Exploiting Vocabulary Frequency Imbalance in Language Model Pre-training
作者: Woojin Chung, Jeonghoon Kim
分类: cs.CL, cs.LG
发布日期: 2025-08-21 (更新: 2025-11-28)
备注: NeurIPS 2025
💡 一句话要点
研究词汇频率不平衡对语言模型预训练的影响,揭示扩大词表主要降低高频词的不确定性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型预训练 词汇表大小 token频率不平衡 Kolmogorov复杂性 词级损失分解
📋 核心要点
- 现有语言模型预训练中,token分布极度不平衡,扩大词汇表带来的收益来源不明。
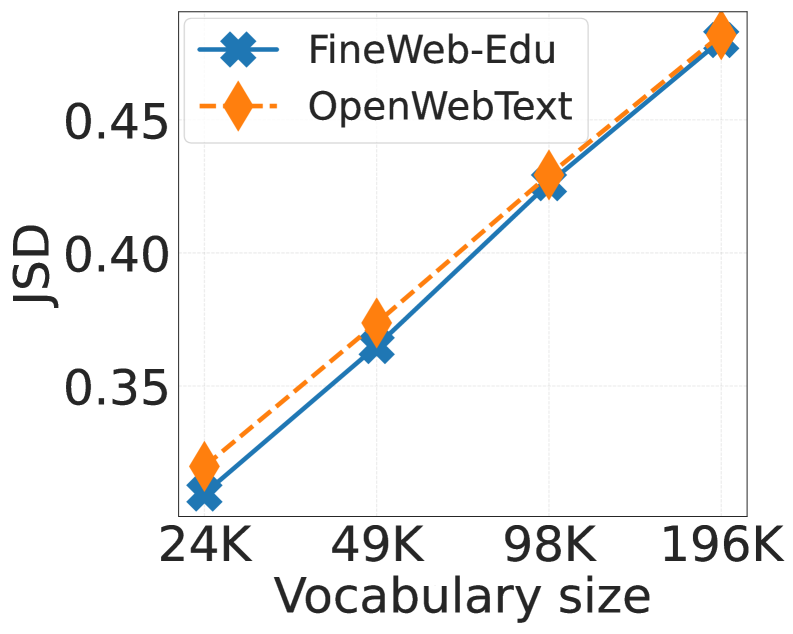
- 通过控制实验,研究表明扩大词汇表主要降低了token化文本的复杂性,特别是降低了高频词的不确定性。
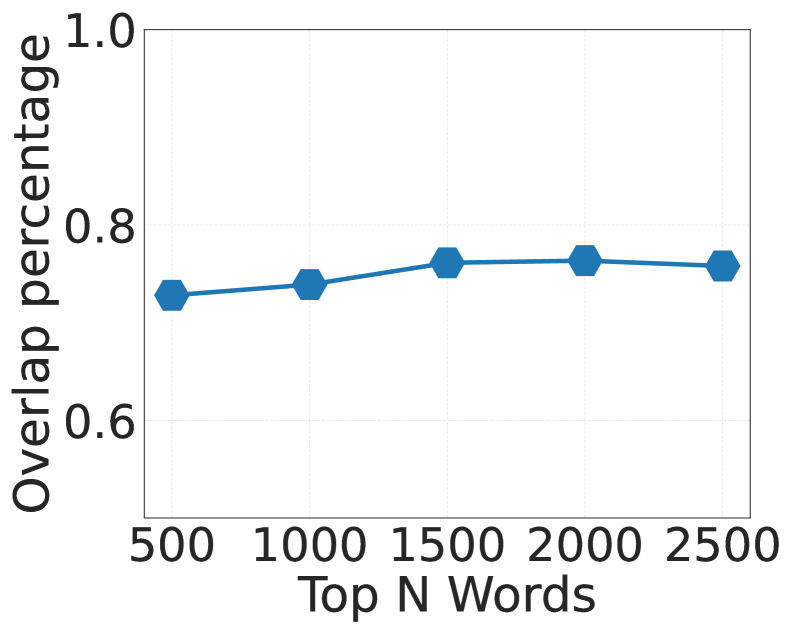
- 实验结果表明,降低高频词的不确定性是扩大词汇表带来的主要优势,并且这种优势可以迁移到下游任务。
📝 摘要(中文)
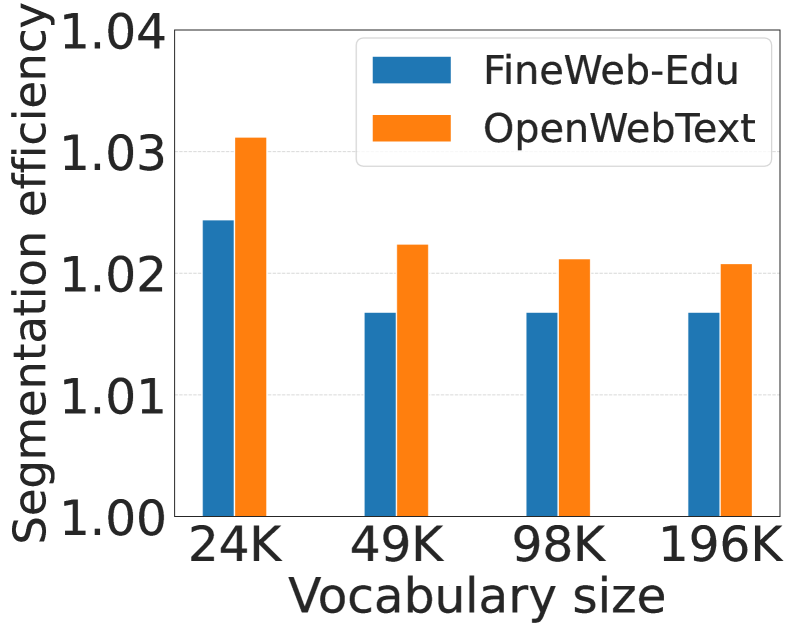
大型语言模型使用tokenizer进行训练,导致token分布高度不平衡:少数词占据主导地位,而大多数词很少出现。最近的研究倾向于使用更大的词汇表,但其益处来源尚不清楚。为此,我们进行了一项受控研究,在数据、计算和优化保持不变的情况下,将语言模型的词汇量从24K扩展到196K。我们首先量化了token化文本的复杂性(通过Kolmogorov复杂性形式化),并表明更大的词汇表降低了这种复杂性。在超过24K之后,每个常用词都已经被token化为单个token,因此扩大词汇量只会加剧相对token频率的不平衡。词级损失分解表明,更大的词汇表几乎完全通过降低对2500个最常用词的不确定性来降低交叉熵损失,即使尾部稀有词的损失上升。这些常见词覆盖了下游基准测试中大约75%的token,因此这种训练优势得以完整转移。我们进一步表明,在固定词汇量的情况下扩大模型参数也会产生相同的高频词优势。我们的结果将“更大的词汇表有帮助”重新定义为“降低token化文本的复杂性有帮助”,为tokenizer-模型协同设计提供了一个简单而有原则的旋钮,并阐明了控制预训练中语言模型缩放的损失动态。
🔬 方法详解
问题定义:论文旨在解决大型语言模型预训练中,词汇表大小对模型性能影响的问题。现有方法倾向于使用更大的词汇表,但缺乏对这种做法背后原因的深入理解。特别是,token分布的不平衡性以及扩大词汇表如何影响不同频率词汇的损失变化,是现有研究的痛点。
核心思路:论文的核心思路是将“更大的词汇表有帮助”重新定义为“降低token化文本的复杂性有帮助”。通过量化token化文本的Kolmogorov复杂性,并分析不同词频词汇的损失变化,揭示了扩大词汇表主要通过降低高频词的不确定性来提升模型性能。这种思路强调了tokenizer与模型之间的协同设计的重要性。
技术框架:论文采用了一种受控实验的方法。首先,固定数据、计算和优化策略,然后逐步扩大语言模型的词汇量(从24K到196K)。接着,使用Kolmogorov复杂性来量化token化文本的复杂性,并使用词级损失分解来分析不同频率词汇的损失变化。最后,在下游任务上评估模型的性能,以验证预训练的优势是否能够迁移。
关键创新:论文最重要的技术创新在于揭示了扩大词汇表的主要优势在于降低高频词的不确定性。与现有方法不同,论文没有简单地认为更大的词汇表总是更好,而是深入分析了词汇表大小与token频率分布、损失变化之间的关系。这种分析为tokenizer-模型协同设计提供了新的视角。
关键设计:论文的关键设计包括:1) 使用Kolmogorov复杂性来量化token化文本的复杂性;2) 使用词级损失分解来分析不同频率词汇的损失变化;3) 通过受控实验来隔离词汇表大小的影响。此外,论文还关注了高频词在下游任务中的覆盖率,以验证预训练优势的迁移能力。没有提及具体的参数设置、损失函数、网络结构等技术细节。
