Reinforced Language Models for Sequential Decision Making
作者: Jim Dilkes, Vahid Yazdanpanah, Sebastian Stein
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-08-14
💡 一句话要点
提出MS-GRPO算法,用于提升小规模语言模型在序列决策任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 序列决策 语言模型 后训练 信用分配 策略优化
📋 核心要点
- 现有序列决策LLM依赖大模型,计算成本高,小模型后训练方法难以处理多步任务中的信用分配问题。
- 提出MS-GRPO算法,基于TSMG和LAP框架,将episode总奖励分配给每一步,并引入绝对优势加权采样。
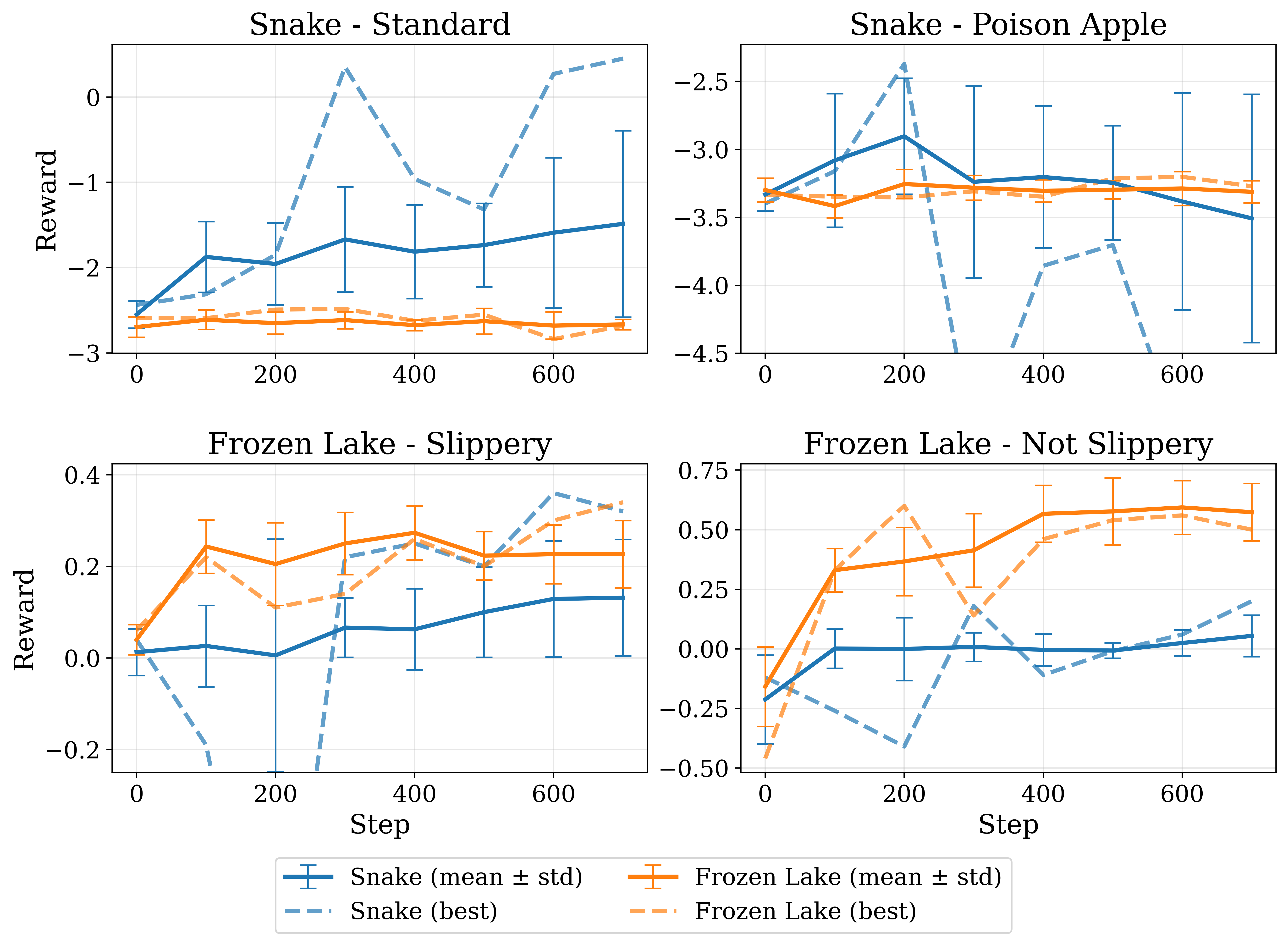
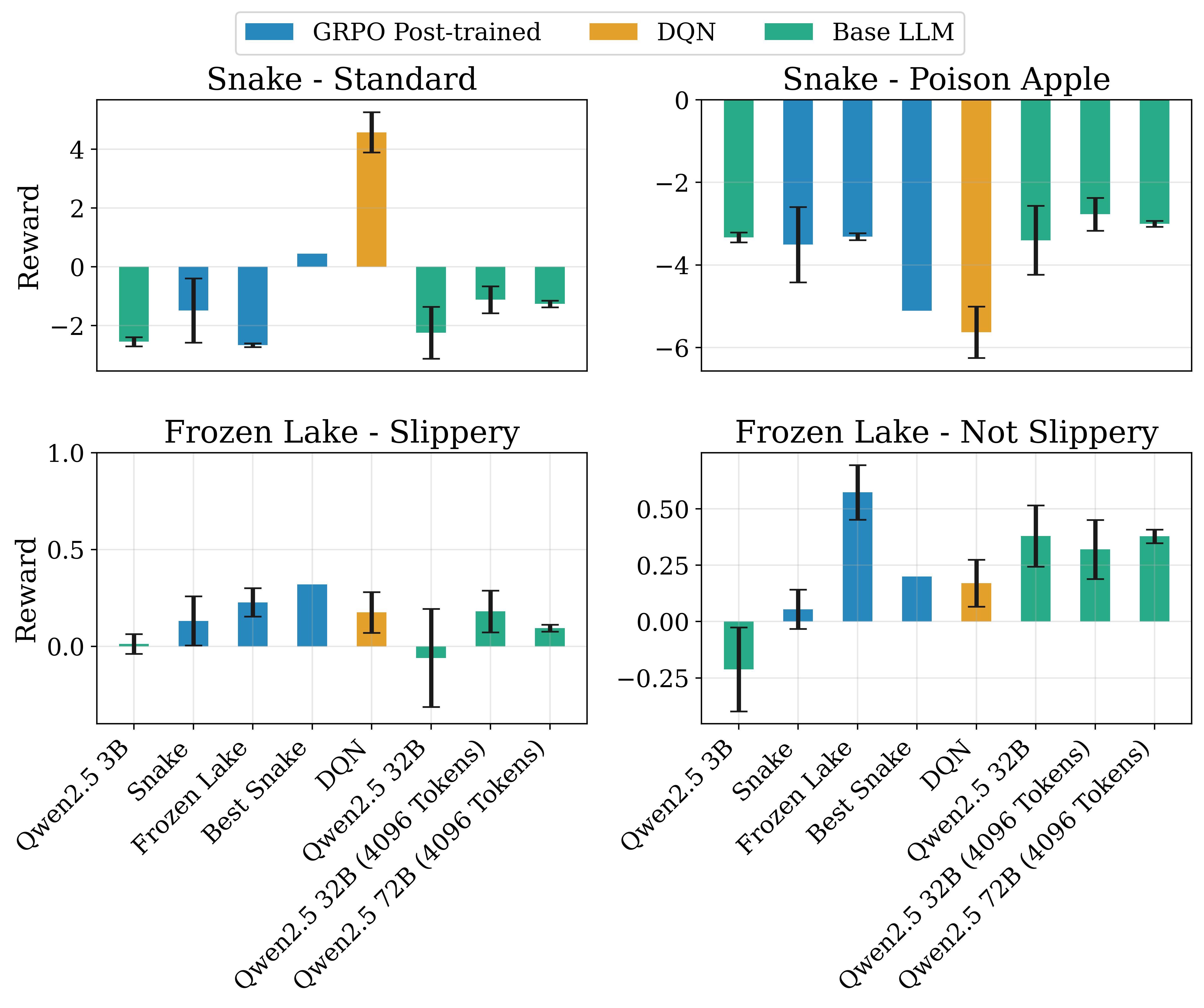
- 在Snake和Frozen Lake上,30亿参数模型通过后训练,在Frozen Lake任务上超越了720亿参数的基线模型。
📝 摘要(中文)
大型语言模型(LLM)在序列决策任务中展现出潜力,但由于依赖于计算成本高昂的大模型,其应用受到限制。为了改进小规模模型,我们提出了多步组相对策略优化(MS-GRPO)算法,用于LLM智能体的后训练。该算法基于文本介导的随机博弈(TSMG)和语言智能体策略(LAP)框架。在信用分配方面,MS-GRPO将整个episode的累积奖励归因于每个episode步骤。此外,我们还提出了一种新颖的绝对优势加权episode采样策略,以提高训练性能。通过在Snake和Frozen Lake上对一个30亿参数的模型进行后训练,实验表明该方法能有效提升决策性能:在Frozen Lake任务上,我们的后训练模型比720亿参数的基线模型性能高出50%。这项工作表明,有针对性的后训练是利用LLM创建序列决策智能体的一种实用且高效的替代方案,无需依赖模型规模。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在序列决策任务中应用受限于模型规模的问题。现有后训练方法主要针对单轮交互,无法有效处理多步决策任务中的信用分配问题,导致小规模语言模型难以在该类任务中取得良好表现。
