When Audio and Text Disagree: Revealing Text Bias in Large Audio-Language Models
作者: Cheng Wang, Gelei Deng, Xianglin Yang, Han Qiu, Tianwei Zhang
分类: cs.CL, cs.AI
发布日期: 2025-08-21
备注: Accepted by EMNLP 2025 Main
🔗 代码/项目: GITHUB
💡 一句话要点
提出MCR-BENCH基准,揭示大型音频语言模型在不一致多模态输入中存在的文本偏见问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频语言模型 多模态学习 文本偏见 基准测试 鲁棒性 音频理解 冲突模态 模型评估
📋 核心要点
- 现有大型音频语言模型在处理音频和文本冲突信息时存在不足,缺乏系统性的评估。
- 论文提出MCR-BENCH基准,旨在评估模型在不一致音频-文本对中的信息优先级判断。
- 实验表明,LALMs在不一致输入下存在显著的文本偏见,导致音频任务性能下降,并分析了影响因素。
📝 摘要(中文)
大型音频语言模型(LALMs)通过增强音频感知能力,能够有效地处理和理解结合了音频和文本的多模态输入。然而,它们在处理音频和文本模态之间冲突信息时的表现仍然很大程度上未被研究。本文介绍了MCR-BENCH,这是第一个专门用于评估LALMs在面对不一致的音频-文本对时如何优先排序信息的综合基准。通过对各种音频理解任务的广泛评估,我们揭示了一个令人担忧的现象:当模态之间存在不一致时,LALMs表现出对文本输入的显著偏见,经常忽略音频证据。这种倾向导致以音频为中心的任务的性能大幅下降,并引发了对实际应用的重要可靠性担忧。我们进一步研究了文本偏见的影响因素,并通过监督微调探索了缓解策略,并分析了模型置信度模式,揭示了即使在存在矛盾输入的情况下仍然存在的过度自信。这些发现强调需要在训练期间改进模态平衡,并采用更复杂的融合机制,以增强处理冲突多模态输入时的鲁棒性。该项目可在https://github.com/WangCheng0116/MCR-BENCH上找到。
🔬 方法详解
问题定义:论文旨在解决大型音频语言模型(LALMs)在处理音频和文本信息不一致时,对文本的过度依赖问题。现有方法缺乏对这种偏见的系统性评估,导致模型在实际应用中可能产生误判,尤其是在音频信息更为重要的场景下。
核心思路:论文的核心思路是构建一个专门的基准测试集MCR-BENCH,该基准包含多种音频理解任务,并设计了音频和文本信息相互矛盾的样本。通过在该基准上评估LALMs的性能,可以量化模型对文本的偏见程度,并分析其影响因素。
技术框架:MCR-BENCH基准包含多个音频理解任务,例如音频事件检测、语音识别等。对于每个任务,都构建了音频和文本信息一致以及不一致的样本。LALMs接收音频和文本输入,并根据任务要求进行预测。通过比较模型在一致和不一致样本上的性能差异,可以评估其对文本的偏见程度。此外,论文还探索了监督微调等方法来缓解这种偏见。
关键创新:论文的关键创新在于提出了MCR-BENCH基准,这是第一个专门用于评估LALMs在处理不一致多模态输入时存在的文本偏见问题的基准。该基准的设计考虑了多种音频理解任务,并精心构造了音频和文本信息相互矛盾的样本,能够有效地量化模型的偏见程度。
关键设计:MCR-BENCH基准的关键设计在于其样本构造方式。对于每个音频理解任务,都设计了音频和文本信息一致以及不一致的样本。例如,在音频事件检测任务中,一致样本的音频和文本描述的是同一个事件,而不一致样本的音频和文本描述的是不同的事件。通过控制音频和文本信息的矛盾程度,可以更精细地评估模型的偏见程度。此外,论文还探索了使用交叉熵损失函数进行监督微调,以鼓励模型更多地关注音频信息。
🖼️ 关键图片

