Are Checklists Really Useful for Automatic Evaluation of Generative Tasks?
作者: Momoka Furuhashi, Kouta Nakayama, Takashi Kodama, Saku Sugawara
分类: cs.CL
发布日期: 2025-08-21
备注: Accepted to the EMNLP 2025 Main Conference
🔗 代码/项目: GITHUB
💡 一句话要点
研究检查列表在生成任务自动评估中的有效性,并提出选择性使用策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动评估 生成任务 检查列表 大型语言模型 评估标准
📋 核心要点
- 现有生成任务自动评估方法面临标准模糊的挑战,导致评估结果不稳定。
- 该研究探索了基于检查列表的自动评估方法,并提出选择性使用检查列表的策略。
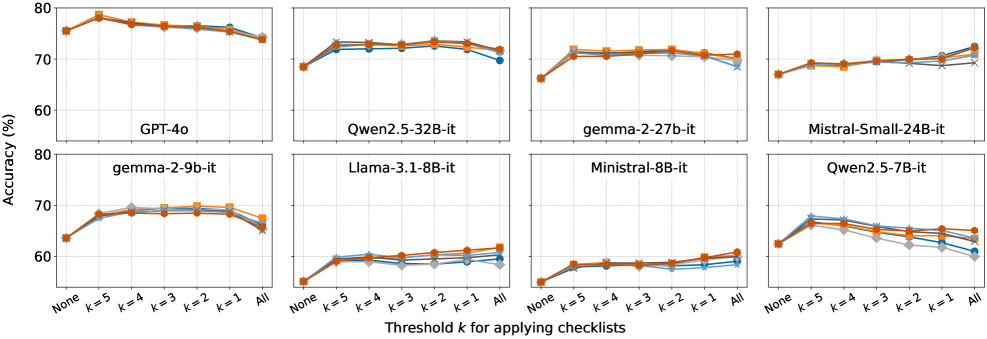
- 实验表明,选择性使用检查列表在成对比较任务中能提升评估性能,并揭示了人工评估标准的不一致性。
📝 摘要(中文)
大型语言模型在生成任务的自动评估中面临着标准模糊的挑战。自动生成检查列表是一种潜在的解决方案,但其有效性尚未得到充分探索。本研究调查了检查列表是否应该用于所有问题或仅选择性地使用,并使用六种方法生成检查列表,评估了它们在八种模型规模下的有效性,并识别了与人工评估相关的检查列表项。通过在成对比较和直接评分任务上的实验,我们发现选择性使用检查列表往往可以提高成对设置中的评估性能,但在直接评分中其优势不太明显。我们的分析还表明,即使是与人类分数相关性较低的检查列表项也通常反映了人类编写的标准,表明人类评估中可能存在不一致。这些发现强调需要更清楚地定义客观评估标准,以指导人类和自动评估。
🔬 方法详解
问题定义:当前使用大型语言模型自动评估生成任务时,由于评估标准的主观性和模糊性,导致评估结果与人类评估结果不一致,难以准确衡量生成模型的性能。现有的自动评估方法难以有效捕捉生成结果的细粒度质量特征。
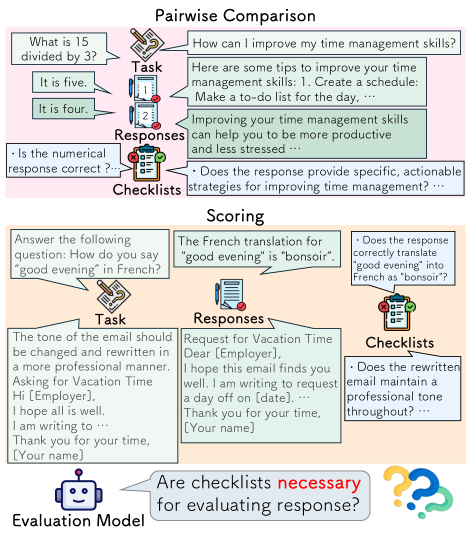
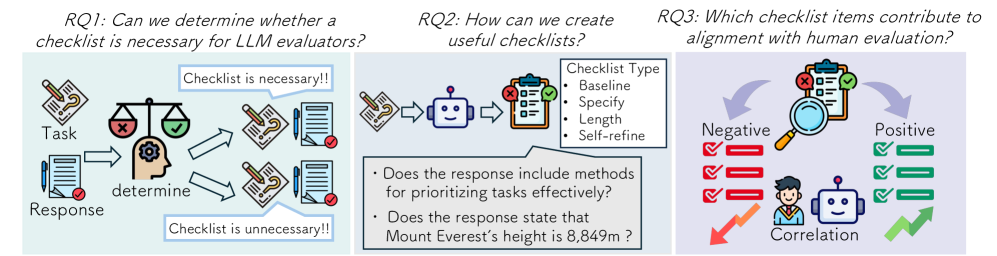
核心思路:该论文的核心思路是探索使用自动生成的检查列表来辅助生成任务的自动评估。通过将评估标准分解为一系列具体的检查项,期望能够更客观、更细粒度地评估生成结果。此外,论文还提出了选择性使用检查列表的策略,即并非所有问题都使用检查列表,而是根据问题的特点选择性地应用。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 使用六种不同的方法自动生成检查列表;2) 在八种不同规模的语言模型上进行实验;3) 在成对比较和直接评分两种评估任务上评估检查列表的有效性;4) 分析检查列表项与人类评估结果的相关性,并识别出与人类评估一致的检查列表项。
关键创新:该论文的关键创新在于提出了选择性使用检查列表的策略,并验证了其在成对比较任务中的有效性。此外,该研究还深入分析了检查列表项与人类评估结果的相关性,揭示了人类评估标准中可能存在的不一致性。
关键设计:论文使用了六种不同的方法生成检查列表,具体方法未知。评估指标包括在成对比较和直接评分任务中的评估性能,以及检查列表项与人类评估结果的相关性。具体参数设置、损失函数和网络结构等技术细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,选择性使用检查列表在成对比较任务中能够提高评估性能,但在直接评分任务中效果不明显。分析发现,即使与人类评分相关性较低的检查列表项也可能反映了人类编写的标准,揭示了人类评估标准中可能存在的不一致性。具体性能提升幅度未知。
🎯 应用场景
该研究成果可应用于各种生成任务的自动评估,例如文本生成、图像生成、代码生成等。通过使用检查列表,可以更客观、更细粒度地评估生成模型的性能,从而促进生成模型的发展。此外,该研究还可以帮助人们更好地理解人类评估标准,并提高人工评估的质量。
📄 摘要(原文)
Automatic evaluation of generative tasks using large language models faces challenges due to ambiguous criteria. Although automatic checklist generation is a potentially promising approach, its usefulness remains underexplored. We investigate whether checklists should be used for all questions or selectively, generate them using six methods, evaluate their effectiveness across eight model sizes, and identify checklist items that correlate with human evaluations. Through experiments on pairwise comparison and direct scoring tasks, we find that selective checklist use tends to improve evaluation performance in pairwise settings, while its benefits are less consistent in direct scoring. Our analysis also shows that even checklist items with low correlation to human scores often reflect human-written criteria, indicating potential inconsistencies in human evaluation. These findings highlight the need to more clearly define objective evaluation criteria to guide both human and automatic evaluations. \footnote{Our code is available at~https://github.com/momo0817/checklist-effectiveness-study