Rule2Text: A Framework for Generating and Evaluating Natural Language Explanations of Knowledge Graph Rules
作者: Nasim Shirvani-Mahdavi, Chengkai Li
分类: cs.CL, cs.AI
发布日期: 2025-08-14
备注: arXiv admin note: text overlap with arXiv:2507.23740
🔗 代码/项目: GITHUB
💡 一句话要点
Rule2Text框架利用大语言模型为知识图谱规则生成自然语言解释,提升可理解性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 规则挖掘 自然语言生成 大型语言模型 可解释性
📋 核心要点
- 知识图谱规则挖掘结果难以理解,因为规则复杂且KG标签约定各异,阻碍了知识图谱的广泛应用。
- Rule2Text框架利用大型语言模型,将知识图谱的逻辑规则转化为自然语言解释,提升规则的可理解性。
- 实验表明,通过微调Zephyr模型,显著提高了自然语言解释的质量,尤其是在特定领域的数据集上。
📝 摘要(中文)
知识图谱(KG)可以通过规则挖掘得到增强;然而,由于其固有的复杂性和各个KG的特殊标签约定,由此产生的逻辑规则对人类来说通常难以理解。本文提出了Rule2Text,这是一个综合框架,它利用大型语言模型(LLM)为挖掘出的逻辑规则生成自然语言解释,从而提高KG的可访问性和可用性。我们使用多个数据集(包括Freebase变体FB-CVT-REV、FB+CVT-REV和FB15k-237以及ogbl-biokg数据集,规则使用AMIE 3.5.1挖掘)进行了广泛的实验。我们系统地评估了多种LLM在各种提示策略下的性能,包括零样本、少样本、变量类型合并和思维链推理。为了系统地评估模型的性能,我们对生成的解释的正确性和清晰度进行了人工评估。为了解决评估的可扩展性问题,我们开发并验证了一个LLM-as-a-judge框架,该框架与人类评估者表现出很强的一致性。利用性能最佳的模型(Gemini 2.0 Flash)、LLM judge和人工反馈,我们构建了高质量的ground truth数据集,并使用它们来微调开源Zephyr模型。我们的结果表明,微调后解释质量显著提高,在特定领域数据集上尤其如此。此外,我们集成了一个类型推断模块,以支持缺乏显式类型信息的KG。所有代码和数据均可在https://github.com/idirlab/KGRule2NL公开获取。
🔬 方法详解
问题定义:论文旨在解决知识图谱中挖掘出的逻辑规则难以被人类理解的问题。现有方法主要依赖人工构建模板或简单的规则转换,无法有效处理复杂规则和不同知识图谱的标签差异,导致解释质量不高,可泛化性差。
核心思路:论文的核心思路是利用大型语言模型的强大生成能力,将复杂的逻辑规则转化为自然、易懂的自然语言解释。通过设计合适的提示策略和微调,使LLM能够理解规则的语义,并生成准确、清晰的解释。
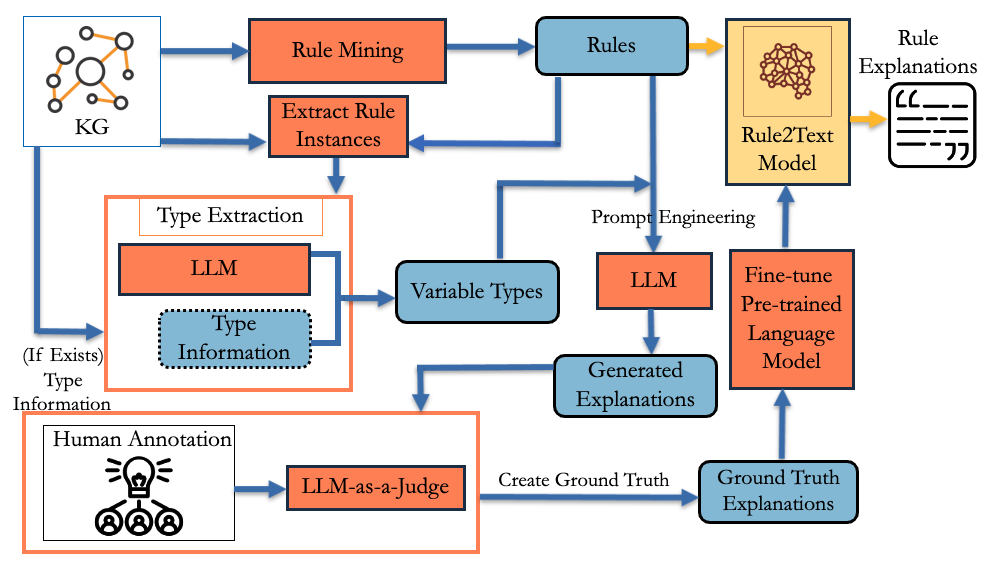
技术框架:Rule2Text框架主要包含以下几个模块:1) 规则解析模块:解析知识图谱中挖掘出的逻辑规则,提取规则的结构和实体关系。2) 提示生成模块:根据规则的结构和实体关系,设计不同的提示策略,包括零样本、少样本、变量类型合并和思维链推理等。3) LLM生成模块:利用大型语言模型,根据提示生成自然语言解释。4) 评估模块:采用人工评估和LLM-as-a-judge框架,对生成的解释进行质量评估。5) 微调模块:利用高质量的ground truth数据集,对开源LLM进行微调,进一步提高解释质量。
关键创新:论文的关键创新在于:1) 提出了一个完整的框架,将LLM应用于知识图谱规则的自然语言解释。2) 系统地研究了多种提示策略对解释质量的影响。3) 开发并验证了一个LLM-as-a-judge框架,用于自动评估解释质量。4) 通过微调开源LLM,显著提高了解释质量,尤其是在特定领域的数据集上。
