Influence-driven Curriculum Learning for Pre-training on Limited Data
作者: Loris Schoenegger, Lukas Thoma, Terra Blevins, Benjamin Roth
分类: cs.CL, cs.LG
发布日期: 2025-08-21 (更新: 2025-09-26)
备注: Added acknowledgments section. 9 pages, Accepted to the BabyLM Workshop at EMNLP 2025
💡 一句话要点
提出基于训练数据影响力的课程学习方法,提升有限数据下预训练语言模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 课程学习 预训练语言模型 训练数据影响力 有限数据学习 模型中心学习
📋 核心要点
- 传统课程学习在预训练语言模型中效果不佳,因为人工设计的难度指标与模型实际学习难度不符。
- 论文提出使用训练数据影响力作为难度指标,以此构建更符合模型学习规律的课程。
- 实验表明,基于训练数据影响力的课程学习显著提升了预训练语言模型的性能,超过随机训练策略。
📝 摘要(中文)
本文研究了课程学习在预训练语言模型中的应用。传统的课程学习依赖于人工设计的难度指标,效果有限。本文提出使用训练数据影响力作为难度指标,该指标能够更准确地反映模型在训练过程中观察到的样本难度。实验结果表明,使用基于训练数据影响力的课程学习方法训练的模型,在基准测试中比随机顺序训练的模型性能提升超过10个百分点,证实了课程学习对语言模型预训练的益处,前提是采用更以模型为中心的难度概念。
🔬 方法详解
问题定义:论文旨在解决有限数据下预训练语言模型性能提升的问题。现有课程学习方法依赖于人工定义的难度指标(例如文档长度、词频等),这些指标与模型实际学习到的难度并不一致,导致课程学习效果不佳。因此,如何设计更有效的课程,使模型能够从易到难地学习,是本文要解决的核心问题。
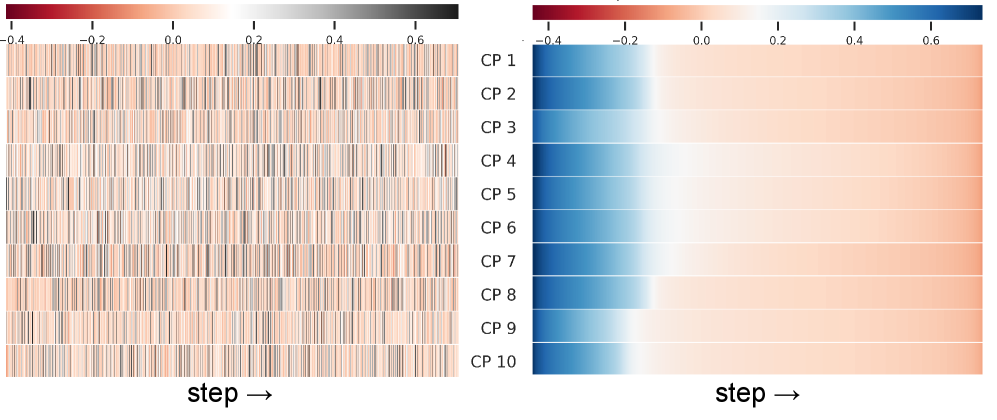
核心思路:论文的核心思路是使用训练数据影响力(Training Data Influence)作为样本难度的度量。训练数据影响力衡量的是单个训练样本对模型输出的影响程度。作者认为,影响力越大的样本,对模型来说越难学习,反之则越容易。通过对训练样本按照影响力进行排序,可以构建一个更符合模型学习规律的课程。
技术框架:该方法主要包含两个阶段:1) 计算训练数据影响力:使用某种方法(例如,基于梯度的影响函数)计算每个训练样本对模型输出的影响力得分。2) 构建课程并训练模型:根据影响力得分对训练样本进行排序,构建从易到难的课程。然后,按照课程的顺序,将训练样本逐步输入到模型中进行训练。
关键创新:论文的关键创新在于提出了使用训练数据影响力作为课程学习的难度指标。与传统的人工设计的难度指标相比,训练数据影响力能够更准确地反映模型在训练过程中观察到的样本难度。这种以模型为中心的难度度量方式,使得课程学习能够更有效地引导模型的学习过程。
关键设计:论文中可能涉及的关键设计包括:1) 训练数据影响力的计算方法:可以使用不同的方法来估计训练数据影响力,例如基于梯度的影响函数、Leave-One-Out等。2) 课程构建策略:可以采用不同的策略来构建课程,例如线性递增、指数递增等。3) 损失函数和优化器:可以使用标准的语言模型预训练损失函数(例如Masked Language Modeling)和优化器(例如Adam)。具体的参数设置需要根据实际情况进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用基于训练数据影响力的课程学习方法训练的模型,在基准测试中比随机顺序训练的模型性能提升超过10个百分点。这一显著的性能提升验证了该方法的有效性,并表明课程学习在语言模型预训练中具有重要价值,前提是采用更以模型为中心的难度概念。
🎯 应用场景
该研究成果可应用于各种自然语言处理任务的预训练阶段,尤其是在数据资源有限的情况下。通过更有效地利用有限的数据,可以提升模型的泛化能力和性能,从而改善下游任务的效果,例如文本分类、情感分析、机器翻译等。该方法也有潜力应用于其他机器学习领域,例如计算机视觉和语音识别。
📄 摘要(原文)
Curriculum learning, a training technique where data is presented to the model in order of example difficulty (e.g., from simpler to more complex documents), has shown limited success for pre-training language models. In this work, we investigate whether curriculum learning becomes competitive if we replace conventional human-centered difficulty metrics with one that more closely corresponds to example difficulty as observed during model training. Specifically, we experiment with sorting training examples by their \textit{training data influence}, a score which estimates the effect of individual training examples on the model's output. Models trained on our curricula are able to outperform ones trained in random order by over 10 percentage points in benchmarks, confirming that curriculum learning is beneficial for language model pre-training, as long as a more model-centric notion of difficulty is adopted.