SemToken: Semantic-Aware Tokenization for Efficient Long-Context Language Modeling
作者: Dong Liu, Yanxuan Yu
分类: cs.CL, cs.AI
发布日期: 2025-08-21
💡 一句话要点
SemToken:面向长文本高效建模的语义感知分词方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语义感知分词 长文本建模 语言模型 计算效率 语义聚类 异构粒度 注意力机制
📋 核心要点
- 现有分词方法如BPE和WordPiece仅依赖频率统计,忽略了文本的语义结构,导致语义冗余跨度的过度分词和上下文连贯性的利用不足。
- SemToken通过轻量级编码器提取语义嵌入,利用局部语义聚类合并语义等价token,并根据语义密度自适应调整token粒度。
- 实验表明,SemToken在长文本建模中显著减少token数量并加速计算,同时保持或提升模型性能,验证了语义感知分词的有效性。
📝 摘要(中文)
本文提出了一种语义感知的分词框架SemToken,旨在降低token冗余并提高计算效率。SemToken首先通过轻量级编码器提取上下文语义嵌入,并执行局部语义聚类以合并语义等价的token。然后,它基于语义密度分配异构的token粒度,允许在内容丰富的区域进行更细粒度的分词,并在重复或低熵的区域进行更粗粒度的压缩。SemToken可以无缝集成到现代语言模型和注意力加速方法中。在WikiText-103和LongBench等长文本语言建模基准上的实验表明,SemToken实现了高达2.4倍的token数量减少和1.9倍的加速,而困惑度和下游任务准确性几乎没有下降或没有下降。研究结果表明,语义结构为优化大型语言模型中的分词和计算提供了一个有希望的新方向。
🔬 方法详解