关键设计:论文的关键设计包括:1) 提示策略的设计:针对不同的规则结构和实体关系,设计了多种提示策略,以提高LLM的生成效果。2) LLM-as-a-judge框架的设计:利用LLM对生成的解释进行自动评估,并与人工评估结果进行对比,验证了LLM-as-a-judge框架的有效性。3) 微调数据集的构建:利用人工评估和LLM-as-a-judge框架,构建了高质量的ground truth数据集,用于微调开源LLM。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Rule2Text框架能够有效地将知识图谱规则转化为自然语言解释。通过微调Zephyr模型,在特定领域数据集上,解释质量得到了显著提高。LLM-as-a-judge框架与人工评估结果表现出很强的一致性,验证了其有效性。Gemini 2.0 Flash 在多种提示策略下表现出良好的性能。
🎯 应用场景
该研究成果可应用于知识图谱的可视化、知识图谱的自动问答、智能推荐系统等领域。通过将复杂的知识图谱规则转化为自然语言解释,可以提高知识图谱的可理解性和可用性,促进知识图谱在各个领域的应用。
📄 摘要(原文)
Knowledge graphs (KGs) can be enhanced through rule mining; however, the resulting logical rules are often difficult for humans to interpret due to their inherent complexity and the idiosyncratic labeling conventions of individual KGs. This work presents Rule2Text, a comprehensive framework that leverages large language models (LLMs) to generate natural language explanations for mined logical rules, thereby improving KG accessibility and usability. We conduct extensive experiments using multiple datasets, including Freebase variants (FB-CVT-REV, FB+CVT-REV, and FB15k-237) as well as the ogbl-biokg dataset, with rules mined using AMIE 3.5.1. We systematically evaluate several LLMs across a comprehensive range of prompting strategies, including zero-shot, few-shot, variable type incorporation, and Chain-of-Thought reasoning. To systematically assess models' performance, we conduct a human evaluation of generated explanations on correctness and clarity. To address evaluation scalability, we develop and validate an LLM-as-a-judge framework that demonstrates strong agreement with human evaluators. Leveraging the best-performing model (Gemini 2.0 Flash), LLM judge, and human-in-the-loop feedback, we construct high-quality ground truth datasets, which we use to fine-tune the open-source Zephyr model. Our results demonstrate significant improvements in explanation quality after fine-tuning, with particularly strong gains in the domain-specific dataset. Additionally, we integrate a type inference module to support KGs lacking explicit type information. All code and data are publicly available at https://github.com/idirlab/KGRule2NL.