Attribution, Citation, and Quotation: A Survey of Evidence-based Text Generation with Large Language Models
作者: Tobias Schreieder, Tim Schopf, Michael Färber
分类: cs.CL
发布日期: 2025-08-21
💡 一句话要点
综述论文:对大型语言模型中基于证据的文本生成方法进行归因、引用和引用的研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 证据文本生成 归因 引用 综述 可信度 可追溯性
📋 核心要点
- 现有大型语言模型在文本生成方面面临可靠性和可信度挑战,缺乏与证据的有效关联。
- 该研究通过构建统一的分类法和评估框架,系统性地分析了基于证据的文本生成方法。
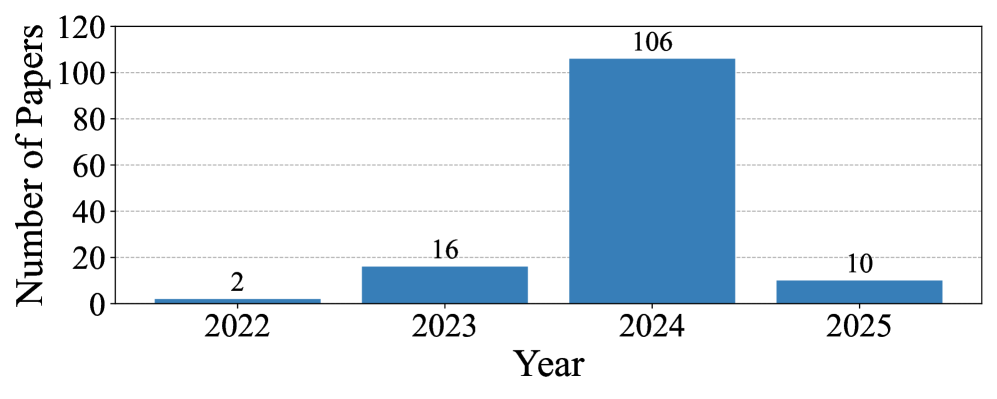
- 分析了134篇相关论文,考察了300个评估指标,并指出了未来研究的潜在方向和挑战。
📝 摘要(中文)
大型语言模型(LLM)的日益普及伴随着对其可靠性和可信度的担忧。因此,越来越多的研究集中在使用LLM进行基于证据的文本生成,旨在将模型输出与支持性证据联系起来,以确保可追溯性和可验证性。然而,由于术语不一致、孤立的评估实践以及缺乏统一的基准,该领域的研究非常分散。为了弥合这一差距,我们系统地分析了134篇论文,提出了一个关于使用LLM进行基于证据的文本生成的统一分类法,并研究了七个关键维度上的300个评估指标。在此过程中,我们重点关注使用引用、归因或引用的方法来进行基于证据的文本生成。在此基础上,我们考察了该领域的独特特征和代表性方法。最后,我们强调了开放的挑战,并概述了未来工作中有希望的方向。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在文本生成过程中缺乏可靠性和可信度的问题。现有的LLM在生成文本时,难以追溯信息来源,容易产生虚假或不准确的内容。现有的研究方法分散,缺乏统一的术语和评估标准,阻碍了该领域的发展。
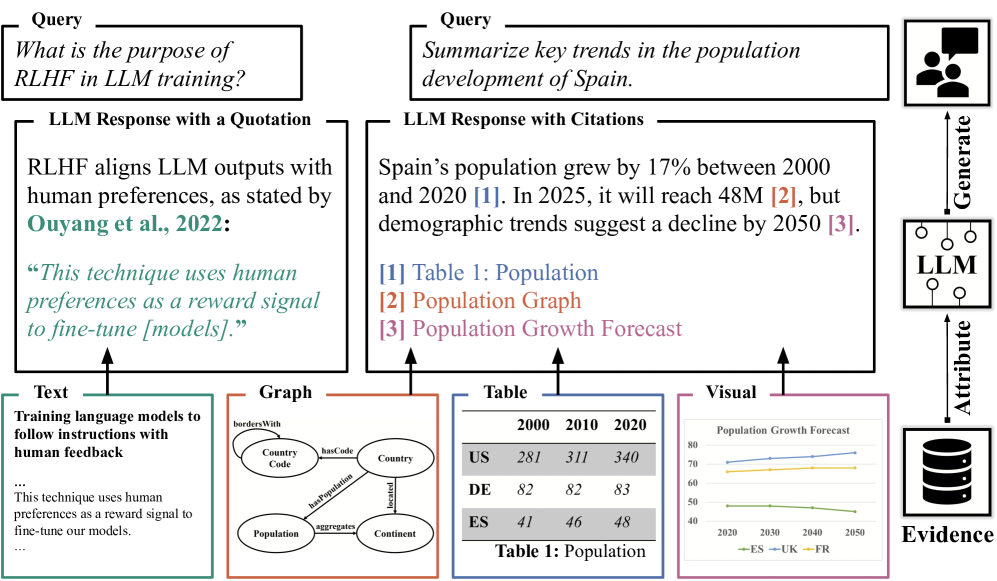
核心思路:论文的核心思路是系统性地分析和整合现有的基于证据的文本生成方法,通过构建统一的分类法和评估框架,促进该领域的研究进展。该研究重点关注使用引用、归因或引用的方法,将模型输出与支持性证据联系起来,提高生成文本的可追溯性和可验证性。
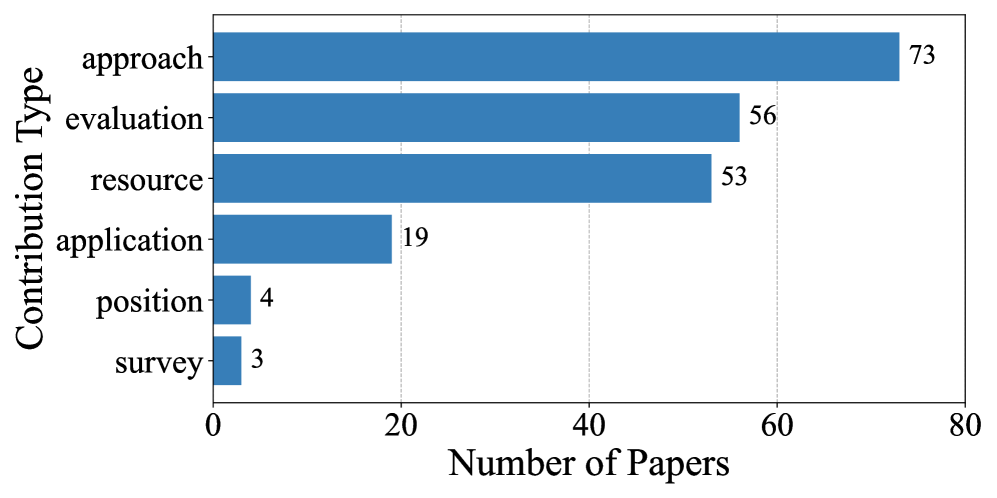
技术框架:该研究的技术框架主要包括以下几个阶段:1) 文献收集:收集了134篇关于基于证据的文本生成的相关论文。2) 分类法构建:提出了一个关于使用LLM进行基于证据的文本生成的统一分类法,对现有方法进行分类和组织。3) 评估指标分析:研究了七个关键维度上的300个评估指标,分析了不同指标的优缺点和适用场景。4) 方法比较:考察了该领域的独特特征和代表性方法,比较了不同方法的性能和特点。5) 未来展望:总结了开放的挑战,并概述了未来工作中有希望的方向。
