Position Bias Mitigates Position Bias:Mitigate Position Bias Through Inter-Position Knowledge Distillation
作者: Yifei Wang, Feng Xiong, Yong Wang, Linjing Li, Xiangxiang Chu, Daniel Dajun Zeng
分类: cs.CL
发布日期: 2025-08-21 (更新: 2025-09-17)
备注: EMNLP 2025 Oral
💡 一句话要点
提出Pos2Distill框架,通过位置间知识蒸馏缓解长文本理解中的位置偏差问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 位置偏差 知识蒸馏 长文本理解 检索 推理 自然语言处理 模型优化
📋 核心要点
- 长文本理解中存在位置偏差,模型对不同位置的敏感度差异大,影响性能。
- Pos2Distill框架通过知识蒸馏,将优势位置的能力迁移到劣势位置,缓解位置偏差。
- Pos2Distill在检索和推理任务上均取得了显著的性能提升,并具备良好的跨任务泛化能力。
📝 摘要(中文)
位置偏差(PB)表现为模型对不同上下文位置的敏感度不一致,严重影响了长文本的理解和处理能力。以往的研究主要通过修改底层架构或采用大量的上下文感知训练来解决PB问题。然而,前者未能有效消除显著的性能差距,而后者则带来了巨大的数据和计算开销。为了有效解决PB问题,我们提出了Pos2Distill,一个位置到位置的知识蒸馏框架。Pos2Distill将优势位置的卓越能力转移到较差的位置,从而缩小巨大的性能差距。其概念原理是利用固有的、位置诱导的差异来抵消PB本身。我们识别了PB在检索和推理范式下的不同表现形式,从而设计了两个专门的实例:Pos2Distill-R¹和Pos2Distill-R²,两者都基于这一核心原则。通过采用Pos2Distill方法,我们在长文本检索和推理任务中实现了增强的均匀性和显著的性能提升。至关重要的是,这两个专门的系统都表现出强大的跨任务泛化能力,同时在各自的任务上实现了卓越的性能。
🔬 方法详解
问题定义:论文旨在解决长文本处理中普遍存在的位置偏差(Positional Bias, PB)问题。位置偏差指的是模型对于不同位置的上下文信息敏感度不一致,导致模型在处理长文本时,对不同位置的信息利用程度不同,从而影响整体性能。现有的方法,如修改模型架构或进行大量上下文感知训练,要么无法有效消除性能差距,要么需要巨大的计算资源和数据量。
核心思路:Pos2Distill的核心思路是利用知识蒸馏,将模型在优势位置(即模型表现较好的位置)学到的知识迁移到劣势位置(即模型表现较差的位置)。通过这种方式,可以使模型对所有位置的上下文信息具有更均匀的敏感度,从而缓解位置偏差。其基本思想是“以偏差制偏差”,利用位置间的性能差异来抵消位置偏差本身。
