Dream 7B: Diffusion Large Language Models
作者: Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, Lingpeng Kong
分类: cs.CL
发布日期: 2025-08-21
💡 一句话要点
Dream 7B:提出一种基于扩散的更强大的开放域大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 大语言模型 文本生成 离散扩散 去噪 并行生成 上下文自适应 噪声调度
📋 核心要点
- 现有自回归语言模型在长文本生成和并行计算方面存在局限性,扩散模型为解决这些问题提供了新思路。
- Dream 7B通过离散扩散建模,迭代地对序列进行去噪,实现并行生成,提升了生成效率和灵活性。
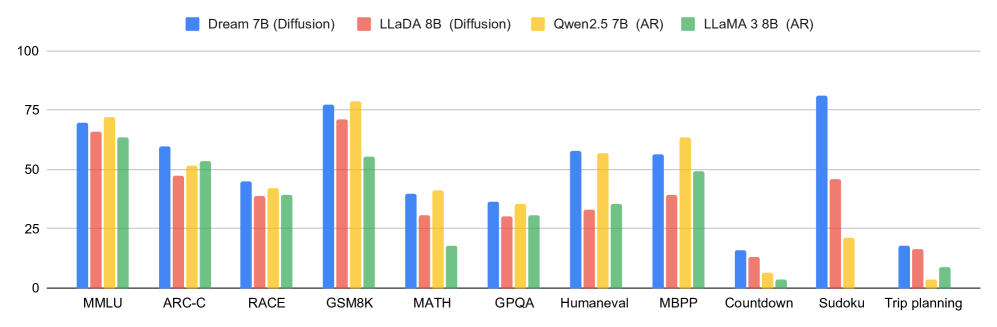
- 实验表明,Dream 7B在多种任务上超越了现有扩散语言模型,展示了其强大的规划能力和推理灵活性。
📝 摘要(中文)
本文介绍Dream 7B,迄今为止最强大的开放域扩散大语言模型。与按顺序生成token的自回归(AR)模型不同,Dream 7B采用离散扩散建模,通过迭代去噪并行地优化序列。我们的模型在通用、数学和编码任务上始终优于现有的扩散语言模型。Dream 7B展示了卓越的规划能力和推理灵活性,包括任意顺序生成、文本补全能力以及可调节的质量-速度权衡。这些结果是通过简单而有效的训练技术实现的,包括基于AR的LLM初始化和上下文自适应的token级噪声重调度。我们发布了Dream-Base和Dream-Instruct,以促进基于扩散的语言建模的进一步研究。
🔬 方法详解
问题定义:现有自回归(AR)语言模型通常按顺序生成token,这限制了并行计算能力,并且在处理长文本时可能存在效率问题。扩散语言模型虽然具有并行生成的潜力,但现有模型的性能仍有待提高,尤其是在复杂推理和规划任务上。
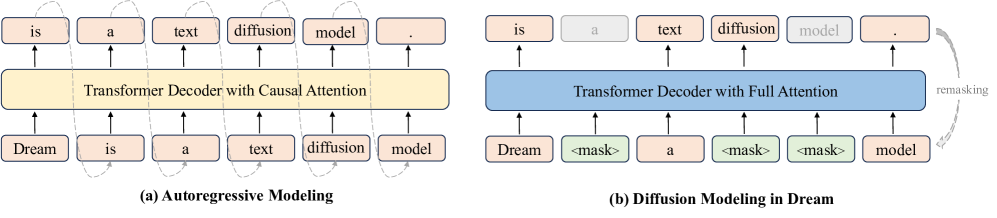
核心思路:Dream 7B的核心思路是利用离散扩散建模,通过迭代去噪的方式并行地优化序列。该方法借鉴了图像生成领域的扩散模型,将其应用于离散的文本token序列。通过引入噪声并逐步去噪,模型能够学习到文本的潜在结构和依赖关系,从而实现高质量的文本生成。
技术框架:Dream 7B的整体框架包括以下几个主要步骤:1)初始化:使用预训练的自回归LLM初始化模型参数,以加速训练过程并提高模型性能。2)前向扩散:对输入的文本序列逐步添加噪声,将其转化为随机噪声序列。3)反向扩散(去噪):通过迭代的方式,逐步去除噪声,将噪声序列还原为高质量的文本序列。4)生成:在去噪过程中,模型可以根据上下文信息进行条件生成,实现文本补全、任意顺序生成等功能。
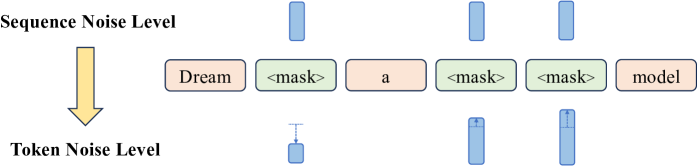
关键创新:Dream 7B的关键创新在于:1)采用了上下文自适应的token级噪声重调度策略,根据不同token的重要性动态调整噪声水平,从而提高生成质量。2)结合了自回归LLM的初始化方法,充分利用了现有预训练模型的知识,加速了训练过程并提升了模型性能。3)展示了扩散模型在复杂推理和规划任务上的潜力,为未来的研究方向提供了新的思路。
关键设计:在训练过程中,Dream 7B使用了交叉熵损失函数来优化模型参数。噪声调度策略采用了一种基于token重要性的自适应方法,对重要token施加较小的噪声,对不重要token施加较大的噪声。模型结构基于Transformer架构,并针对扩散模型进行了优化。
🖼️ 关键图片
📊 实验亮点
Dream 7B在通用、数学和编码任务上均优于现有的扩散语言模型。实验结果表明,Dream 7B在文本补全、任意顺序生成等任务上表现出色,展示了其强大的规划能力和推理灵活性。通过上下文自适应的token级噪声重调度,Dream 7B能够生成更高质量的文本。
🎯 应用场景
Dream 7B具有广泛的应用前景,包括文本生成、机器翻译、代码生成、对话系统等。其并行生成能力和推理灵活性使其在需要高效处理长文本和复杂推理任务的场景中具有优势。此外,Dream 7B还可以用于文本修复、风格迁移等任务,为创意写作和内容生成提供新的工具。
📄 摘要(原文)
We introduce Dream 7B, the most powerful open diffusion large language model to date. Unlike autoregressive (AR) models that generate tokens sequentially, Dream 7B employs discrete diffusion modeling to refine sequences in parallel through iterative denoising. Our model consistently outperforms existing diffusion language models on general, mathematical, and coding tasks. Dream 7B demonstrates superior planning abilities and inference flexibility, including arbitrary-order generation, infilling capabilities, and tunable quality-speed trade-offs. These results are achieved through simple yet effective training techniques, including AR-based LLM initialization and context-adaptive token-level noise rescheduling. We release both Dream-Base and Dream-Instruct to facilitate further research in diffusion-based language modeling.