Identifying and Answering Questions with False Assumptions: An Interpretable Approach
作者: Zijie Wang, Eduardo Blanco
分类: cs.CL
发布日期: 2025-08-21 (更新: 2025-09-22)
备注: To appear at EMNLP 2025 Main conference
💡 一句话要点
提出一种可解释的方法,用于识别并回答带有错误假设的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 错误假设识别 问题回答 大型语言模型 知识检索 可解释性
📋 核心要点
- 大型语言模型在回答带有错误假设的问题时,容易产生幻觉,给出误导性答案。
- 该论文提出一种利用外部证据缓解幻觉的方法,通过生成和验证原子假设来识别错误假设。
- 实验结果表明,结合检索到的证据以及生成和验证原子假设的方法,可以有效提升模型性能。
📝 摘要(中文)
人们经常提出带有错误假设的问题,这类问题没有常规答案。回答这类问题首先需要识别出错误的假设。大型语言模型(LLMs)由于幻觉,经常对这些问题产生误导性的答案。本文重点研究在多个领域中识别和回答带有错误假设的问题。我们首先研究这个问题是否可以简化为事实核查。然后,我们提出了一种利用外部证据来减轻幻觉的方法。对五个LLM的实验表明:(1)结合检索到的证据是有益的;(2)生成和验证原子假设可以带来更多改进,并通过查明错误的假设来提供可解释的答案。
🔬 方法详解
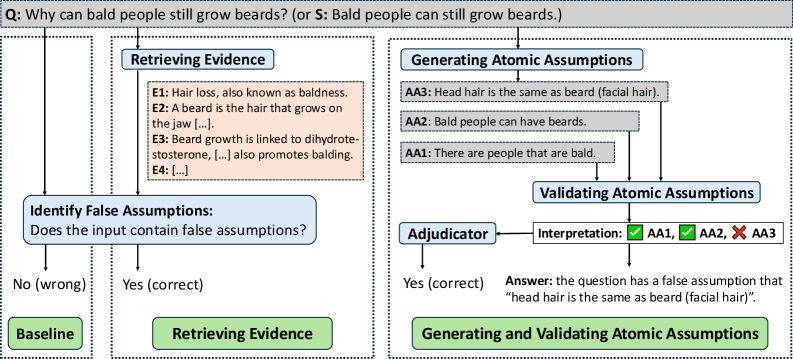
问题定义:论文旨在解决大型语言模型(LLMs)在回答带有错误假设的问题时,容易产生幻觉并给出误导性答案的问题。现有方法缺乏有效识别和纠正这些错误假设的机制,导致LLMs无法给出准确且可信的回答。
核心思路:论文的核心思路是利用外部知识来验证问题中隐含的假设,并通过生成和验证原子假设来精确定位错误的假设。通过引入外部证据,可以有效地减少LLMs的幻觉,并提高回答的准确性和可解释性。
技术框架:该方法主要包含以下几个阶段:1) 问题分析:分析输入问题,提取关键信息。2) 证据检索:利用检索模型从外部知识库中检索相关证据。3) 原子假设生成:基于问题和检索到的证据,生成一系列原子假设。4) 原子假设验证:利用LLM或专门的事实核查模型验证每个原子假设的真伪。5) 答案生成:基于验证结果,生成最终答案,并指出问题中存在的错误假设。
关键创新:该方法最重要的创新点在于将问题分解为一系列可验证的原子假设,并通过外部证据来验证这些假设。这种方法不仅可以提高回答的准确性,还可以提供可解释的答案,让用户了解LLM做出决策的原因。
关键设计:在原子假设生成阶段,需要设计有效的提示工程(prompt engineering)来引导LLM生成高质量的原子假设。在原子假设验证阶段,可以选择不同的验证模型,例如基于Transformer的事实核查模型。此外,还需要设计合适的损失函数来训练验证模型,使其能够准确判断原子假设的真伪。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在五个大型语言模型上均取得了显著的性能提升。通过结合检索到的证据,模型的回答准确性得到了有效提高。更重要的是,生成和验证原子假设的方法能够进一步提升性能,并提供可解释的答案,清晰地指出问题中存在的错误假设。具体性能数据未知。
🎯 应用场景
该研究成果可应用于智能问答系统、对话机器人、搜索引擎等领域,提高这些系统在处理带有错误假设问题时的准确性和可靠性。通过识别和纠正错误假设,可以避免系统给出误导性或错误的答案,从而提升用户体验和信任度。此外,该方法还可以用于教育领域,帮助学生识别和纠正思维中的错误假设。
📄 摘要(原文)
People often ask questions with false assumptions, a type of question that does not have regular answers. Answering such questions requires first identifying the false assumptions. Large Language Models (LLMs) often generate misleading answers to these questions because of hallucinations. In this paper, we focus on identifying and answering questions with false assumptions in several domains. We first investigate whether the problem reduces to fact verification. Then, we present an approach leveraging external evidence to mitigate hallucinations. Experiments with five LLMs demonstrate that (1) incorporating retrieved evidence is beneficial and (2) generating and validating atomic assumptions yields more improvements and provides an interpretable answer by pinpointing the false assumptions.