核心思路:论文的核心思路是通过一种新的后训练算法MS-GRPO,使小规模语言模型能够更好地进行序列决策。MS-GRPO通过将整个episode的累积奖励分配给每个episode步骤,从而解决信用分配问题。此外,引入绝对优势加权episode采样策略,提高训练效率。
技术框架:整体框架包括以下几个主要步骤:1) 使用语言模型作为智能体与环境进行交互,生成一系列episode;2) 使用MS-GRPO算法对语言模型进行后训练,该算法基于文本介导的随机博弈(TSMG)和语言智能体策略(LAP)框架;3) 在训练过程中,使用绝对优势加权episode采样策略,选择更有价值的episode进行训练;4) 评估后训练模型的性能。
关键创新:论文的关键创新在于提出了MS-GRPO算法和绝对优势加权episode采样策略。MS-GRPO算法通过将整个episode的累积奖励分配给每个episode步骤,解决了多步决策任务中的信用分配问题。绝对优势加权episode采样策略则通过选择更有价值的episode进行训练,提高了训练效率。与现有方法相比,MS-GRPO更适用于多步序列决策任务,并且能够有效提升小规模语言模型的性能。
关键设计:MS-GRPO算法的关键设计包括:1) 奖励分配机制:将整个episode的累积奖励分配给每个episode步骤;2) 策略优化:使用策略梯度方法优化语言模型;3) 绝对优势加权episode采样:根据episode的绝对优势(即episode的奖励与平均奖励的差值)对episode进行加权采样。具体的损失函数和网络结构细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过MS-GRPO算法后训练的30亿参数模型在Frozen Lake任务上超越了720亿参数的基线模型,性能提升了50%。这表明,有针对性的后训练是提升小规模语言模型在序列决策任务中性能的有效方法,可以作为依赖模型规模的替代方案。
🎯 应用场景
该研究成果可应用于各种需要序列决策的场景,例如游戏AI、机器人控制、对话系统等。通过后训练小规模语言模型,可以降低计算成本,使其能够在资源受限的环境中部署。该方法有助于推动语言模型在实际应用中的普及,并为开发更智能的自主系统提供新的思路。
📄 摘要(原文)
Large Language Models (LLMs) show potential as sequential decision-making agents, but their application is often limited due to a reliance on large, computationally expensive models. This creates a need to improve smaller models, yet existing post-training methods are designed for single-turn interactions and cannot handle credit assignment in multi-step agentic tasks. To address this, we introduce Multi-Step Group-Relative Policy Optimization (MS-GRPO), a new algorithm for post-training LLM agents, grounded in formal Text-Mediated Stochastic Game (TSMG) and Language-Agent Policy (LAP) frameworks. For credit assignment, MS-GRPO attributes the entire cumulative episode reward to each individual episode step. We supplement this algorithm with a novel absolute-advantage-weighted episode sampling strategy that we show improves training performance. We evaluate our approach by post-training a 3-billion parameter model on Snake and Frozen Lake. Our experiments demonstrate that the method is effective in improving decision-making performance: our post-trained 3B parameter model outperforms a 72B parameter baseline by 50% on the Frozen Lake task. This work demonstrates that targeted post-training is a practical and efficient alternative to relying on model scale for creating sequential decision-making agents using LLMs.