Fin-PRM: A Domain-Specialized Process Reward Model for Financial Reasoning in Large Language Models
作者: Yuanchen Zhou, Shuo Jiang, Jie Zhu, Junhui Li, Lifan Guo, Feng Chen, Chi Zhang
分类: cs.CL
发布日期: 2025-08-21
🔗 代码/项目: GITHUB
💡 一句话要点
提出Fin-PRM:一种领域专用过程奖励模型,用于提升大语言模型在金融推理中的能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融推理 过程奖励模型 领域专用 大语言模型 强化学习 监督学习 轨迹建模
📋 核心要点
- 现有过程奖励模型(PRM)在金融等领域表现不足,因为金融推理对事实和监管正确性要求更高。
- Fin-PRM通过集成步骤级和轨迹级奖励监督,实现对金融推理过程的细粒度评估和优化。
- 实验表明,Fin-PRM在金融推理基准上显著优于通用PRM,下游任务性能提升明显。
📝 摘要(中文)
过程奖励模型(PRM)已成为监督大语言模型(LLM)中间推理步骤的一种有前景的框架。然而,现有的PRM主要在通用或科学、技术、工程和数学(STEM)领域进行训练,在金融等领域特定环境中表现不足,因为金融推理更结构化、符号化,并且对事实和监管的正确性更敏感。我们引入了Fin-PRM,一种领域专用、轨迹感知的PRM,专门用于评估金融任务中的中间推理步骤。Fin-PRM集成了步骤级和轨迹级奖励监督,从而能够对符合金融逻辑的推理轨迹进行细粒度评估。我们将Fin-PRM应用于离线和在线奖励学习设置,支持三个关键应用:(i)选择高质量的推理轨迹用于基于蒸馏的监督微调,(ii)为强化学习提供密集的流程级奖励,以及(iii)在测试时指导奖励信息Best-of-N推理。在包括CFLUE和FinQA在内的金融推理基准上的实验结果表明,Fin-PRM在轨迹选择质量方面始终优于通用PRM和强大的领域基线。使用Fin-PRM训练的下游模型与基线相比取得了显著的改进,在监督学习中提高了12.9%,在强化学习中提高了5.2%,在测试时性能提高了5.1%。这些发现突出了领域专用奖励建模对于使LLM与专家级金融推理保持一致的价值。我们的项目资源将在https://github.com/aliyun/qwen-dianjin上提供。