问题定义:现有分词方法(如BPE、WordPiece)主要基于频率统计,缺乏对文本语义结构的理解。这导致在长文本中,语义重复或低信息量的部分被过度切分,而信息丰富的区域可能切分不足,从而影响模型的效率和性能。现有方法无法有效利用长文本中的上下文连贯性。
核心思路:SemToken的核心思路是引入语义信息指导分词过程。通过学习token的语义表示,将语义相似的token合并,并根据语义密度动态调整token的粒度。这样可以在保证语义完整性的前提下,减少token数量,提高计算效率。
技术框架:SemToken框架主要包含以下几个阶段:1) 语义嵌入提取:使用轻量级编码器(如Transformer的浅层网络)提取token的上下文语义嵌入。2) 局部语义聚类:在局部窗口内,对token的语义嵌入进行聚类,将语义相似的token合并成一个token。3) 异构粒度分配:根据语义密度(例如,聚类簇的大小或簇内token的方差)调整token的粒度。在语义密度高的区域使用更细粒度的token,在语义密度低的区域使用更粗粒度的token。
关键创新:SemToken的关键创新在于将语义信息融入到分词过程中,打破了传统分词方法仅依赖频率统计的局限。通过语义聚类和异构粒度分配,SemToken能够更有效地压缩长文本,减少token数量,同时保留重要的语义信息。与现有方法相比,SemToken能够更好地适应长文本的特点,提高模型的效率和性能。
关键设计:在语义嵌入提取阶段,可以使用预训练的语言模型或从头开始训练的轻量级编码器。局部语义聚类可以使用K-means等聚类算法,需要设置合适的窗口大小和聚类数量。异构粒度分配可以基于语义密度的阈值进行调整,需要根据具体的任务和数据集进行优化。损失函数可以包括语言建模损失和聚类损失,以保证模型能够学习到有效的语义表示。
🖼️ 关键图片
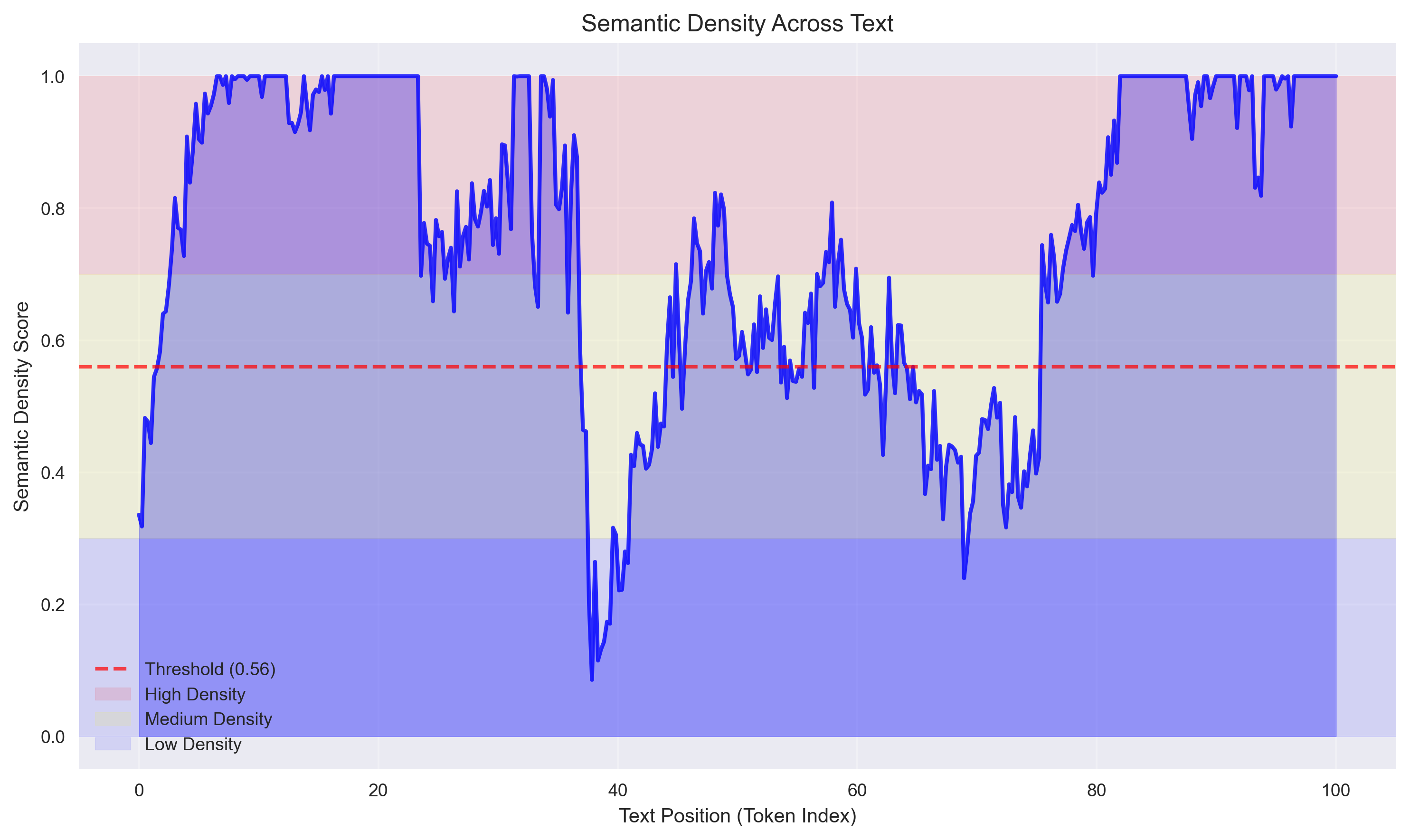
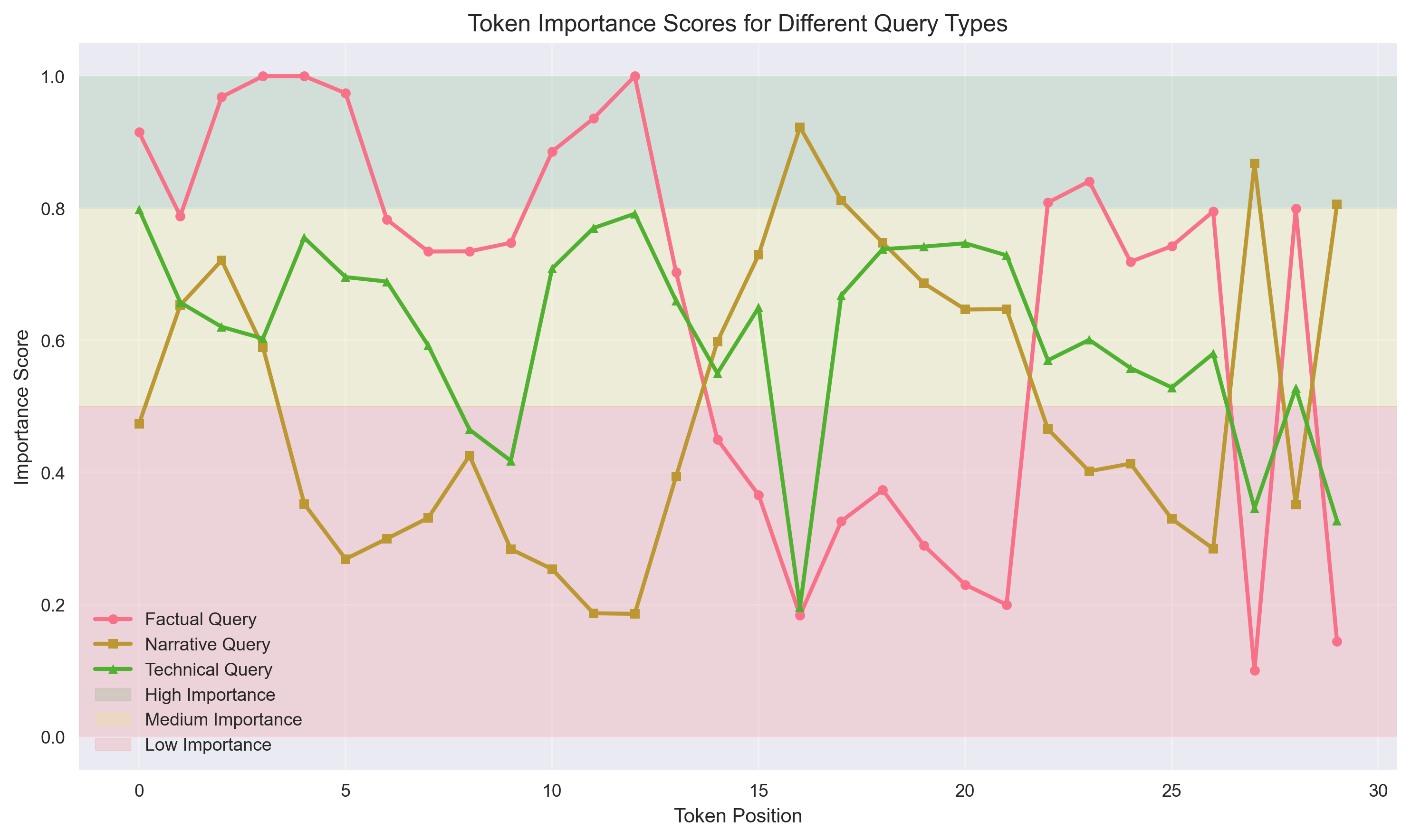
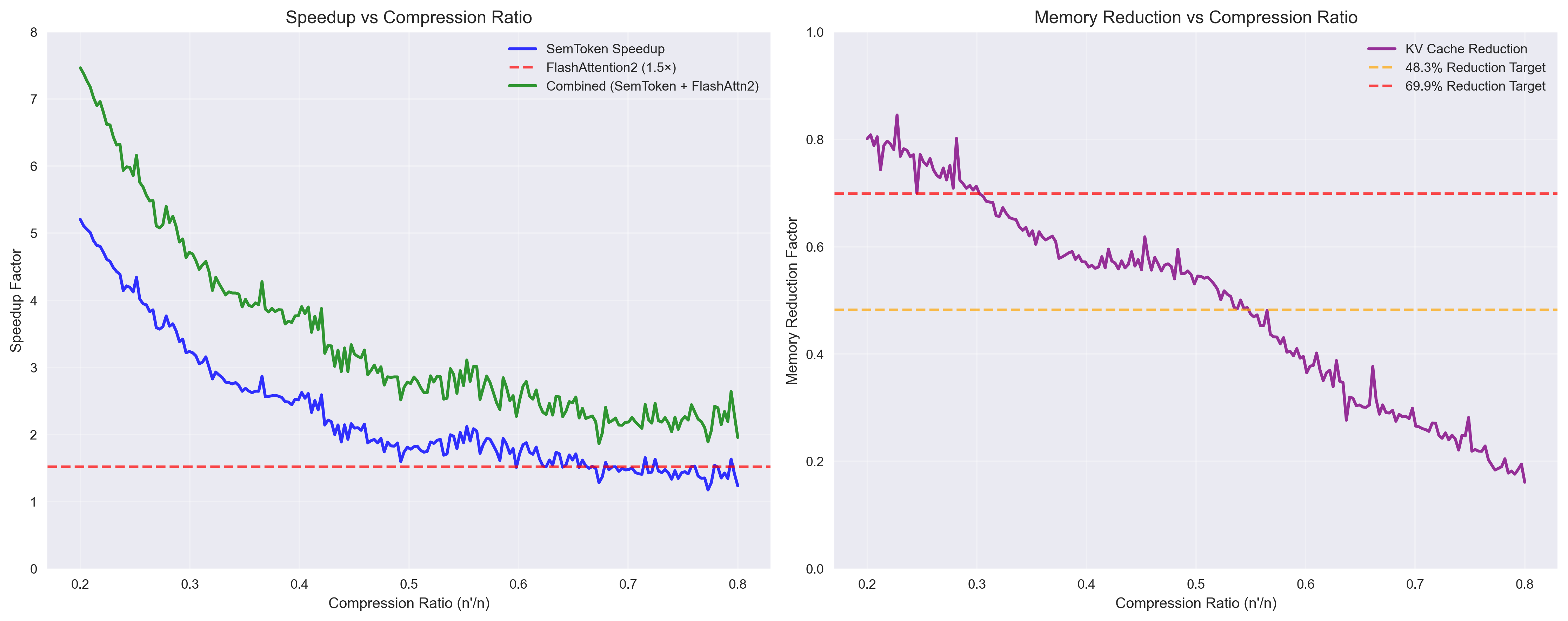