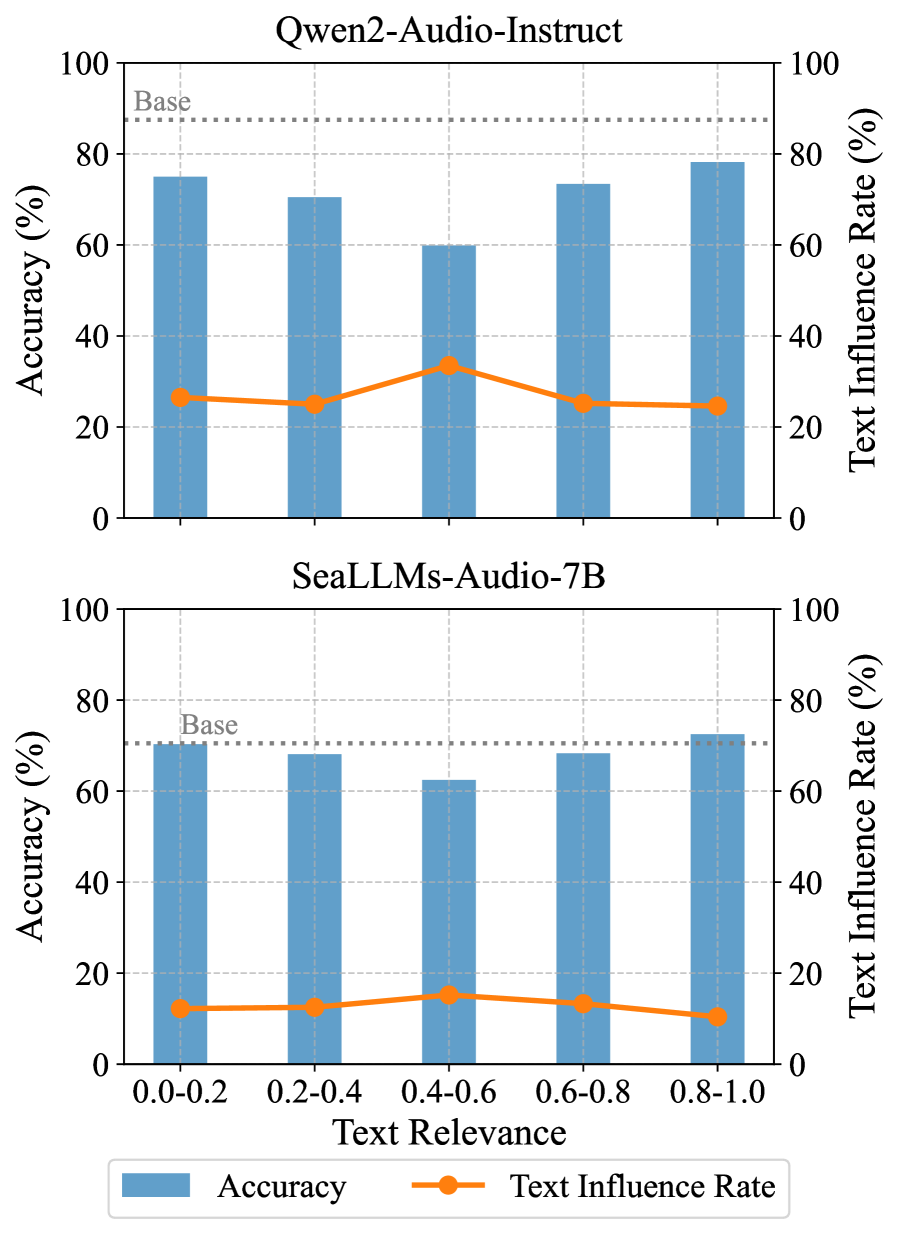

📊 实验亮点
实验结果表明,LALMs在MCR-BENCH基准上表现出显著的文本偏见,在音频信息重要的任务中性能大幅下降。例如,在某些任务中,模型在不一致样本上的准确率比一致样本下降了超过20%。通过监督微调,可以部分缓解这种偏见,但模型仍然表现出对文本的过度自信。
🎯 应用场景
该研究成果可应用于提升多模态信息处理系统的可靠性和鲁棒性,尤其是在语音助手、智能客服、自动驾驶等需要融合音频和文本信息的场景中。通过降低模型对文本的过度依赖,可以提高其在复杂环境下的感知能力和决策准确性,从而提升用户体验和安全性。
📄 摘要(原文)
Large Audio-Language Models (LALMs) are enhanced with audio perception capabilities, enabling them to effectively process and understand multimodal inputs that combine audio and text. However, their performance in handling conflicting information between audio and text modalities remains largely unexamined. This paper introduces MCR-BENCH, the first comprehensive benchmark specifically designed to evaluate how LALMs prioritize information when presented with inconsistent audio-text pairs. Through extensive evaluation across diverse audio understanding tasks, we reveal a concerning phenomenon: when inconsistencies exist between modalities, LALMs display a significant bias toward textual input, frequently disregarding audio evidence. This tendency leads to substantial performance degradation in audio-centric tasks and raises important reliability concerns for real-world applications. We further investigate the influencing factors of text bias, and explore mitigation strategies through supervised finetuning, and analyze model confidence patterns that reveal persistent overconfidence even with contradictory inputs. These findings underscore the need for improved modality balance during training and more sophisticated fusion mechanisms to enhance the robustness when handling conflicting multi-modal inputs. The project is available at https://github.com/WangCheng0116/MCR-BENCH.