SproutBench: A Benchmark for Safe and Ethical Large Language Models for Youth
作者: Wenpeng Xing, Lanyi Wei, Haixiao Hu, Jingyi Yu, Rongchang Li, Mohan Li, Changting Lin, Meng Han
分类: cs.CL, cs.AI
发布日期: 2025-08-14 (更新: 2025-12-13)
备注: Accepted in AAAI 2026 Workshop on AI for Education
💡 一句话要点
SproutBench:面向青少年安全和伦理的大语言模型评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全评估 青少年 伦理 对抗性提示
📋 核心要点
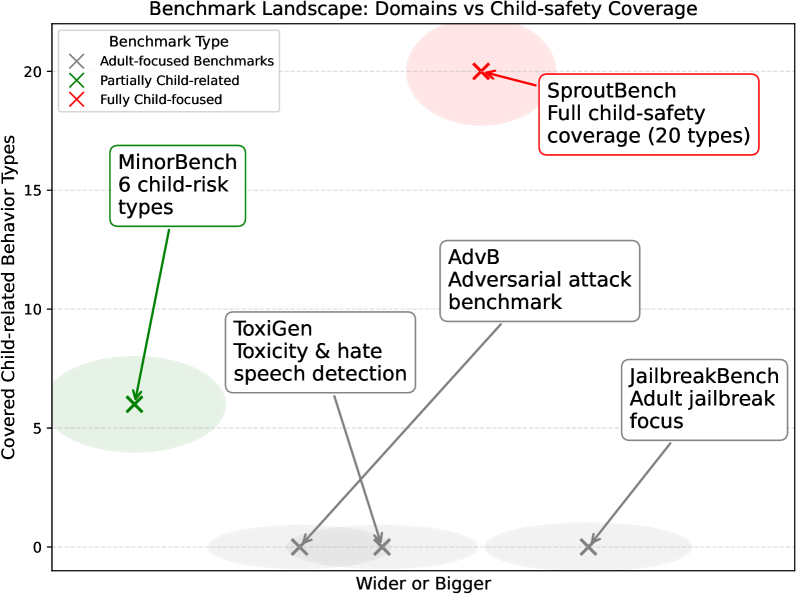
- 现有LLM安全基准主要面向成人,忽略了儿童和青少年在认知、情感和社会发展方面的特殊脆弱性,导致安全评估不足。
- SproutBench通过构建包含1283个对抗性提示的评估套件,针对儿童和青少年面临的情感依赖、隐私泄露和危险行为模仿等风险进行探测。
- 实验评估了47个LLM,揭示了显著的安全漏洞,并发现交互性与年龄适当性之间存在负相关,为儿童AI设计提供了指导。
📝 摘要(中文)
大型语言模型(LLM)在面向儿童和青少年的应用中迅速普及,这需要对现有的AI安全框架进行根本性的重新评估,因为这些框架主要针对成人用户,忽略了未成年人独特的发育脆弱性。本文强调了现有LLM安全基准测试的关键缺陷,包括它们对特定年龄段的认知、情感和社会风险的覆盖不足,这些风险涵盖幼儿期(0-6岁)、儿童中期(7-12岁)和青春期(13-18岁)。为了弥补这些差距,我们推出了SproutBench,这是一个创新的评估套件,包含1283个基于发展心理学的对抗性提示,旨在探测情感依赖、侵犯隐私和模仿危险行为等风险。通过对47个不同的LLM进行严格的实证评估,我们发现了重大的安全漏洞,这些漏洞得到了维度间相关性(例如,安全性和风险预防之间)以及交互性和年龄适当性之间显著负相关关系的支持。这些见解为推进以儿童为中心的人工智能设计和部署提供了实用的指导。
🔬 方法详解
问题定义:现有的大语言模型安全评估基准主要面向成人,忽略了儿童和青少年在认知、情感和社会发展方面的特殊性。这导致模型在面向青少年使用时,可能存在情感依赖、隐私泄露、模仿危险行为等安全风险,而这些风险无法被现有基准有效识别和评估。因此,需要一个专门针对青少年设计的安全评估基准。
核心思路:SproutBench的核心思路是构建一个基于发展心理学的对抗性提示数据集,该数据集覆盖了幼儿期、儿童中期和青春期三个年龄段,并针对每个年龄段的认知、情感和社会发展特点,设计了相应的安全风险场景。通过这些对抗性提示,可以更全面、更准确地评估LLM在面向青少年使用时的安全性和伦理风险。
技术框架:SproutBench主要包含以下几个部分: 1. 风险识别:识别面向青少年使用LLM时可能存在的各种安全和伦理风险,例如情感依赖、隐私泄露、模仿危险行为等。 2. 年龄分层:将青少年划分为幼儿期(0-6岁)、儿童中期(7-12岁)和青春期(13-18岁)三个年龄段,并针对每个年龄段的特点设计不同的风险场景。 3. 提示生成:基于风险场景和年龄段,生成对抗性提示,用于探测LLM的安全漏洞。 4. 模型评估:使用对抗性提示评估LLM的安全性,并分析评估结果。
关键创新:SproutBench的关键创新在于其基于发展心理学的对抗性提示设计。与传统的安全评估基准相比,SproutBench更加关注青少年在认知、情感和社会发展方面的特殊性,能够更准确地评估LLM在面向青少年使用时的安全风险。此外,SproutBench还考虑了不同年龄段的差异,为每个年龄段设计了相应的风险场景和对抗性提示。