🔬 方法详解
问题定义:现有通用PRM在金融领域的推理任务中表现不佳,无法有效评估和指导LLM进行符合金融逻辑的推理过程。痛点在于缺乏对金融领域知识的针对性建模,无法准确判断推理步骤的正确性和合理性。
核心思路:Fin-PRM的核心思路是构建一个领域专用的过程奖励模型,该模型能够理解金融领域的知识和逻辑,并对LLM的推理过程进行细粒度的评估和奖励。通过步骤级和轨迹级的奖励监督,引导LLM生成更符合金融逻辑的推理路径。
技术框架:Fin-PRM的整体框架包括以下几个主要模块:1) 数据收集与标注:构建包含金融领域推理任务的数据集,并对推理过程中的每个步骤进行标注,标注信息包括步骤的正确性、合理性等。2) 奖励模型训练:使用标注数据训练Fin-PRM,使其能够根据LLM的推理步骤和轨迹,给出相应的奖励值。3) 模型应用:将Fin-PRM应用于三个关键应用:a) 基于蒸馏的监督微调,选择高质量的推理轨迹;b) 强化学习,提供密集的流程级奖励;c) 测试时推理,指导奖励信息Best-of-N推理。
关键创新:Fin-PRM的关键创新在于其领域专用性和轨迹感知能力。与通用PRM相比,Fin-PRM能够更好地理解金融领域的知识和逻辑,并对推理过程进行更准确的评估。轨迹感知能力使得Fin-PRM能够考虑推理步骤之间的依赖关系,从而更全面地评估推理过程的质量。
关键设计:Fin-PRM的关键设计包括:1) 步骤级奖励函数:用于评估每个推理步骤的正确性和合理性,可以基于专家知识或规则进行设计。2) 轨迹级奖励函数:用于评估整个推理轨迹的质量,可以考虑轨迹的完整性、一致性等因素。3) 奖励融合机制:将步骤级奖励和轨迹级奖励进行融合,得到最终的奖励值。4) 损失函数:用于训练Fin-PRM,可以采用回归损失或排序损失等。
🖼️ 关键图片
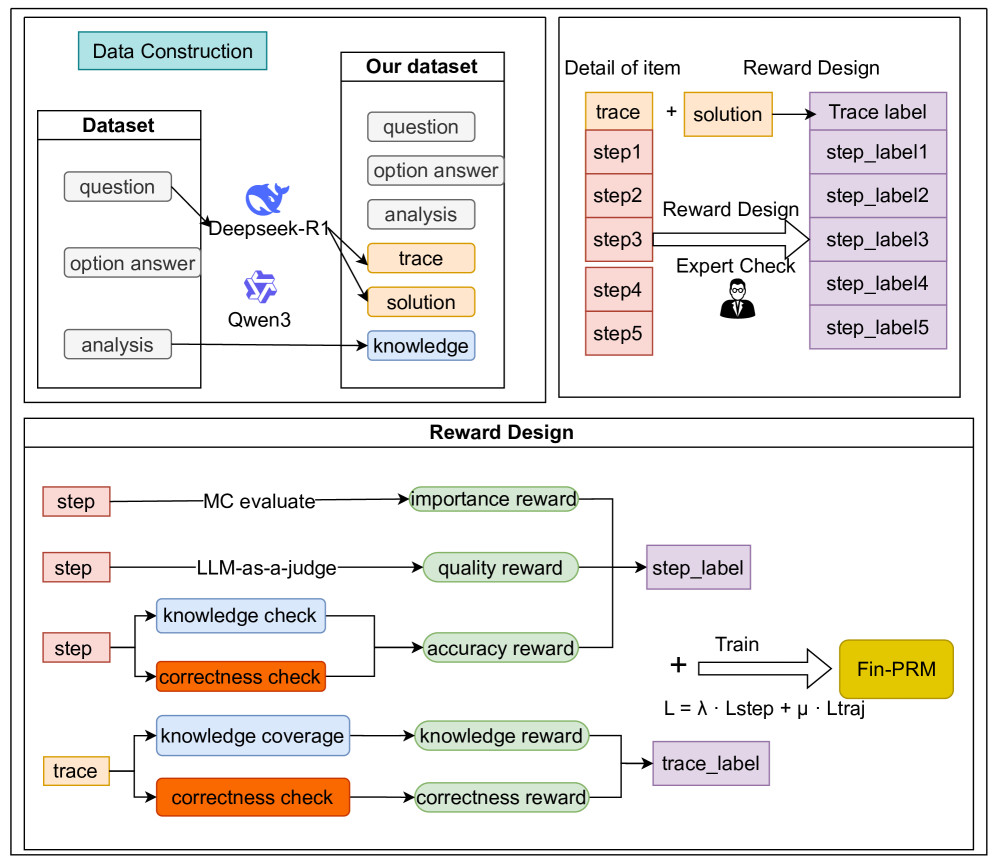
📊 实验亮点
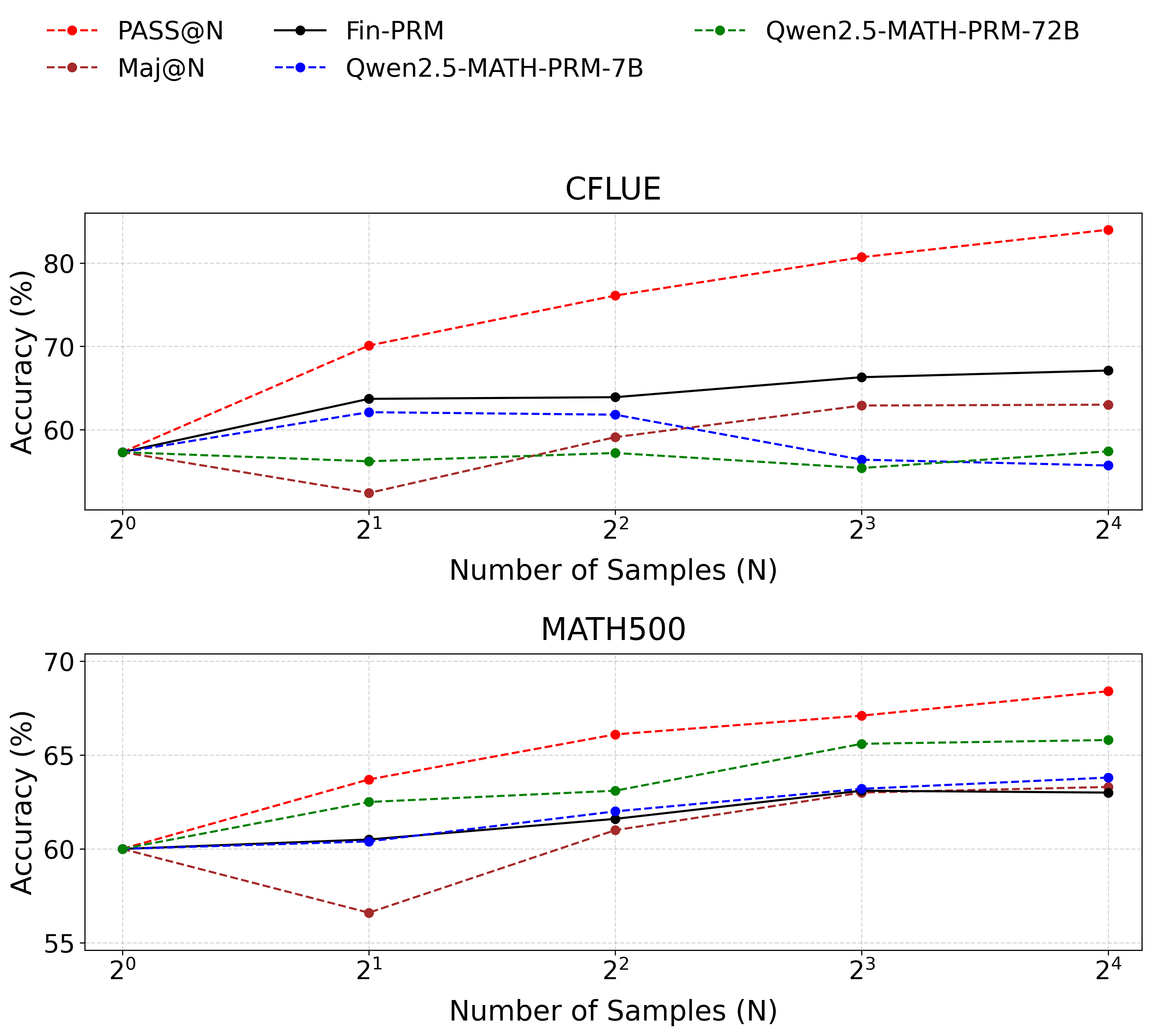
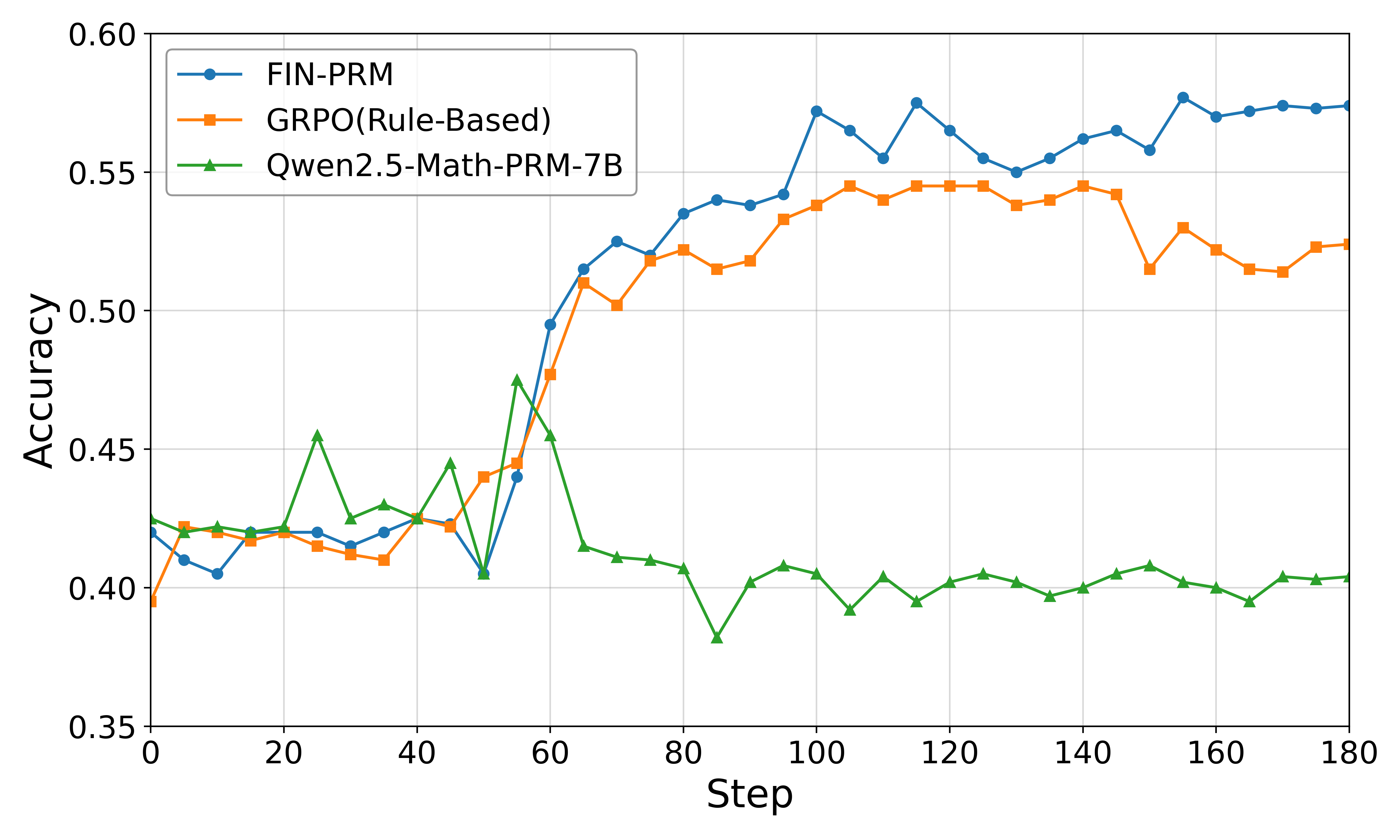
