When Language Overrules: Revealing Text Dominance in Multimodal Large Language Models
作者: Huyu Wu, Meng Tang, Xinhan Zheng, Haiyun Jiang
分类: cs.CL, cs.AI
发布日期: 2025-08-14
💡 一句话要点
系统性揭示多模态大语言模型中文本主导现象,并提出token压缩方法有效缓解该问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 文本主导 模态融合 注意力机制 Token压缩
📋 核心要点
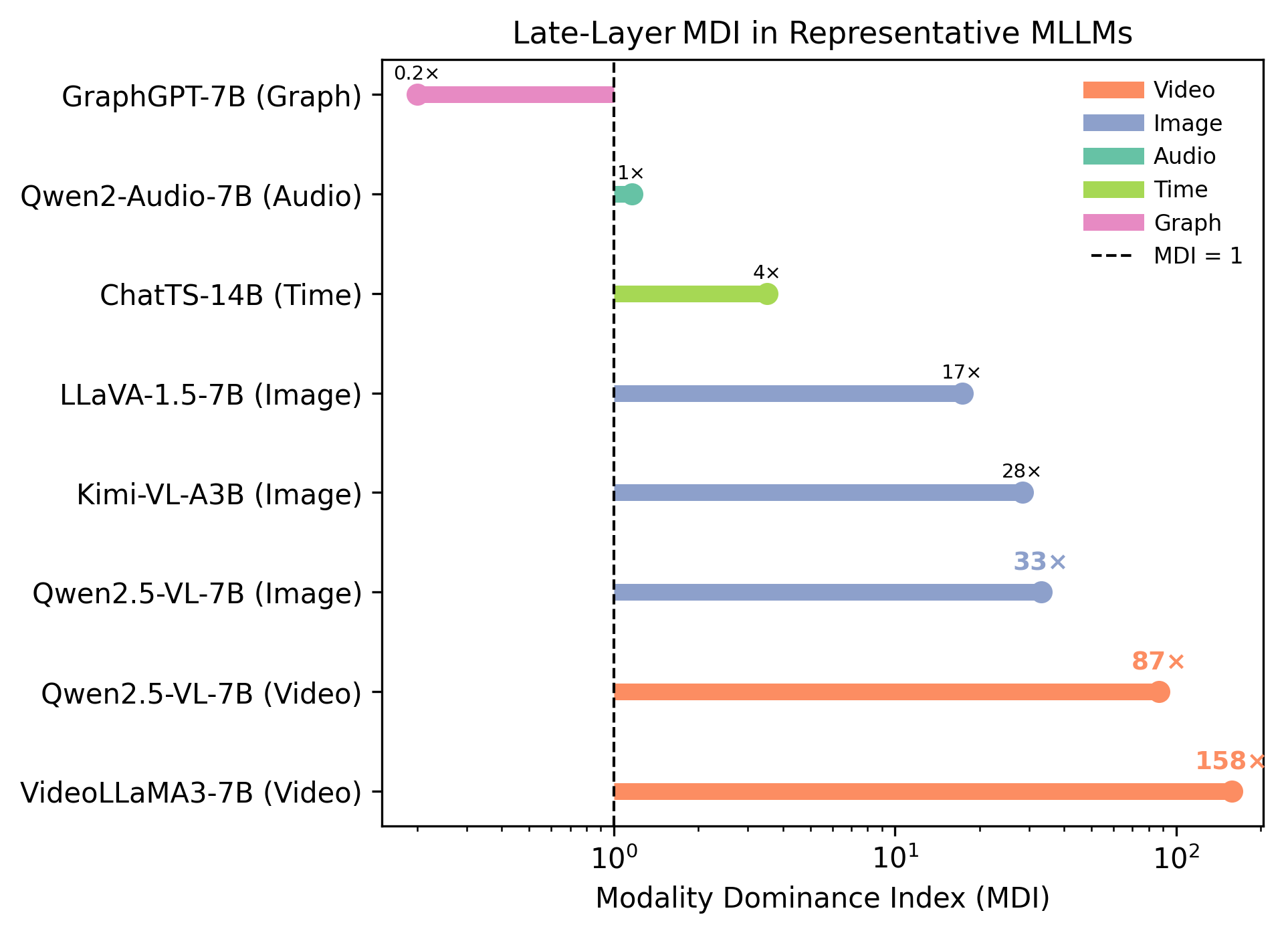
- 多模态大语言模型存在文本主导问题,即过度依赖文本信息而忽略其他模态,限制了模型性能。
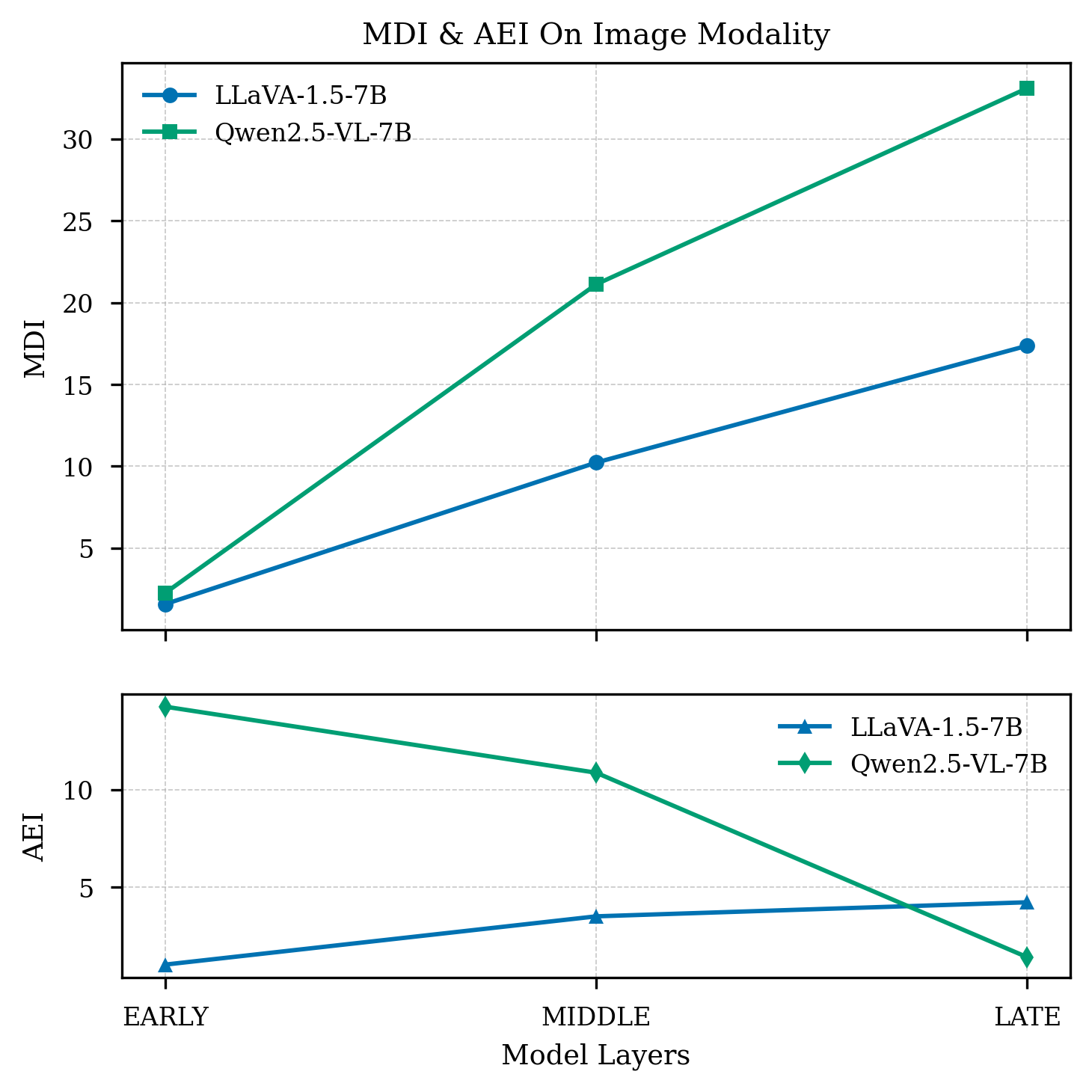
- 论文提出模态主导指数(MDI)和注意力效率指数(AEI)来量化文本主导程度,并分析其根本原因。
- 通过token压缩方法,有效减少了非文本模态的token冗余,显著降低了文本主导现象,提升了模型性能。
📝 摘要(中文)
多模态大语言模型(MLLMs)在各种多模态任务中表现出卓越的能力。然而,这些模型存在一个核心问题,即文本主导:它们在推理过程中严重依赖文本,而未能充分利用其他模态。虽然之前的工作已经承认了视觉-语言任务中的这种现象,并通常将其归因于数据偏差或模型架构。在本文中,我们首次对包括图像、视频、音频、时间序列和图在内的各种数据模态中的文本主导现象进行了系统性研究。为了衡量这种不平衡,我们提出了两个评估指标:模态主导指数(MDI)和注意力效率指数(AEI)。我们的综合分析表明,文本主导在所有测试的模态中都是显著且普遍存在的。我们的深入分析确定了三个根本原因:非文本模态中严重token冗余导致的注意力稀释、融合架构设计的影响以及隐式偏向文本输入的任务公式。此外,我们提出了一种简单的token压缩方法,可以有效地重新平衡模型注意力。例如,将此方法应用于LLaVA-7B,可将其MDI从10.23大幅降低至平衡的0.86。我们的分析和方法框架为开发更公平和全面的多模态语言模型奠定了基础。
