A Survey on Diffusion Language Models
作者: Tianyi Li, Mingda Chen, Bowei Guo, Zhiqiang Shen
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-08-14 (更新: 2025-12-04)
🔗 代码/项目: GITHUB
💡 一句话要点
综述扩散语言模型:探索并行生成、双向上下文建模及可控生成的新范式。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 自然语言生成 并行生成 双向上下文 去噪扩散概率模型
📋 核心要点
- 自回归语言模型在生成速度和双向上下文建模方面存在局限性,难以实现细粒度的生成控制。
- 扩散语言模型通过迭代去噪并行生成tokens,旨在提升生成速度,捕获双向上下文,并实现更精细的生成控制。
- 最新的扩散语言模型在推理速度上实现了数倍的提升,并且性能可以与自回归模型相媲美,具有很强的竞争力。
📝 摘要(中文)
扩散语言模型(DLMs)正迅速崛起,成为自回归(AR)范式之外一种强大且有前景的替代方案。通过迭代去噪过程并行生成tokens,DLMs在降低推理延迟和捕获双向上下文方面具有内在优势,从而能够对生成过程进行细粒度控制。 近期进展表明,DLMs在实现数倍加速的同时,性能已可与自回归模型相媲美,使其成为各种自然语言处理任务的引人注目的选择。 本文对当前DLM领域进行了全面的概述,追溯了其发展历程以及与其他范式(如自回归和掩码语言模型)的关系,涵盖了基本原理和最先进的模型。 本文提供了一个最新的、全面的分类,并对当前技术进行了深入分析,从预训练策略到高级后训练方法。 此外,本文还全面回顾了DLM推理策略和优化,包括解码并行性、缓存机制和生成质量的改进。 我们还重点介绍了DLM多模态扩展的最新方法,并描述了它们在各种实际场景中的应用。 此外,我们的讨论还涉及DLM的局限性和挑战,包括效率、长序列处理和基础设施要求,同时概述了未来的研究方向,以维持这个快速发展领域的进展。 项目GitHub地址为https://github.com/VILA-Lab/Awesome-DLMs。
🔬 方法详解
问题定义:现有自回归语言模型在生成文本时通常采用串行方式,速度较慢,且难以充分利用双向上下文信息。此外,对生成过程的控制粒度也相对较粗,难以满足特定场景下的需求。因此,如何提升生成速度、增强上下文建模能力以及实现更精细的生成控制是当前语言模型研究面临的重要问题。
核心思路:扩散语言模型借鉴了图像生成领域的扩散模型思想,通过逐步添加噪声将文本数据转化为噪声数据,然后通过学习逆向过程,逐步从噪声数据中恢复出原始文本。这种方式允许并行生成tokens,并能够更好地捕获双向上下文信息。
技术框架:扩散语言模型的整体框架通常包括前向扩散过程和反向去噪过程。在前向扩散过程中,文本数据逐步被加入噪声,直到完全变成噪声数据。在反向去噪过程中,模型学习如何逐步去除噪声,最终生成文本。该过程通常采用迭代的方式进行,每一步都依赖于前一步的结果。
关键创新:扩散语言模型的核心创新在于将扩散模型应用于文本生成任务。与传统的自回归模型不同,扩散语言模型可以并行生成tokens,从而显著提升生成速度。此外,扩散模型能够更好地捕获双向上下文信息,从而生成更连贯、更自然的文本。
关键设计:扩散语言模型的关键设计包括噪声添加策略、去噪网络结构和损失函数设计。噪声添加策略决定了如何将噪声添加到文本数据中,常见的策略包括高斯噪声和掩码噪声。去噪网络结构负责学习如何从噪声数据中恢复出原始文本,常见的结构包括Transformer和卷积神经网络。损失函数用于衡量生成文本与原始文本之间的差异,常见的损失函数包括交叉熵损失和均方误差损失。
🖼️ 关键图片
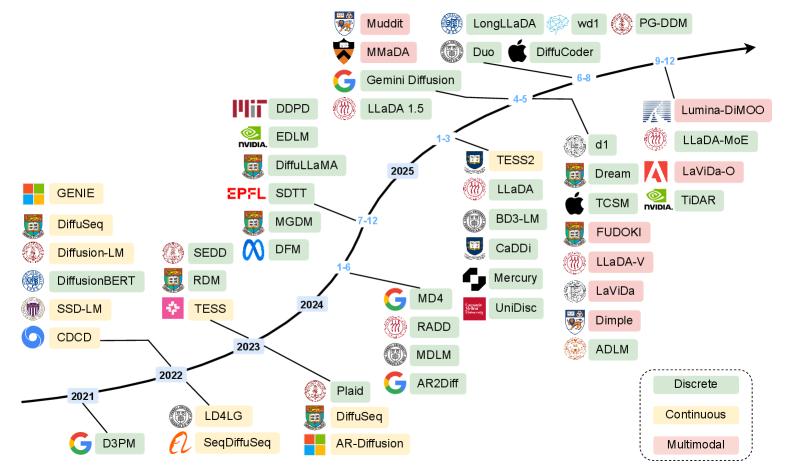
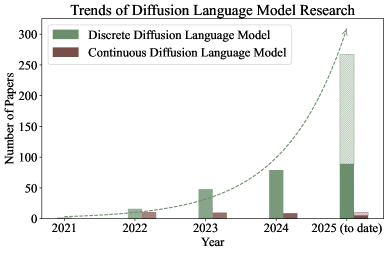
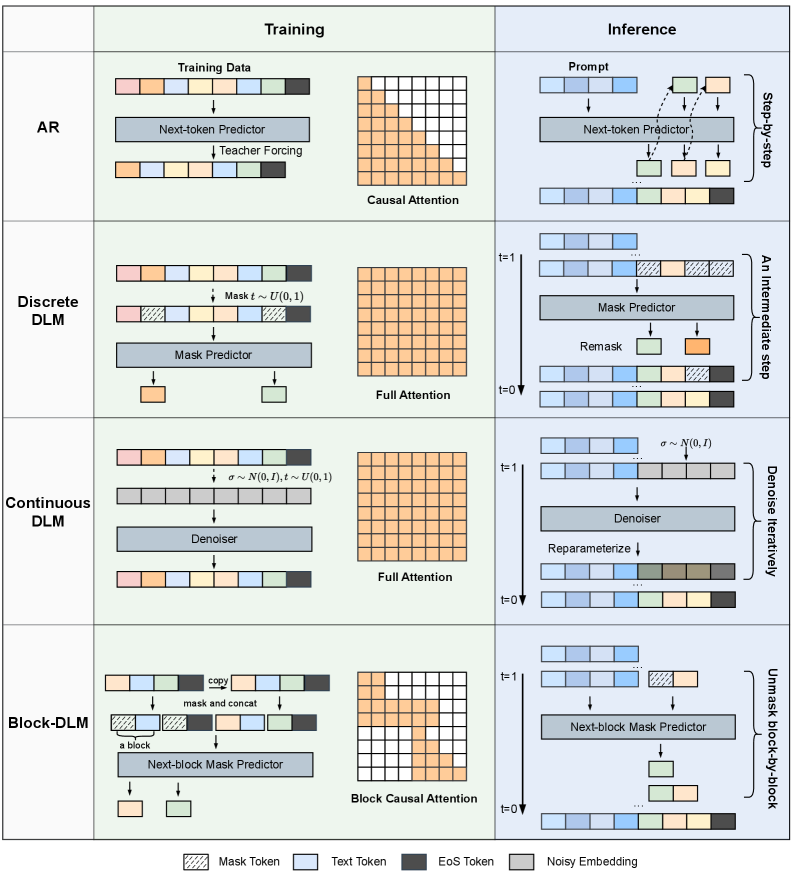
📊 实验亮点
该综述全面回顾了扩散语言模型的研究进展,并对其在自然语言处理领域的应用前景进行了展望。论文总结了当前扩散语言模型面临的挑战,并提出了未来的研究方向,为相关研究人员提供了有价值的参考。该综述还开源了一个包含大量扩散语言模型相关资源的GitHub仓库,方便研究人员快速入门和深入研究。
