SSRL: Self-Search Reinforcement Learning
作者: Yuchen Fan, Kaiyan Zhang, Heng Zhou, Yuxin Zuo, Yanxu Chen, Yu Fu, Xinwei Long, Xuekai Zhu, Che Jiang, Yuchen Zhang, Li Kang, Gang Chen, Cheng Huang, Zhizhou He, Bingning Wang, Lei Bai, Ning Ding, Bowen Zhou
分类: cs.CL
发布日期: 2025-08-14
💡 一句话要点
提出SSRL:利用自搜索强化学习提升大语言模型在Agentic搜索任务中的效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自搜索 强化学习 大语言模型 Agentic搜索 知识利用
📋 核心要点
- 现有Agentic搜索任务依赖昂贵的外部搜索引擎交互,限制了强化学习的效率和可扩展性。
- SSRL通过强化学习增强LLM的自搜索能力,使其在内部迭代改进知识利用,无需外部工具。
- 实验表明,SSRL训练的模型降低了对外部搜索引擎的依赖,并促进了sim-to-real迁移。
📝 摘要(中文)
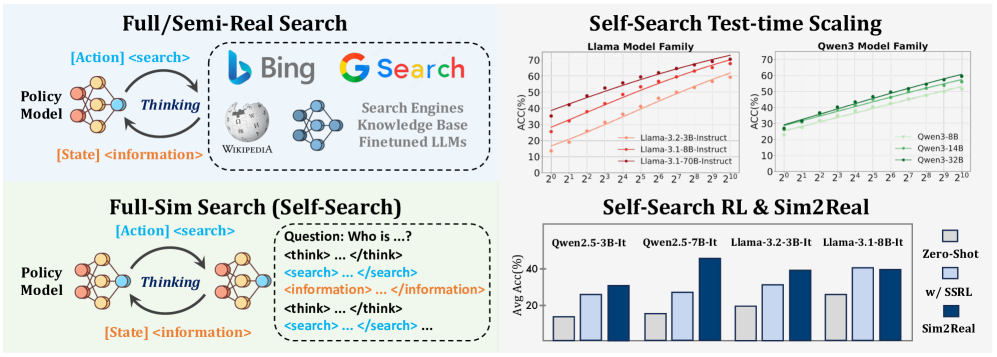
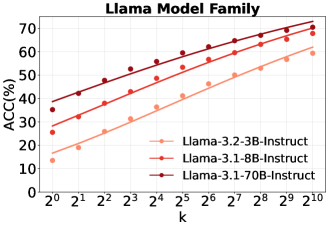
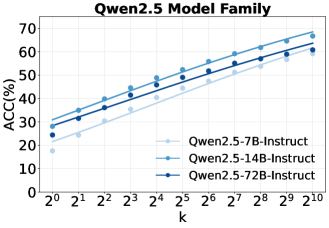
本文研究了大语言模型(LLMs)作为强化学习(RL)中Agentic搜索任务高效模拟器的潜力,从而减少对昂贵外部搜索引擎交互的依赖。首先,通过结构化提示和重复采样量化了LLMs的内在搜索能力,称之为自搜索(Self-Search)。结果表明,LLMs在推理预算方面表现出强大的扩展性,在包括具有挑战性的BrowseComp任务在内的问答基准测试中实现了较高的pass@k。在此基础上,引入了自搜索强化学习(SSRL),通过基于格式和规则的奖励来增强LLMs的自搜索能力。SSRL使模型能够在内部迭代地改进其知识利用,而无需访问外部工具。实验评估表明,SSRL训练的策略模型为搜索驱动的RL训练提供了一个经济高效且稳定的环境,减少了对外部搜索引擎的依赖,并促进了强大的sim-to-real迁移。研究结论:1)LLMs拥有可以有效提取以实现高性能的世界知识;2)SSRL展示了利用内部知识减少幻觉的潜力;3)SSRL训练的模型可以无缝地与外部搜索引擎集成,而无需额外的努力。研究结果突出了LLMs支持更具可扩展性的RL Agent训练的潜力。
🔬 方法详解
问题定义:论文旨在解决Agentic搜索任务中,强化学习智能体对外部搜索引擎的过度依赖问题。现有方法需要频繁与外部环境交互,成本高昂,效率低下,并且可能引入噪声和不稳定性。
核心思路:论文的核心思路是利用大语言模型(LLMs)自身蕴含的知识和推理能力,通过强化学习训练,使其能够进行“自搜索”(Self-Search),即在内部迭代地探索和利用知识,从而减少对外部搜索引擎的依赖。这样可以降低成本,提高效率,并增强模型的鲁棒性。
技术框架:SSRL的技术框架主要包括以下几个阶段:1) 自搜索能力量化:通过结构化提示和重复采样,评估LLMs的内在搜索能力。2) 奖励函数设计:设计基于格式和规则的奖励函数,鼓励LLMs进行有效的自搜索。3) 强化学习训练:使用奖励函数训练LLMs,使其能够迭代地改进知识利用。4) 模型评估:评估SSRL训练的模型在Agentic搜索任务中的性能,并与基线方法进行比较。
关键创新:SSRL的关键创新在于将强化学习与LLMs的自搜索能力相结合,提出了一种新的Agentic搜索范式。与传统方法相比,SSRL不需要频繁与外部环境交互,而是利用LLMs自身的知识和推理能力进行内部探索,从而降低了成本,提高了效率,并增强了模型的鲁棒性。
关键设计:SSRL的关键设计包括:1) 结构化提示:使用结构化的提示来引导LLMs进行自搜索。2) 基于格式和规则的奖励函数:设计奖励函数,鼓励LLMs生成符合特定格式和规则的答案。3) 迭代训练:通过强化学习训练,使LLMs能够迭代地改进其自搜索能力。具体的奖励函数和网络结构等细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SSRL训练的模型在问答基准测试中取得了显著的性能提升,尤其是在具有挑战性的BrowseComp任务中。SSRL还展示了减少幻觉的潜力,并可以无缝地与外部搜索引擎集成。这些结果表明,SSRL是一种有前景的Agentic搜索方法。
🎯 应用场景
SSRL具有广泛的应用前景,可应用于问答系统、知识图谱构建、智能助手等领域。通过减少对外部搜索引擎的依赖,SSRL可以降低成本,提高效率,并增强模型的鲁棒性。未来,SSRL有望成为构建更智能、更高效的Agentic搜索系统的关键技术。
📄 摘要(原文)
We investigate the potential of large language models (LLMs) to serve as efficient simulators for agentic search tasks in reinforcement learning (RL), thereby reducing dependence on costly interactions with external search engines. To this end, we first quantify the intrinsic search capability of LLMs via structured prompting and repeated sampling, which we term Self-Search. Our results reveal that LLMs exhibit strong scaling behavior with respect to the inference budget, achieving high pass@k on question-answering benchmarks, including the challenging BrowseComp task. Building on these observations, we introduce Self-Search RL (SSRL), which enhances LLMs' Self-Search capability through format-based and rule-based rewards. SSRL enables models to iteratively refine their knowledge utilization internally, without requiring access to external tools. Empirical evaluations demonstrate that SSRL-trained policy models provide a cost-effective and stable environment for search-driven RL training, reducing reliance on external search engines and facilitating robust sim-to-real transfer. We draw the following conclusions: 1) LLMs possess world knowledge that can be effectively elicited to achieve high performance; 2) SSRL demonstrates the potential of leveraging internal knowledge to reduce hallucination; 3) SSRL-trained models integrate seamlessly with external search engines without additional effort. Our findings highlight the potential of LLMs to support more scalable RL agent training.