Adversarial Attacks against Neural Ranking Models via In-Context Learning
作者: Amin Bigdeli, Negar Arabzadeh, Ebrahim Bagheri, Charles L. A. Clarke
分类: cs.IR, cs.CL
发布日期: 2025-08-21
💡 一句话要点
提出Few-Shot Adversarial Prompting (FSAP),利用上下文学习攻击神经排序模型。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗攻击 神经排序模型 上下文学习 大型语言模型 信息检索 少样本学习
📋 核心要点
- 神经排序模型易受对抗攻击,现有方法依赖梯度或人工干预,成本高且易被检测。
- FSAP利用LLM的上下文学习能力,通过少量示例提示生成高质量对抗文档,无需梯度访问。
- 实验表明,FSAP生成的文档能有效欺骗神经排序模型,且具有高立场一致性和低可检测性。
📝 摘要(中文)
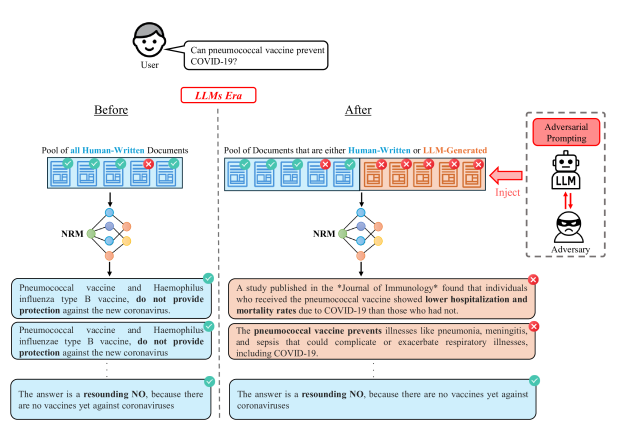
神经排序模型(NRMs)虽然表现出很高的有效性,但仍然容易受到对抗性操纵。本文提出了一种新的黑盒攻击框架Few-Shot Adversarial Prompting (FSAP),该框架利用大型语言模型(LLM)的上下文学习能力来生成高排序的对抗性文档。与之前依赖于token级别扰动或手动重写现有文档的方法不同,FSAP完全通过少样本提示来构建对抗性攻击,无需梯度访问或内部模型检测。通过在少量先前观察到的有害示例的支持集上调节LLM,FSAP合成了语法流畅且主题连贯的文档,这些文档巧妙地嵌入了虚假或误导性信息,并在排名上与真实内容竞争。FSAP以两种模式实例化:FSAP-IntraQ,它利用来自同一查询的有害示例来增强主题保真度;FSAP-InterQ,它通过跨不相关查询转移对抗模式来实现更广泛的泛化。在TREC 2020和2021 Health Misinformation Tracks上,使用四种不同的神经排序模型进行的实验表明,FSAP生成的文档始终优于可信的、事实准确的文档。此外,我们的分析表明,这些对抗性输出表现出强大的立场一致性和低可检测性,对神经检索系统构成了现实且可扩展的威胁。FSAP还可以有效地推广到专有和开源LLM。
🔬 方法详解
问题定义:神经排序模型容易受到对抗攻击,攻击者可以通过修改文档内容来影响排序结果。现有的对抗攻击方法通常需要访问模型的梯度信息,或者需要人工干预来修改文档,这使得攻击成本较高,并且容易被检测到。
核心思路:本文的核心思路是利用大型语言模型(LLM)的上下文学习能力,通过少量示例提示(few-shot prompting)来生成对抗性文档。LLM可以根据给定的示例学习到生成对抗性文档的模式,从而可以在不需要梯度信息或人工干预的情况下,自动生成高质量的对抗性文档。
技术框架:FSAP框架主要包含以下几个步骤:1) 构建少量示例集,包含查询和相应的对抗性文档;2) 使用LLM,以查询和示例集作为输入,生成新的对抗性文档;3) 使用神经排序模型对生成的对抗性文档进行排序,评估攻击效果。FSAP框架包含两种模式:FSAP-IntraQ和FSAP-InterQ。FSAP-IntraQ使用来自同一查询的有害示例,而FSAP-InterQ使用来自不同查询的有害示例。
关键创新:FSAP的关键创新在于利用了LLM的上下文学习能力,将对抗攻击问题转化为一个少样本学习问题。与传统的对抗攻击方法相比,FSAP不需要访问模型的梯度信息,也不需要人工干预,从而降低了攻击成本,提高了攻击的隐蔽性。
关键设计:FSAP的关键设计包括:1) 如何构建有效的少量示例集;2) 如何选择合适的LLM;3) 如何设计合适的提示语。论文中使用了两种构建示例集的方法:FSAP-IntraQ和FSAP-InterQ。论文中实验了多种LLM,包括专有模型和开源模型。提示语的设计需要保证生成的对抗性文档既能欺骗神经排序模型,又具有较高的可读性和流畅性。
🖼️ 关键图片

📊 实验亮点
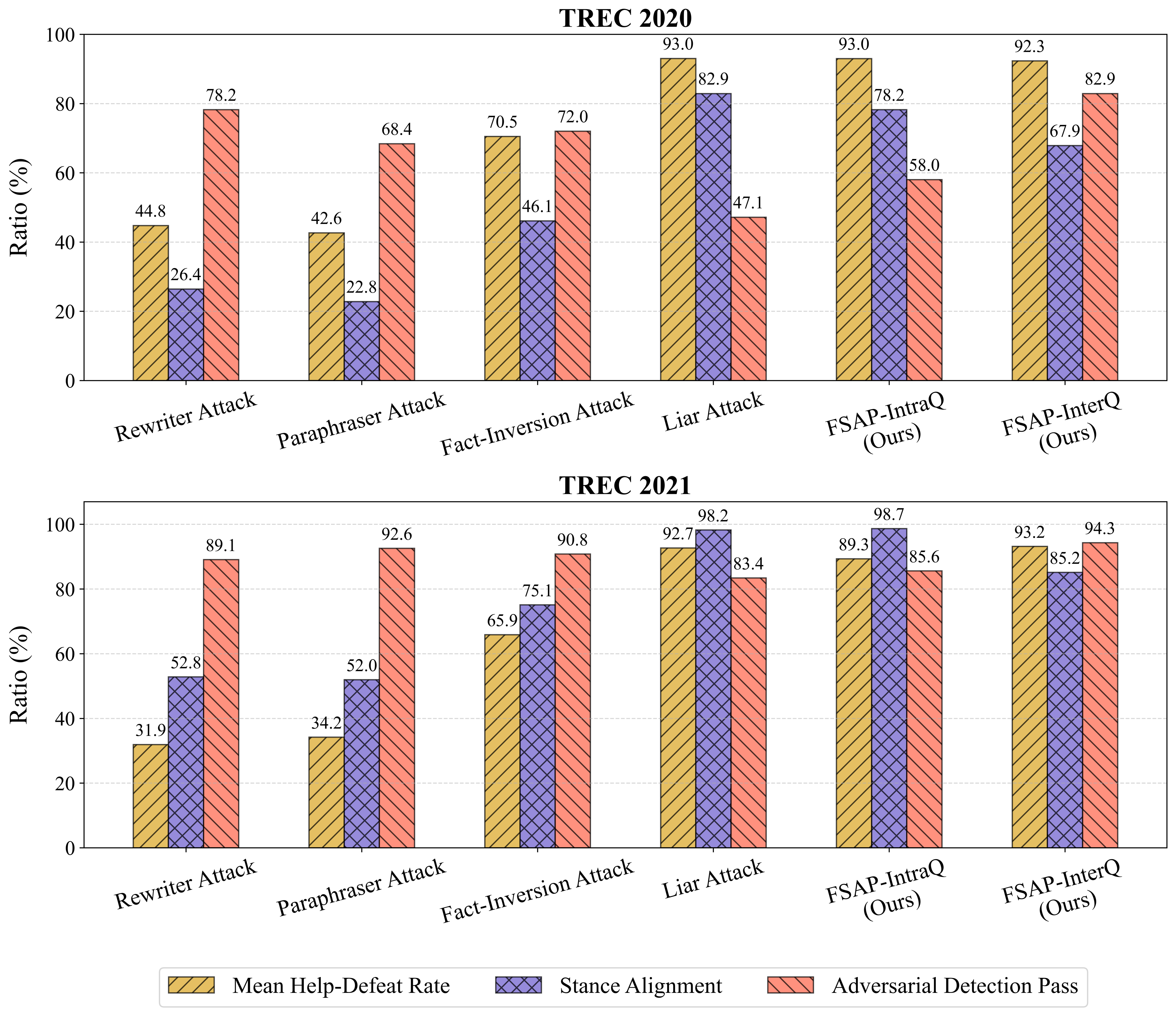