技术框架:Pos2Distill框架包含两个主要变体,分别针对检索(Retrieval)和推理(Reasoning)任务进行了优化:Pos2Distill-R¹和Pos2Distill-R²。整体流程是首先确定优势位置和劣势位置,然后使用优势位置的模型作为教师模型,劣势位置的模型作为学生模型,通过知识蒸馏的方式进行训练。框架的具体实现细节会根据检索和推理任务的不同而有所调整。
关键创新:Pos2Distill的关键创新在于其利用位置间的性能差异进行知识蒸馏,从而缓解位置偏差。与以往直接修改模型结构或增加训练数据的方法不同,Pos2Distill充分利用了模型自身在不同位置上的表现差异,通过知识迁移的方式来提升整体性能。这种方法不仅有效,而且计算成本相对较低。
关键设计:Pos2Distill-R¹和Pos2Distill-R²的具体设计细节未知,但可以推测其关键设计包括:如何确定优势位置和劣势位置(可能基于模型在验证集上的表现),如何设计知识蒸馏的损失函数(可能包括预测结果的相似性损失和中间层特征的对齐损失),以及如何平衡教师模型和学生模型的权重。
🖼️ 关键图片
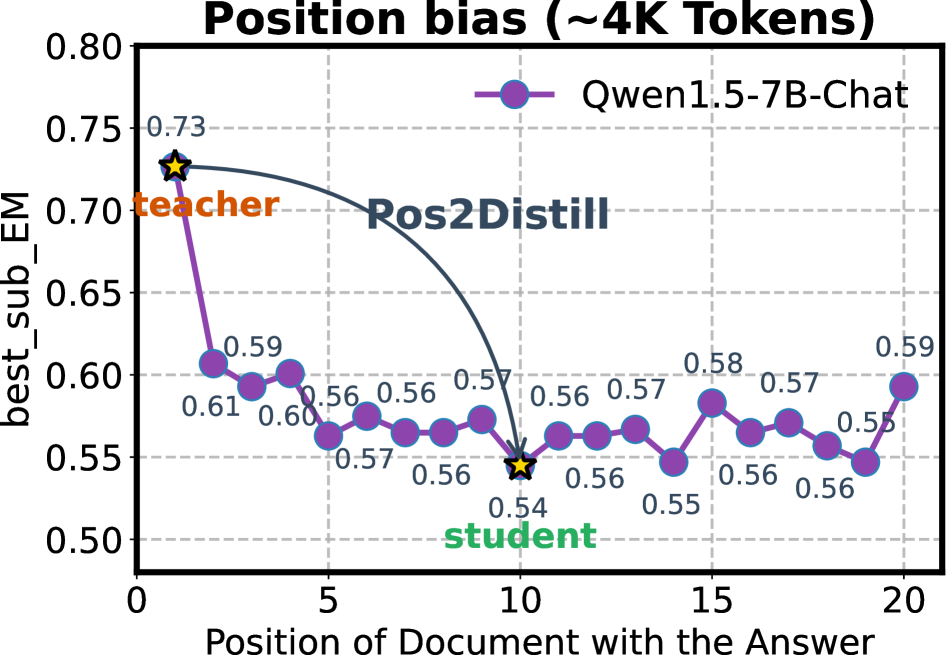
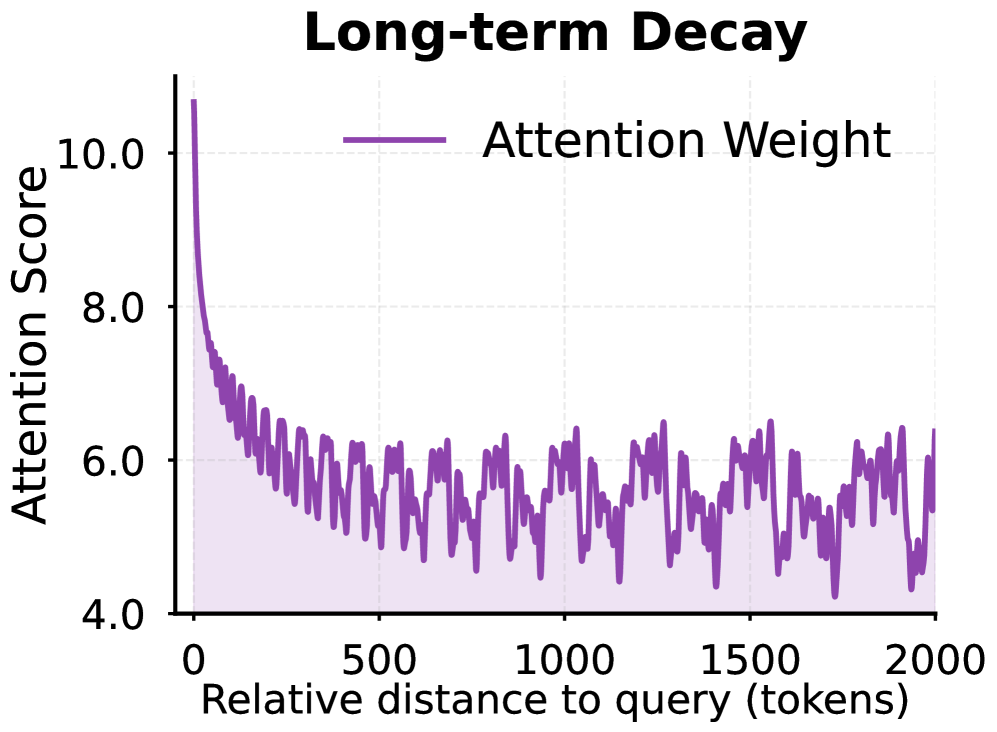
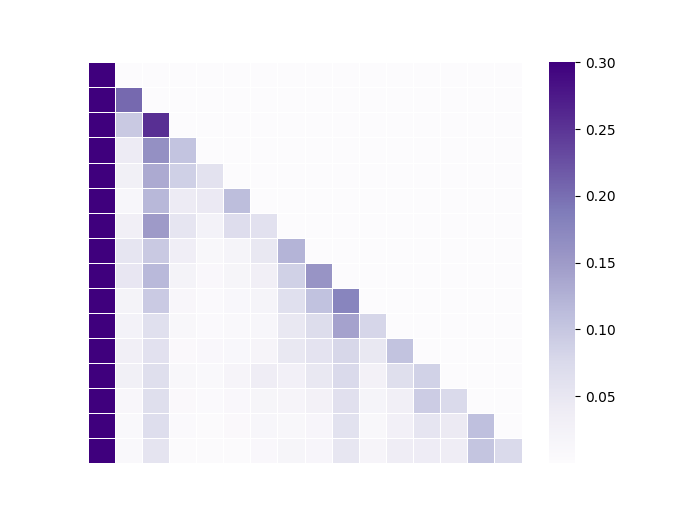
📊 实验亮点
论文提出的Pos2Distill框架在长文本检索和推理任务上取得了显著的性能提升。具体的数据和提升幅度未知,但摘要中强调了“增强的均匀性”和“显著的性能提升”,以及“强大的跨任务泛化能力”。这意味着Pos2Distill不仅在特定任务上表现出色,而且能够很好地迁移到其他相关任务。
🎯 应用场景
Pos2Distill框架可应用于各种需要处理长文本的自然语言处理任务,例如长文档检索、阅读理解、文本摘要、对话生成等。该方法能够有效缓解位置偏差问题,提高模型对长文本的理解和处理能力,从而提升相关应用的性能和用户体验。该研究对于提升长文本处理模型的鲁棒性和泛化能力具有重要意义。
📄 摘要(原文)
Positional bias (PB), manifesting as non-uniform sensitivity across different contextual locations, significantly impairs long-context comprehension and processing capabilities. Previous studies have addressed PB either by modifying the underlying architectures or by employing extensive contextual awareness training. However, the former approach fails to effectively eliminate the substantial performance disparities, while the latter imposes significant data and computational overhead. To address PB effectively, we introduce \textbf{Pos2Distill}, a position to position knowledge distillation framework. Pos2Distill transfers the superior capabilities from advantageous positions to less favorable ones, thereby reducing the huge performance gaps. The conceptual principle is to leverage the inherent, position-induced disparity to counteract the PB itself. We identify distinct manifestations of PB under \textbf{\textsc{r}}etrieval and \textbf{\textsc{r}}easoning paradigms, thereby designing two specialized instantiations: \emph{Pos2Distill-R\textsuperscript{1}} and \emph{Pos2Distill-R\textsuperscript{2}} respectively, both grounded in this core principle. By employing the Pos2Distill approach, we achieve enhanced uniformity and significant performance gains across all contextual positions in long-context retrieval and reasoning tasks. Crucially, both specialized systems exhibit strong cross-task generalization mutually, while achieving superior performance on their respective tasks.