📊 实验亮点
在WikiText-103和LongBench等长文本语言建模基准测试中,SemToken实现了高达2.4倍的token数量减少和1.9倍的加速,同时困惑度和下游任务准确性几乎没有下降或没有下降。这些结果表明,SemToken在提高长文本建模效率方面具有显著优势,且不会牺牲模型性能。
🎯 应用场景
SemToken适用于各种需要处理长文本的自然语言处理任务,例如长文档摘要、机器翻译、问答系统和代码生成等。通过减少token数量和提高计算效率,SemToken可以降低计算成本,并使大型语言模型能够处理更长的上下文,从而提升模型在这些任务上的性能。该方法也有助于在资源受限的设备上部署大型语言模型。
📄 摘要(原文)
Tokenization plays a critical role in language modeling, yet existing approaches such as Byte-Pair Encoding (BPE) or WordPiece operate purely on frequency statistics, ignoring the underlying semantic structure of text. This leads to over-tokenization of semantically redundant spans and underutilization of contextual coherence, particularly in long-context scenarios. In this work, we propose \textbf{SemToken}, a semantic-aware tokenization framework that jointly reduces token redundancy and improves computation efficiency. SemToken first extracts contextual semantic embeddings via lightweight encoders and performs local semantic clustering to merge semantically equivalent tokens. Then, it allocates heterogeneous token granularity based on semantic density, allowing finer-grained tokenization in content-rich regions and coarser compression in repetitive or low-entropy spans. SemToken can be seamlessly integrated with modern language models and attention acceleration methods. Experiments on long-context language modeling benchmarks such as WikiText-103 and LongBench show that SemToken achieves up to $2.4\times$ reduction in token count and $1.9\times$ speedup, with negligible or no degradation in perplexity and downstream accuracy. Our findings suggest that semantic structure offers a promising new axis for optimizing tokenization and computation in large language models.