关键创新:该研究的关键创新在于:1) 提出了一个关于使用LLM进行基于证据的文本生成的统一分类法,为该领域的研究提供了一个共同的框架。2) 系统地分析了300个评估指标,为评估基于证据的文本生成方法提供了全面的参考。3) 总结了该领域的开放挑战和未来方向,为未来的研究提供了指导。
关键设计:论文主要是一个综述,没有涉及具体的模型设计或参数设置。关键在于对现有文献的系统性分析和总结,以及对评估指标的深入研究。研究者需要仔细阅读和理解大量的论文,才能构建出合理的分类法和评估框架。
🖼️ 关键图片
📊 实验亮点
该研究系统分析了134篇论文,提出了基于证据文本生成的统一分类法,并考察了七个维度上的300个评估指标。通过对现有方法的深入分析,为未来的研究提供了重要的参考和指导,有助于推动该领域的发展。
🎯 应用场景
该研究成果可应用于多个领域,例如新闻报道、科学写作、法律文件生成等,提高生成文本的准确性和可信度。通过将模型输出与可靠的证据联系起来,可以减少虚假信息的传播,增强用户对生成内容的信任。未来,该研究可以促进LLM在需要高度可靠性的场景中的应用。
📄 摘要(原文)
The increasing adoption of large language models (LLMs) has been accompanied by growing concerns regarding their reliability and trustworthiness. As a result, a growing body of research focuses on evidence-based text generation with LLMs, aiming to link model outputs to supporting evidence to ensure traceability and verifiability. However, the field is fragmented due to inconsistent terminology, isolated evaluation practices, and a lack of unified benchmarks. To bridge this gap, we systematically analyze 134 papers, introduce a unified taxonomy of evidence-based text generation with LLMs, and investigate 300 evaluation metrics across seven key dimensions. Thereby, we focus on approaches that use citations, attribution, or quotations for evidence-based text generation. Building on this, we examine the distinctive characteristics and representative methods in the field. Finally, we highlight open challenges and outline promising directions for future work.