SafetyFlow: An Agent-Flow System for Automated LLM Safety Benchmarking
作者: Xiangyang Zhu, Yuan Tian, Chunyi Li, Kaiwei Zhang, Wei Sun, Guangtao Zhai
分类: cs.CL
发布日期: 2025-08-21
备注: Code and dataset are available at https://github.com/yangyangyang127/SafetyFlow
💡 一句话要点
提出SafetyFlow,一个全自动Agent-Flow系统,用于大规模语言模型(LLM)安全基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM安全 自动化基准测试 Agent-Flow系统 安全评估 大型语言模型
📋 核心要点
- 现有LLM安全基准依赖人工标注,耗时耗力,且存在冗余和难度不足的问题。
- SafetyFlow通过Agent-Flow系统,自动化构建LLM安全基准,降低成本并提高效率。
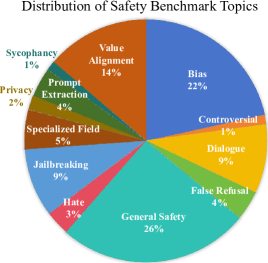
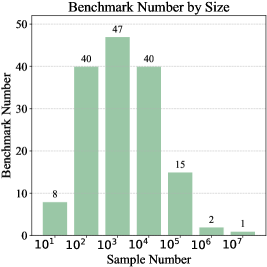
- SafetyFlowBench包含23,446个查询,实验验证了其低冗余和强区分能力,并评估了49个LLM的安全性。
📝 摘要(中文)
大型语言模型(LLM)的快速普及,对可靠的安全评估以发现模型漏洞的需求日益增加。为此,已经提出了许多LLM安全评估基准。然而,现有的基准通常依赖于劳动密集型的手动管理,导致过多的时间和资源消耗,并且存在显著的冗余和有限的难度。为了缓解这些问题,我们引入了SafetyFlow,这是第一个旨在自动化构建LLM安全基准的agent-flow系统。SafetyFlow可以在没有任何人工干预的情况下,仅用四天时间自动构建一个全面的安全基准,通过协调七个专门的agent,显著降低时间和资源成本。SafetyFlow的agent配备了多功能工具,确保过程和成本的可控性,同时将人类专业知识集成到自动管道中。最终构建的数据集SafetyFlowBench包含23,446个查询,具有低冗余和强大的区分能力。我们的贡献包括第一个完全自动化的基准测试管道和一个全面的安全基准。我们在我们的数据集上评估了49个先进LLM的安全性,并进行了广泛的实验来验证我们的功效和效率。
🔬 方法详解
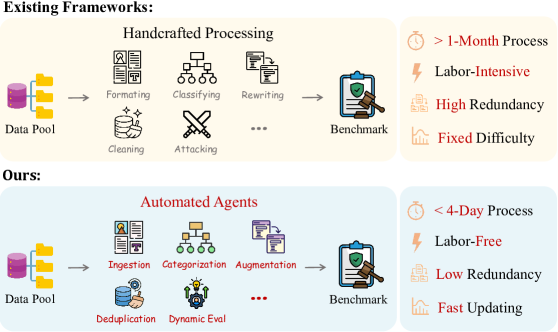
问题定义:现有LLM安全基准的构建严重依赖人工,导致成本高昂、耗时过长,并且数据集存在冗余和难度不足的问题。这些问题限制了LLM安全评估的效率和有效性。因此,需要一种自动化的方法来构建高质量的安全基准。
核心思路:SafetyFlow的核心思路是利用多个专门设计的agent,通过协同工作,模拟人工构建安全基准的流程。每个agent负责特定的任务,例如生成恶意query、评估query的有效性等。通过将这些agent组合成一个流程,可以实现全自动化的基准构建。
技术框架:SafetyFlow系统包含七个agent,它们协同工作以构建安全基准。这些agent包括:目标设定Agent、场景构建Agent、攻击生成Agent、过滤Agent、难度调整Agent、多样性增强Agent和质量评估Agent。这些agent通过预定义的流程进行协调,自动生成、过滤、调整和评估安全基准数据。
关键创新:SafetyFlow的关键创新在于其全自动化的Agent-Flow系统。与传统的手动构建方法相比,SafetyFlow无需人工干预,可以显著降低时间和资源成本。此外,SafetyFlow还集成了人类专业知识,通过可控的流程和工具,确保构建的基准具有高质量和多样性。
关键设计:SafetyFlow的agent配备了各种工具,例如用于生成恶意query的prompt模板、用于评估query有效性的评估模型等。每个agent都经过精心设计,以确保其能够有效地完成其分配的任务。此外,SafetyFlow还采用了多种策略来提高基准的多样性和难度,例如使用不同的prompt模板、调整query的难度级别等。具体的参数设置和损失函数等细节在论文中未详细说明,属于未知内容。
🖼️ 关键图片
📊 实验亮点
SafetyFlow在四天内自动构建了一个包含23,446个查询的安全基准SafetyFlowBench,无需人工干预。实验表明,SafetyFlowBench具有低冗余和强区分能力,能够有效评估LLM的安全性。在SafetyFlowBench上评估了49个先进的LLM,验证了SafetyFlow的有效性和效率。具体的性能提升数据未知。
🎯 应用场景
SafetyFlow可用于自动化构建LLM安全评估基准,帮助研究人员和开发者更高效地评估和改进LLM的安全性。该系统可以应用于各种LLM安全场景,例如检测LLM的有害内容生成、防止LLM被恶意利用等。未来,SafetyFlow可以扩展到其他类型的AI系统安全评估。
📄 摘要(原文)
The rapid proliferation of large language models (LLMs) has intensified the requirement for reliable safety evaluation to uncover model vulnerabilities. To this end, numerous LLM safety evaluation benchmarks are proposed. However, existing benchmarks generally rely on labor-intensive manual curation, which causes excessive time and resource consumption. They also exhibit significant redundancy and limited difficulty. To alleviate these problems, we introduce SafetyFlow, the first agent-flow system designed to automate the construction of LLM safety benchmarks. SafetyFlow can automatically build a comprehensive safety benchmark in only four days without any human intervention by orchestrating seven specialized agents, significantly reducing time and resource cost. Equipped with versatile tools, the agents of SafetyFlow ensure process and cost controllability while integrating human expertise into the automatic pipeline. The final constructed dataset, SafetyFlowBench, contains 23,446 queries with low redundancy and strong discriminative power. Our contribution includes the first fully automated benchmarking pipeline and a comprehensive safety benchmark. We evaluate the safety of 49 advanced LLMs on our dataset and conduct extensive experiments to validate our efficacy and efficiency.