🖼️ 关键图片
📊 实验亮点
实验结果表明,扩大词汇表主要通过降低2500个最常用词的不确定性来降低交叉熵损失,即使尾部稀有词的损失上升。这些常见词覆盖了下游基准测试中大约75%的token,因此这种训练优势得以完整转移。在固定词汇量的情况下扩大模型参数也会产生相同的高频词优势。
🎯 应用场景
该研究成果可应用于语言模型预训练的tokenizer设计,指导如何更有效地选择词汇表大小,从而在计算资源有限的情况下,提升语言模型的性能。通过降低token化文本的复杂性,可以提高预训练效率,并改善下游任务的表现。此外,该研究也为理解语言模型缩放规律提供了新的视角。
📄 摘要(原文)
Large language models are trained with tokenizers, and the resulting token distribution is highly imbalanced: a few words dominate the stream while most occur rarely. Recent practice favors ever-larger vocabularies, but it is unclear where the benefit comes from. To this end, we perform a controlled study that scales the vocabulary of the language model from 24K to 196K while holding data, computation, and optimization unchanged. We begin by quantifying the complexity of tokenized text -- formalized via Kolmogorov complexity -- and show that larger vocabularies reduce this complexity. Above 24K, every common word is already tokenized as a single token, so enlarging vocabulary only deepens the relative token-frequency imbalance. Word-level loss decomposition shows that larger vocabularies reduce cross-entropy loss almost exclusively by lowering uncertainty on the 2,500 most frequent words, even though loss on the rare tail rises. The same frequent words cover roughly 75% of tokens in downstream benchmarks, so this training advantage transfers intact. We further show that enlarging model parameters with a fixed vocabulary yields the same frequent-word benefit. Our results recast "bigger vocabularies help" as "lowering complexity of tokenized text helps," offering a simple, principled knob for tokenizer-model co-design and clarifying the loss dynamics that govern language model scaling in pre-training.