实验结果表明,Fin-PRM在金融推理基准CFLUE和FinQA上,轨迹选择质量始终优于通用PRM和领域基线。使用Fin-PRM训练的下游模型在监督学习中性能提升12.9%,强化学习中提升5.2%,测试时性能提升5.1%。这些数据证明了Fin-PRM在提升LLM金融推理能力方面的有效性。
🎯 应用场景
Fin-PRM可应用于金融领域的智能问答、风险评估、投资决策等场景。通过提升LLM在金融推理方面的能力,可以帮助金融从业者更高效地处理复杂问题,提高决策的准确性和效率。未来,Fin-PRM有望在金融监管、合规审查等方面发挥重要作用。
📄 摘要(原文)
Process Reward Models (PRMs) have emerged as a promising framework for supervising intermediate reasoning in large language models (LLMs), yet existing PRMs are primarily trained on general or Science, Technology, Engineering, and Mathematics (STEM) domains and fall short in domain-specific contexts such as finance, where reasoning is more structured, symbolic, and sensitive to factual and regulatory correctness. We introduce \textbf{Fin-PRM}, a domain-specialized, trajectory-aware PRM tailored to evaluate intermediate reasoning steps in financial tasks. Fin-PRM integrates step-level and trajectory-level reward supervision, enabling fine-grained evaluation of reasoning traces aligned with financial logic. We apply Fin-PRM in both offline and online reward learning settings, supporting three key applications: (i) selecting high-quality reasoning trajectories for distillation-based supervised fine-tuning, (ii) providing dense process-level rewards for reinforcement learning, and (iii) guiding reward-informed Best-of-N inference at test time. Experimental results on financial reasoning benchmarks, including CFLUE and FinQA, demonstrate that Fin-PRM consistently outperforms general-purpose PRMs and strong domain baselines in trajectory selection quality. Downstream models trained with Fin-PRM yield substantial improvements with baselines, with gains of 12.9\% in supervised learning, 5.2\% in reinforcement learning, and 5.1\% in test-time performance. These findings highlight the value of domain-specialized reward modeling for aligning LLMs with expert-level financial reasoning. Our project resources will be available at https://github.com/aliyun/qwen-dianjin.