🔬 方法详解
问题定义:多模态大语言模型(MLLMs)在处理多模态数据时,过度依赖文本信息,而对图像、视频、音频等其他模态的信息利用不足。这种文本主导现象导致模型无法充分理解和利用多模态数据的互补信息,限制了其在复杂多模态任务中的性能。现有研究主要关注视觉-语言任务中的文本主导问题,缺乏对其他模态的系统性分析,并且对文本主导的根本原因缺乏深入理解。
核心思路:论文的核心思路是通过量化分析不同模态之间的信息利用程度,揭示文本主导现象的普遍性和根本原因。然后,通过减少非文本模态的token冗余,平衡模型对不同模态的注意力分配,从而缓解文本主导问题。这种方法旨在提高模型对非文本模态信息的利用率,从而提升多模态理解能力。
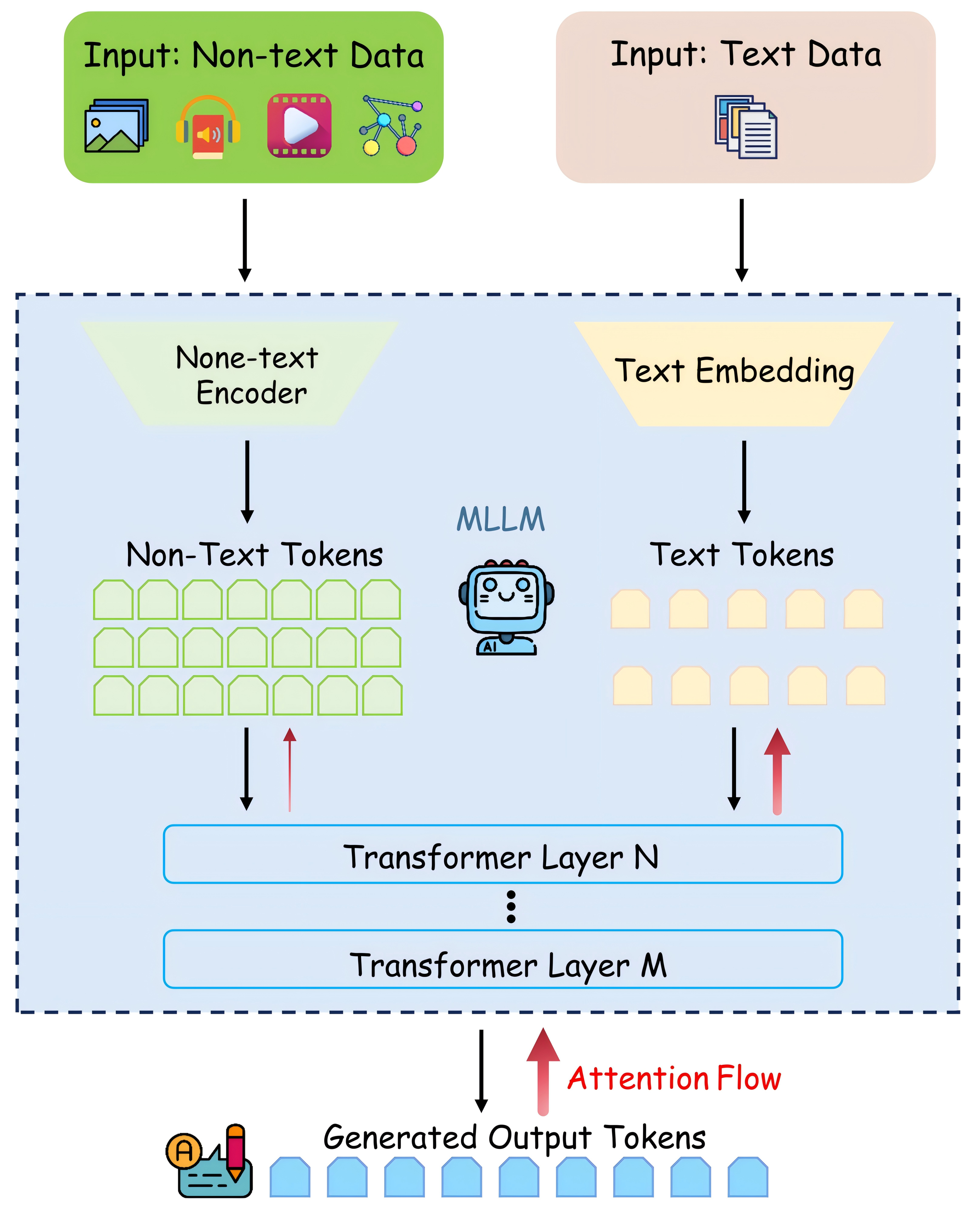
技术框架:该研究的技术框架主要包括三个部分:1) 提出模态主导指数(MDI)和注意力效率指数(AEI)来量化文本主导程度;2) 分析文本主导的根本原因,包括token冗余、融合架构设计和任务公式;3) 提出token压缩方法来减少非文本模态的token冗余,并重新平衡模型注意力。整体流程是先通过MDI和AEI评估文本主导程度,然后分析原因,最后通过token压缩进行缓解。
关键创新:该论文的关键创新在于:1) 首次对多种模态(图像、视频、音频、时间序列、图)的文本主导现象进行了系统性研究,揭示了其普遍性;2) 提出了模态主导指数(MDI)和注意力效率指数(AEI)这两个新的评估指标,用于量化文本主导程度;3) 提出了一种简单的token压缩方法,可以有效地减少非文本模态的token冗余,并重新平衡模型注意力。与现有方法相比,该研究更全面、更深入地分析了文本主导问题,并提出了有效的解决方案。
