ALAS: Autonomous Learning Agent for Self-Updating Language Models
作者: Dhruv Atreja
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-08-14
💡 一句话要点
ALAS:用于自更新语言模型的自主学习Agent,解决LLM知识截止问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自主学习 知识更新 大型语言模型 持续学习 信息检索
📋 核心要点
- 大型语言模型存在知识截止日期,无法及时获取和利用最新的信息,导致回答准确性下降。
- ALAS通过自主生成学习课程、检索最新信息、提炼数据并微调模型,实现LLM知识的持续更新。
- 实验表明,ALAS在快速发展的领域显著提高了LLM的问答准确性,平均从15%提升至90%。
📝 摘要(中文)
大型语言模型(LLMs)通常具有固定的知识截止日期,限制了它们在新兴信息上的准确性。我们提出了ALAS(自主学习Agent系统),这是一个模块化pipeline,可在最少的人工干预下持续更新LLM的知识。ALAS自主地为目标领域生成学习课程,从网络检索最新的信息(带有引用),将其提炼成问答训练数据,并通过监督微调(SFT)和直接偏好优化(DPO)来微调模型。它迭代地评估性能并修改课程,从而实现长期的持续学习。我们展示了ALAS在快速发展的领域(例如,新的Python版本、最新的安全CVE、学术趋势)中自我改进模型的能力,在没有手动数据集管理的情况下,显著提高了截止日期后的问答准确性(平均从15%提高到90%)。该系统强调模块化和可重复性:每个组件(计划、检索、提炼、记忆、微调)都是可互换的,并且建立在标准API之上。我们讨论了比较基线(例如,检索增强生成与微调),并表明ALAS以最小的工程开销实现了90%的知识更新查询准确性。最后,我们概述了局限性(成本、对源质量的依赖性)以及LLM中自主终身学习的未来方向。
🔬 方法详解
问题定义:大型语言模型(LLMs)的知识存在固定的截止日期,无法及时获取和利用最新的信息,导致在回答关于新出现的事件、技术或趋势的问题时准确性显著下降。现有的方法,如人工标注数据集进行微调,成本高昂且难以跟上信息更新的速度。检索增强生成(RAG)虽然可以利用外部知识,但仍然依赖于检索的准确性和模型的推理能力,且无法真正更新模型的内部知识。
核心思路:ALAS的核心思路是构建一个自主学习Agent,使其能够像人类学习者一样,主动发现需要学习的新知识,并利用这些知识来更新自身的模型参数。通过自动化学习课程生成、信息检索、数据提炼和模型微调等步骤,ALAS能够持续地提升LLM的知识水平,而无需过多的人工干预。
技术框架:ALAS包含以下主要模块:1) 课程规划器:自主生成学习课程,确定需要学习的领域和主题。2) 信息检索器:从网络上检索最新的相关信息,并进行引用标注。3) 数据提炼器:将检索到的信息提炼成高质量的问答训练数据。4) 记忆模块:存储和管理已学习的知识,避免重复学习。5) 微调模块:使用监督微调(SFT)和直接偏好优化(DPO)等方法,利用提炼后的数据来更新LLM的参数。
关键创新:ALAS的关键创新在于其完全自主的学习流程。它摆脱了对人工标注数据的依赖,能够根据LLM自身的知识水平和外部环境的变化,动态地调整学习策略。此外,ALAS的模块化设计使得各个组件可以独立地进行优化和替换,提高了系统的灵活性和可扩展性。
关键设计:ALAS在课程规划阶段,可能使用LLM本身来生成学习目标,并根据模型的回答情况调整学习难度。在信息检索阶段,需要仔细选择信息来源,并对检索结果进行过滤和排序,以保证数据的质量。在数据提炼阶段,可以使用LLM来生成问答对,并进行人工审核。在微调阶段,需要选择合适的学习率、batch size等超参数,并监控模型的训练过程,以避免过拟合。
🖼️ 关键图片
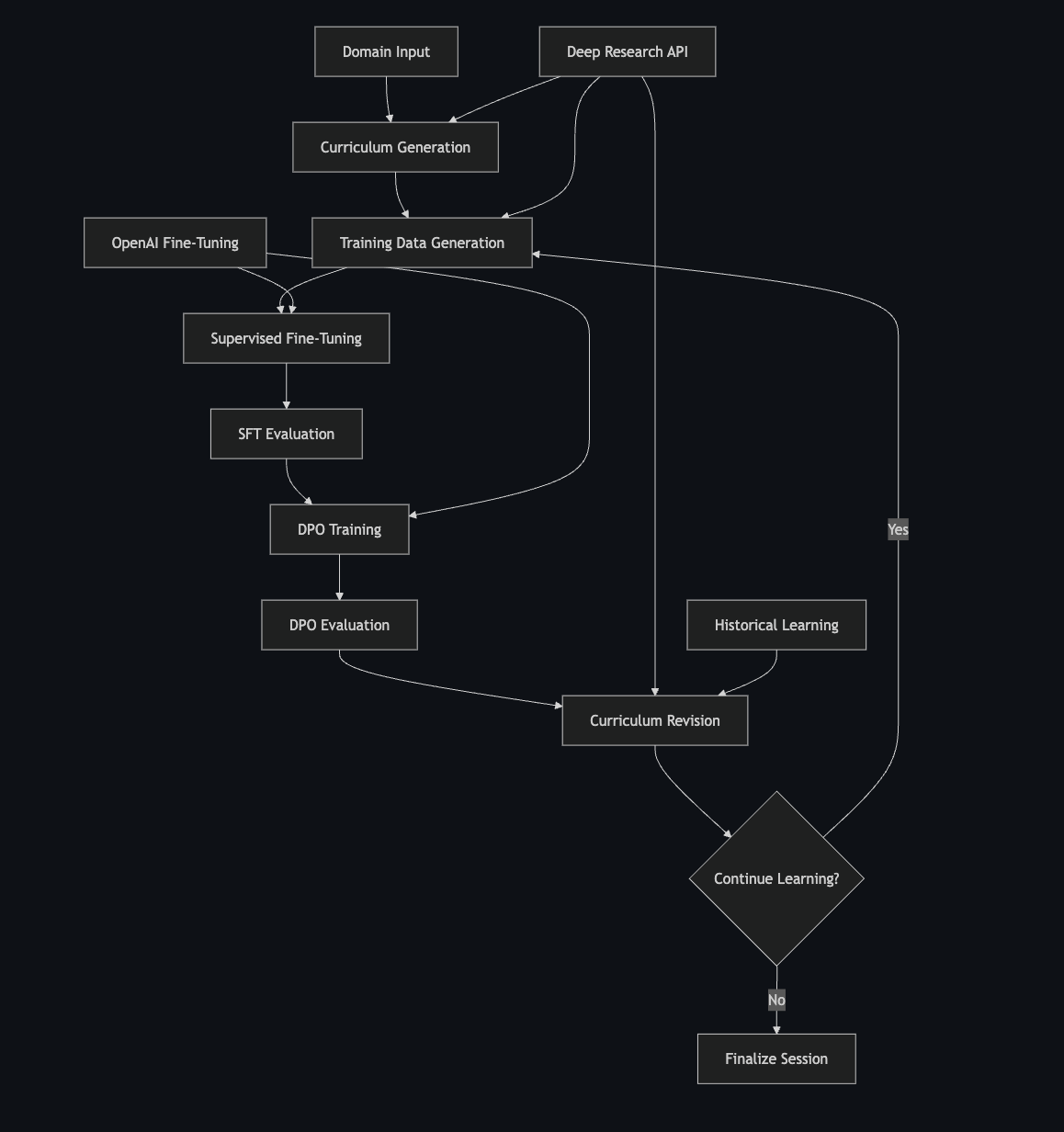
