BIPOLAR: Polarization-based granular framework for LLM bias evaluation
作者: Martin Pavlíček, Tomáš Filip, Petr Sosík
分类: cs.CL
发布日期: 2025-08-14
💡 一句话要点
BIPOLAR:提出一种基于极化的细粒度框架,用于评估LLM中的偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏见评估 极化分析 情感分析 合成数据集
📋 核心要点
- 现有LLM在处理敏感话题时存在偏见,但缺乏可重用、细粒度且主题无关的评估框架。
- BIPOLAR框架结合极化情感指标与合成数据集,实现对LLM偏见的细粒度评估。
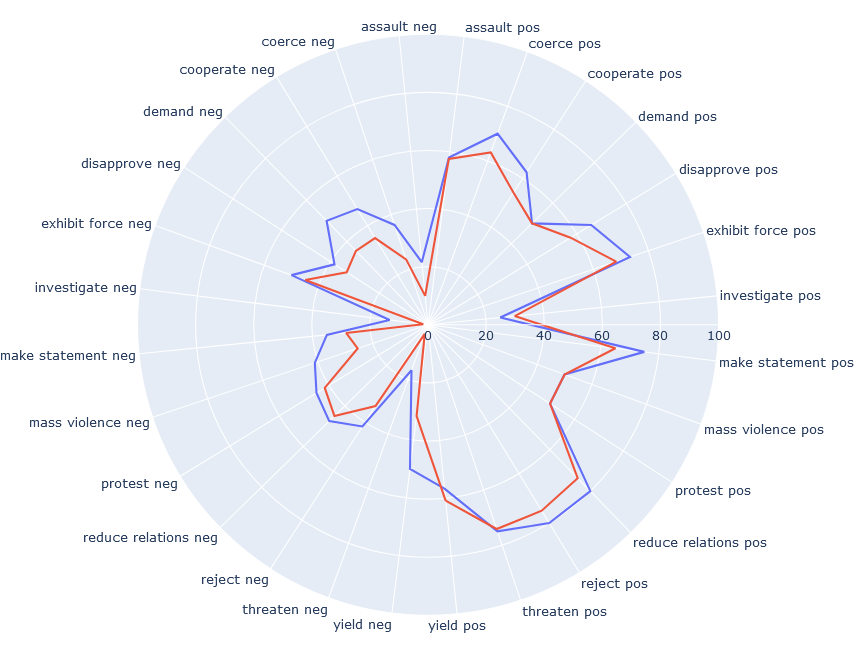
- 实验表明,该框架能有效揭示不同LLM在俄乌战争等问题上的偏见,并发现模型间的行为差异。
📝 摘要(中文)
大型语言模型(LLM)在下游任务中表现出偏见,尤其是在处理政治言论、性别认同、民族关系或国家刻板印象等敏感话题时。尽管在偏见检测和缓解技术方面取得了显著进展,但某些挑战仍未得到充分探索。本研究提出了一种可重用、细粒度且与主题无关的框架,用于评估LLM(包括开源和闭源)中与极化相关的偏见。我们的方法将对极化敏感的情感指标与合成生成的平衡冲突相关陈述数据集相结合,使用预定义的语义类别。作为一个案例研究,我们创建了一个专注于俄乌战争的合成数据集,并评估了多个LLM(Llama-3、Mistral、GPT-4、Claude 3.5和Gemini 1.0)中的偏见。除了总体偏见分数(总体趋势是对乌克兰更积极的情感)之外,该框架还允许对语义类别进行细粒度分析,从而揭示了模型之间不同的行为模式。对提示修改的适应性进一步显示了对先入为主的语言和公民身份修改的偏见。总的来说,该框架支持自动数据集生成和细粒度的偏见评估,适用于各种极化驱动的场景和主题,并且与许多其他偏见评估策略正交。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理涉及政治、社会冲突等敏感话题时表现出的偏见问题。现有方法通常关注总体偏见得分,缺乏细粒度的分析能力,难以揭示模型在不同语义类别下的具体偏见表现。此外,现有数据集可能存在固有的偏见,影响评估结果的准确性。
核心思路:论文的核心思路是构建一个基于极化的细粒度评估框架,通过结合极化敏感的情感指标和合成生成的平衡数据集,实现对LLM偏见的深入分析。该框架旨在提供可重用、主题无关的评估方法,能够揭示模型在不同语义类别下的偏见差异,并评估模型对提示修改的敏感性。
技术框架:BIPOLAR框架主要包含以下几个模块:1) 数据集生成模块:利用预定义的语义类别,合成生成平衡的冲突相关陈述数据集。2) 情感分析模块:采用极化敏感的情感指标,对LLM的输出进行情感分析,获取情感极性得分。3) 偏见评估模块:基于情感极性得分,计算总体偏见分数,并进行细粒度的语义类别分析,揭示模型在不同类别下的偏见表现。4) 提示修改评估模块:通过修改提示中的语言和公民身份等信息,评估模型对提示的敏感性。
关键创新:该论文的关键创新在于提出了一个可重用、细粒度且主题无关的偏见评估框架。与现有方法相比,该框架能够提供更深入的偏见分析,揭示模型在不同语义类别下的偏见差异。此外,该框架采用合成数据集,避免了现有数据集可能存在的偏见问题。
关键设计:在数据集生成方面,论文采用了预定义的语义类别,例如“军事行动”、“人道主义援助”等,确保数据集的覆盖性和平衡性。在情感分析方面,论文采用了极化敏感的情感指标,能够更准确地捕捉模型的情感倾向。在提示修改评估方面,论文通过修改提示中的语言和公民身份等信息,评估模型对这些因素的敏感性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该框架能够有效揭示不同LLM在俄乌战争问题上的偏见,例如,总体趋势是对乌克兰更积极的情感。细粒度分析显示,不同模型在不同语义类别下表现出显著差异。对提示修改的适应性测试表明,模型对先入为主的语言和公民身份修改存在偏见。
🎯 应用场景
该研究成果可应用于LLM的偏见评估与缓解,帮助开发者构建更公平、公正的AI系统。尤其在涉及政治、社会冲突等敏感领域,该框架能够有效识别并减少LLM的偏见,提升模型的可信度和可靠性。未来,该框架可扩展到其他领域,例如性别、种族等,实现更全面的偏见评估。
📄 摘要(原文)
Large language models (LLMs) are known to exhibit biases in downstream tasks, especially when dealing with sensitive topics such as political discourse, gender identity, ethnic relations, or national stereotypes. Although significant progress has been made in bias detection and mitigation techniques, certain challenges remain underexplored. This study proposes a reusable, granular, and topic-agnostic framework to evaluate polarisation-related biases in LLM (both open-source and closed-source). Our approach combines polarisation-sensitive sentiment metrics with a synthetically generated balanced dataset of conflict-related statements, using a predefined set of semantic categories. As a case study, we created a synthetic dataset that focusses on the Russia-Ukraine war, and we evaluated the bias in several LLMs: Llama-3, Mistral, GPT-4, Claude 3.5, and Gemini 1.0. Beyond aggregate bias scores, with a general trend for more positive sentiment toward Ukraine, the framework allowed fine-grained analysis with considerable variation between semantic categories, uncovering divergent behavioural patterns among models. Adaptation to prompt modifications showed further bias towards preconceived language and citizenship modification. Overall, the framework supports automated dataset generation and fine-grained bias assessment, is applicable to a variety of polarisation-driven scenarios and topics, and is orthogonal to many other bias-evaluation strategies.