关键设计:Token压缩方法是关键设计之一。具体来说,对于非文本模态,通过减少token的数量来降低其冗余度。例如,对于图像,可以使用更小的patch size或更少的视觉token。对于音频,可以降低采样率或减少帧数。关键在于找到合适的压缩比例,既能减少冗余,又能保留关键信息。此外,MDI的计算公式为:MDI = (Attention on Text) / (Average Attention on Other Modalities)。AEI的计算涉及衡量每个模态的token数量与其获得的注意力之间的关系。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的token压缩方法可以有效降低文本主导现象。例如,将该方法应用于LLaVA-7B模型,其MDI从10.23大幅降低至0.86,表明模型对不同模态的注意力分配更加平衡。此外,实验还验证了该方法在多个多模态任务上的有效性,例如在图像描述任务中,模型生成的描述更加准确和丰富。
🎯 应用场景
该研究成果可应用于各种多模态任务,例如视频理解、语音识别、图文检索等。通过缓解文本主导问题,可以提升模型对多模态信息的综合理解能力,从而提高任务的准确性和鲁棒性。未来,该研究可以促进更公平、更全面的多模态语言模型的发展,推动人工智能在多模态领域的应用。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across a diverse range of multimodal tasks. However, these models suffer from a core problem known as text dominance: they depend heavily on text for their inference, while underutilizing other modalities. While prior work has acknowledged this phenomenon in vision-language tasks, often attributing it to data biases or model architectures. In this paper, we conduct the first systematic investigation of text dominance across diverse data modalities, including images, videos, audio, time-series, and graphs. To measure this imbalance, we propose two evaluation metrics: the Modality Dominance Index (MDI) and the Attention Efficiency Index (AEI). Our comprehensive analysis reveals that text dominance is both significant and pervasive across all tested modalities. Our in-depth analysis identifies three underlying causes: attention dilution from severe token redundancy in non-textual modalities, the influence of fusion architecture design, and task formulations that implicitly favor textual inputs. Furthermore, we propose a simple token compression method that effectively rebalances model attention. Applying this method to LLaVA-7B, for instance, drastically reduces its MDI from 10.23 to a well-balanced value of 0.86. Our analysis and methodological framework offer a foundation for the development of more equitable and comprehensive multimodal language models.