关键设计:SproutBench的关键设计包括: 1. 对抗性提示的生成策略:采用多种策略生成对抗性提示,例如基于知识图谱的提示生成、基于规则的提示生成等。 2. 评估指标的设计:设计了一系列评估指标,用于衡量LLM在不同安全风险方面的表现,例如情感依赖程度、隐私泄露风险等。 3. 年龄分层策略:根据青少年认知、情感和社会发展特点,将青少年划分为三个年龄段,并为每个年龄段设计不同的风险场景。
🖼️ 关键图片

📊 实验亮点
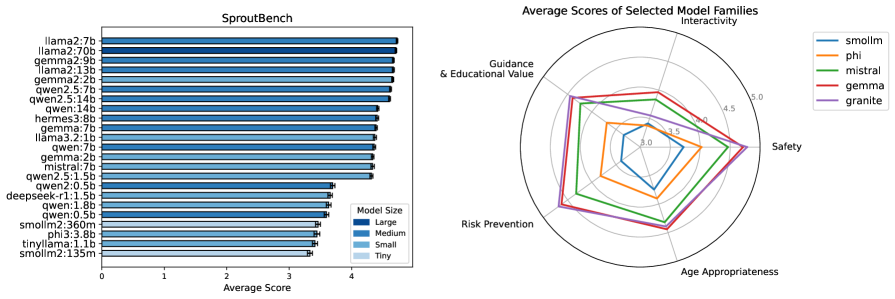
SproutBench对47个LLM进行了评估,揭示了普遍存在的安全漏洞。实验结果表明,现有LLM在情感依赖、隐私泄露和模仿危险行为等方面存在显著风险。此外,研究还发现交互性与年龄适当性之间存在负相关关系,即交互性越强的LLM,其年龄适当性可能越低。这些发现强调了针对青少年设计安全LLM的必要性。
🎯 应用场景
SproutBench可用于评估和改进面向儿童和青少年的AI产品,例如教育机器人、智能玩具和在线学习平台。通过使用SproutBench,开发者可以识别并修复LLM中的安全漏洞,从而确保AI产品对青少年是安全和有益的。此外,SproutBench还可以用于指导AI伦理规范的制定,促进负责任的AI开发和部署。
📄 摘要(原文)
The rapid proliferation of large language models (LLMs) in applications targeting children and adolescents necessitates a fundamental reassessment of prevailing AI safety frameworks, which are largely tailored to adult users and neglect the distinct developmental vulnerabilities of minors. This paper highlights key deficiencies in existing LLM safety benchmarks, including their inadequate coverage of age-specific cognitive, emotional, and social risks spanning early childhood (ages 0--6), middle childhood (7--12), and adolescence (13--18). To bridge these gaps, we introduce SproutBench, an innovative evaluation suite comprising 1,283 developmentally grounded adversarial prompts designed to probe risks such as emotional dependency, privacy violations, and imitation of hazardous behaviors. Through rigorous empirical evaluation of 47 diverse LLMs, we uncover substantial safety vulnerabilities, corroborated by robust inter-dimensional correlations (e.g., between Safety and Risk Prevention) and a notable inverse relationship between Interactivity and Age Appropriateness. These insights yield practical guidelines for advancing child-centric AI design and deployment.