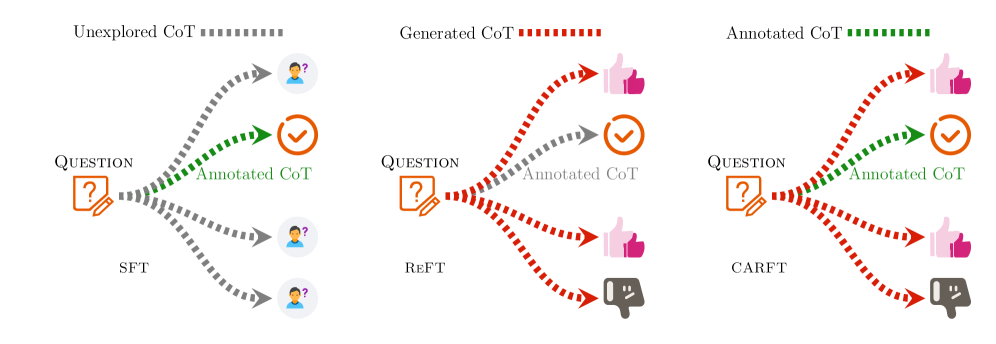
问题定义:现有基于强化学习的LLM微调方法在提升推理能力时,存在对标注CoT利用不足和训练过程不稳定的问题。具体来说,传统方法忽略了标注的CoT信息,并且不稳定的推理路径采样容易导致模型训练崩溃和性能下降。同时,监督微调方法又过度依赖标注CoT,限制了模型探索潜在CoT的能力。
核心思路:CARFT的核心思路是通过对比学习来学习CoT的表示,并利用这些表示来指导强化微调过程。通过对比学习,模型可以更好地区分不同的CoT,并学习到更鲁棒的CoT表示。然后,利用这些表示设计对比损失,从而在强化微调过程中稳定训练,并充分利用标注CoT信息。
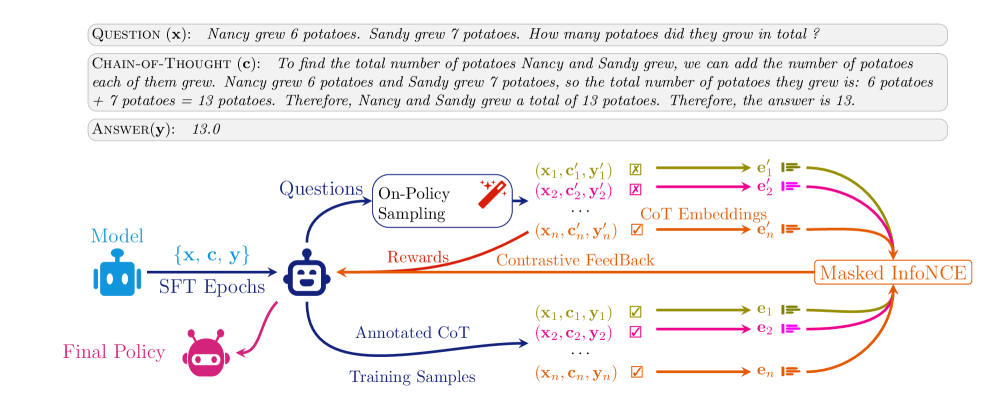
技术框架:CARFT的整体框架包括以下几个主要阶段:1) 使用标注CoT数据进行监督微调,初始化模型参数;2) 学习CoT表示,通过对比学习区分不同的CoT;3) 使用强化学习进行微调,同时引入对比损失,以稳定训练过程并充分利用标注CoT信息。该框架结合了监督学习、对比学习和强化学习的优点,从而提升LLM的推理能力。
关键创新:CARFT最重要的技术创新点在于引入了对比学习来学习CoT表示,并将其用于指导强化微调过程。与现有方法相比,CARFT不仅充分利用了标注CoT信息,还通过对比学习提高了CoT表示的鲁棒性,从而稳定了强化微调过程。此外,CARFT还设计了新颖的对比损失,以更好地指导模型的训练。
关键设计:CARFT的关键设计包括:1) CoT表示的学习方式,例如可以使用Transformer编码器来学习CoT表示;2) 对比损失的设计,例如可以使用InfoNCE损失来区分不同的CoT;3) 强化学习算法的选择,例如可以使用PPO算法进行微调;4) 超参数的设置,例如对比损失的权重、强化学习的奖励函数等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CARFT在两个数据集上均取得了显著的性能提升。与基线方法相比,CARFT在性能上提升高达10.15%,在效率上提升高达30.62%。此外,CARFT还表现出更好的鲁棒性,能够更好地应对噪声数据和对抗攻击。这些结果表明,CARFT是一种有效的LLM推理能力提升方法。
🎯 应用场景
CARFT的潜在应用领域包括问答系统、文本摘要、机器翻译等需要复杂推理能力的自然语言处理任务。该研究的实际价值在于提升了LLM的推理能力和鲁棒性,使其能够更好地解决实际问题。未来,CARFT可以应用于各种需要LLM进行推理的场景,例如智能客服、自动驾驶等。
📄 摘要(原文)
Reasoning capability plays a significantly critical role in the the broad applications of Large Language Models (LLMs). To enhance the reasoning performance of LLMs, diverse Reinforcement Learning (RL)-based fine-tuning approaches have been proposed to address the limited generalization capability of LLMs trained solely via Supervised Fine-Tuning (SFT). Despite their effectiveness, two major limitations hinder the advancement of LLMs. First, vanilla RL-based approaches ignore annotated Chain-of-Thought (CoT) and incorporate unstable reasoning path sampling, which typically results in model collapse, unstable training process, and suboptimal performance. Second, existing SFT approaches generally overemphasize the annotated CoT, potentially leading to performance degradation due to insufficient exploitation of potential CoT. In this paper, we propose a Contrastive learning with annotated CoT-based Reinforced Fine-Tuning approach, i.e., \TheName{}, to enhance the reasoning performance of LLMs while addressing the aforementioned limitations. Specifically, we propose learning a representation for each CoT. Based on this representation, we design novel contrastive signals to guide the fine-tuning process. Our approach not only fully exploits the available annotated CoT but also stabilizes the fine-tuning procedure by incorporating an additional unsupervised learning signal. We conduct comprehensive experiments and in-depth analysis with three baseline approaches, two foundation models, and two datasets to demonstrate significant advantages of \TheName{} in terms of robustness, performance (up to 10.15\%), and efficiency (up to 30.62\%). Code is available at https://github.com/WNQzhu/CARFT.