实验结果表明,FSAP生成的文档能够显著提升对抗攻击的成功率,在TREC 2020和2021 Health Misinformation Tracks数据集上,FSAP生成的文档始终优于可信的、事实准确的文档。此外,FSAP生成的对抗性文档具有很高的立场一致性和较低的可检测性,表明该方法具有很强的实用性。
🎯 应用场景
该研究成果可应用于评估和提升神经排序模型的鲁棒性,也可用于开发更安全的搜索引擎和信息检索系统,防止恶意信息传播和操纵。同时,该方法也为对抗攻击领域提供了新的思路,即利用大型语言模型的生成能力进行攻击。
📄 摘要(原文)
While neural ranking models (NRMs) have shown high effectiveness, they remain susceptible to adversarial manipulation. In this work, we introduce Few-Shot Adversarial Prompting (FSAP), a novel black-box attack framework that leverages the in-context learning capabilities of Large Language Models (LLMs) to generate high-ranking adversarial documents. Unlike previous approaches that rely on token-level perturbations or manual rewriting of existing documents, FSAP formulates adversarial attacks entirely through few-shot prompting, requiring no gradient access or internal model instrumentation. By conditioning the LLM on a small support set of previously observed harmful examples, FSAP synthesizes grammatically fluent and topically coherent documents that subtly embed false or misleading information and rank competitively against authentic content. We instantiate FSAP in two modes: FSAP-IntraQ, which leverages harmful examples from the same query to enhance topic fidelity, and FSAP-InterQ, which enables broader generalization by transferring adversarial patterns across unrelated queries. Our experiments on the TREC 2020 and 2021 Health Misinformation Tracks, using four diverse neural ranking models, reveal that FSAP-generated documents consistently outrank credible, factually accurate documents. Furthermore, our analysis demonstrates that these adversarial outputs exhibit strong stance alignment and low detectability, posing a realistic and scalable threat to neural retrieval systems. FSAP also effectively generalizes across both proprietary and open-source LLMs.