📊 实验亮点
ALAS在快速发展的领域(如新的Python版本、最新的安全CVE、学术趋势)中进行了实验。结果表明,ALAS能够显著提高LLM在截止日期后的问答准确性,平均从15%提升至90%。与检索增强生成等基线方法相比,ALAS在知识更新方面表现出更强的能力,并且只需要最小的工程开销。
🎯 应用场景
ALAS可应用于需要持续更新知识的各种领域,例如金融分析、法律咨询、技术支持等。通过自主学习和知识更新,ALAS可以帮助LLM更好地理解和回答用户的问题,提供更准确、更可靠的信息服务。此外,ALAS还可以用于构建个性化的学习助手,根据用户的知识水平和学习需求,定制学习课程和内容。
📄 摘要(原文)
Large language models (LLMs) often have a fixed knowledge cutoff, limiting their accuracy on emerging information. We present ALAS (Autonomous Learning Agent System), a modular pipeline that continuously updates an LLM's knowledge with minimal human intervention. ALAS autonomously generates a learning curriculum for a target domain, retrieves up-to-date information from the web (with citations), distills this into question-answer training data, and fine-tunes the model through supervised fine-tuning (SFT) and direct preference optimization (DPO). It iteratively evaluates performance and revises the curriculum, enabling long-term continual learning. We demonstrate ALAS's ability to self-improve a model on rapidly evolving domains (e.g., new Python releases, latest security CVEs, academic trends), significantly boosting post-cutoff question answering accuracy (from 15% to 90% on average) without manual dataset curation. The system emphasizes modularity and reproducibility: each component (planning, retrieval, distillation, memory, fine-tuning) is interchangeable and built on standard APIs. We discuss comparative baselines (e.g., retrieval-augmented generation vs. fine-tuning) and show that ALAS achieves 90% accuracy on knowledge-updated queries with minimal engineering overhead. Finally, we outline limitations (cost, dependency on source quality) and future directions for autonomous lifelong learning in LLMs.