🎯 应用场景
扩散语言模型在机器翻译、文本摘要、对话生成、代码生成等领域具有广泛的应用前景。其并行生成能力可以显著提升生成速度,使其在对实时性要求较高的场景中具有优势。此外,其双向上下文建模能力可以生成更连贯、更自然的文本,从而提升用户体验。未来,扩散语言模型有望成为自然语言处理领域的重要技术。
📄 摘要(原文)
Diffusion Language Models (DLMs) are rapidly emerging as a powerful and promising alternative to the dominant autoregressive (AR) paradigm. By generating tokens in parallel through an iterative denoising process, DLMs possess inherent advantages in reducing inference latency and capturing bidirectional context, thereby enabling fine-grained control over the generation process. While achieving a several-fold speed-up, recent advancements have allowed DLMs to show performance comparable to their autoregressive counterparts, making them a compelling choice for various natural language processing tasks. In this survey, we provide a holistic overview of the current DLM landscape. We trace its evolution and relationship with other paradigms, such as autoregressive and masked language models, and cover both foundational principles and state-of-the-art models. Our work offers an up-to-date, comprehensive taxonomy and an in-depth analysis of current techniques, from pre-training strategies to advanced post-training methods. Another contribution of this survey is a thorough review of DLM inference strategies and optimizations, including improvements in decoding parallelism, caching mechanisms, and generation quality. We also highlight the latest approaches to multimodal extensions of DLMs and delineate their applications across various practical scenarios. Furthermore, our discussion addresses the limitations and challenges of DLMs, including efficiency, long-sequence handling, and infrastructure requirements, while outlining future research directions to sustain progress in this rapidly evolving field. Project GitHub is available at https://github.com/VILA-Lab/Awesome-DLMs.