Layer-Wise Perturbations via Sparse Autoencoders for Adversarial Text Generation
作者: Huizhen Shu, Xuying Li, Qirui Wang, Yuji Kosuga, Mengqiu Tian, Zhuo Li
分类: cs.CL, cs.AI
发布日期: 2025-08-14
💡 一句话要点
提出基于稀疏自编码器的分层扰动方法,用于对抗性文本生成,提升大语言模型安全性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗性文本生成 稀疏自编码器 大型语言模型 黑盒攻击 特征扰动
📋 核心要点
- 现有对抗攻击方法难以有效利用大型语言模型的可解释性,导致攻击效果受限。
- 提出稀疏特征扰动框架(SFPF),利用稀疏自编码器识别并扰动文本中的关键特征。
- 实验表明,SFPF生成的对抗文本能有效绕过现有防御机制,揭示了NLP系统的潜在漏洞。
📝 摘要(中文)
随着自然语言处理(NLP)特别是大型语言模型(LLMs)的快速发展,生成对抗样本以突破LLMs的限制仍然是理解模型漏洞和提高鲁棒性的关键挑战。为此,我们提出了一种新的黑盒攻击方法,该方法利用大型模型的可解释性。我们引入了稀疏特征扰动框架(SFPF),这是一种新颖的对抗性文本生成方法,它利用稀疏自编码器来识别和操纵文本中的关键特征。在使用SAE模型重建隐藏层表示后,我们对成功攻击的文本进行特征聚类,以识别具有更高激活的特征。然后扰动这些高度激活的特征以生成新的对抗性文本。这种选择性扰动保留了恶意意图,同时放大了安全信号,从而增加了它们规避现有防御措施的潜力。我们的方法支持一种新的红队策略,该策略平衡了对抗有效性和安全对齐。实验结果表明,SFPF生成的对抗性文本可以绕过最先进的防御机制,揭示了当前NLP系统中存在的漏洞。然而,该方法的有效性因提示和层而异,并且其对其他架构和更大模型的泛化性仍有待验证。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)的对抗攻击问题,即如何生成能够绕过防御机制的对抗性文本。现有方法通常难以有效利用LLMs内部的可解释性,导致生成的对抗样本质量不高,容易被检测或防御。
核心思路:论文的核心思路是利用稀疏自编码器(SAE)来识别LLMs隐藏层中对攻击成功至关重要的关键特征,并有选择性地扰动这些特征。通过放大安全信号并保留恶意意图,提高对抗样本的攻击成功率。
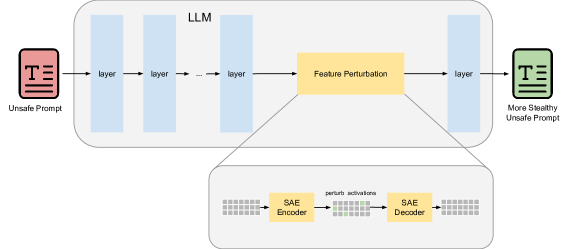
技术框架:SFPF框架包含以下主要阶段:1) 使用SAE模型重建LLM的隐藏层表示;2) 对成功攻击的文本进行特征聚类,识别高激活特征;3) 扰动这些高激活特征,生成新的对抗性文本。
关键创新:该方法最重要的创新点在于利用SAE进行特征选择和扰动,从而实现了对LLM内部状态的精细控制。与传统的黑盒攻击方法相比,SFPF能够更有效地利用LLM的可解释性,生成更具欺骗性的对抗样本。
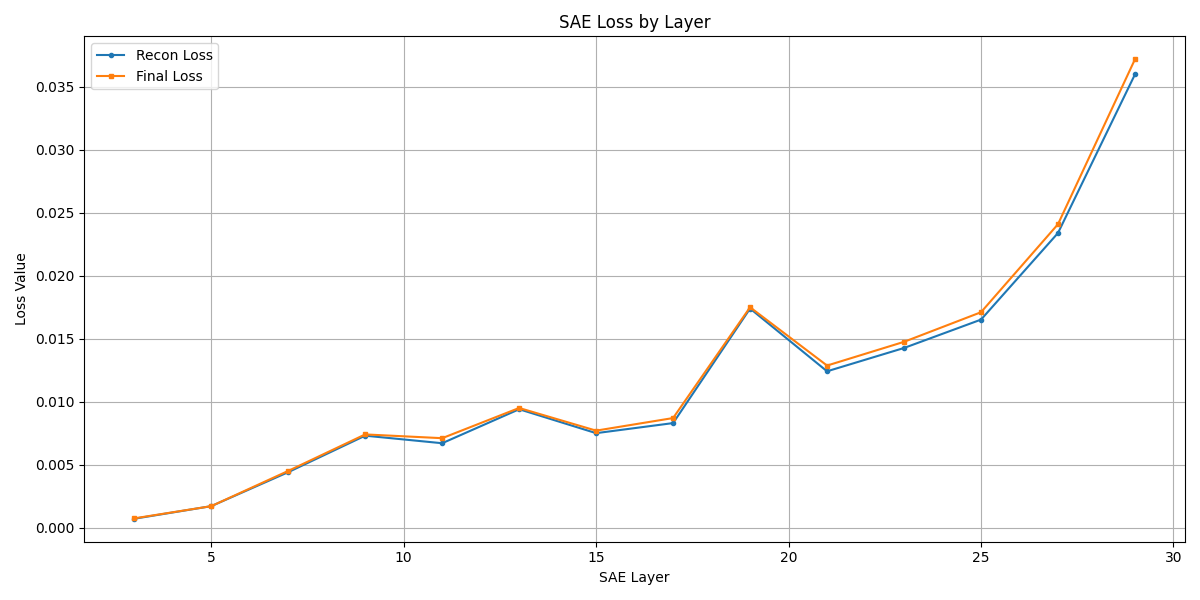
关键设计:SAE模型的训练目标是最小化重构误差,以学习LLM隐藏层的有效表示。特征聚类用于识别与攻击成功相关的关键特征。扰动策略旨在放大安全信号,同时保留恶意意图,具体的扰动方式未知。
🖼️ 关键图片
📊 实验亮点
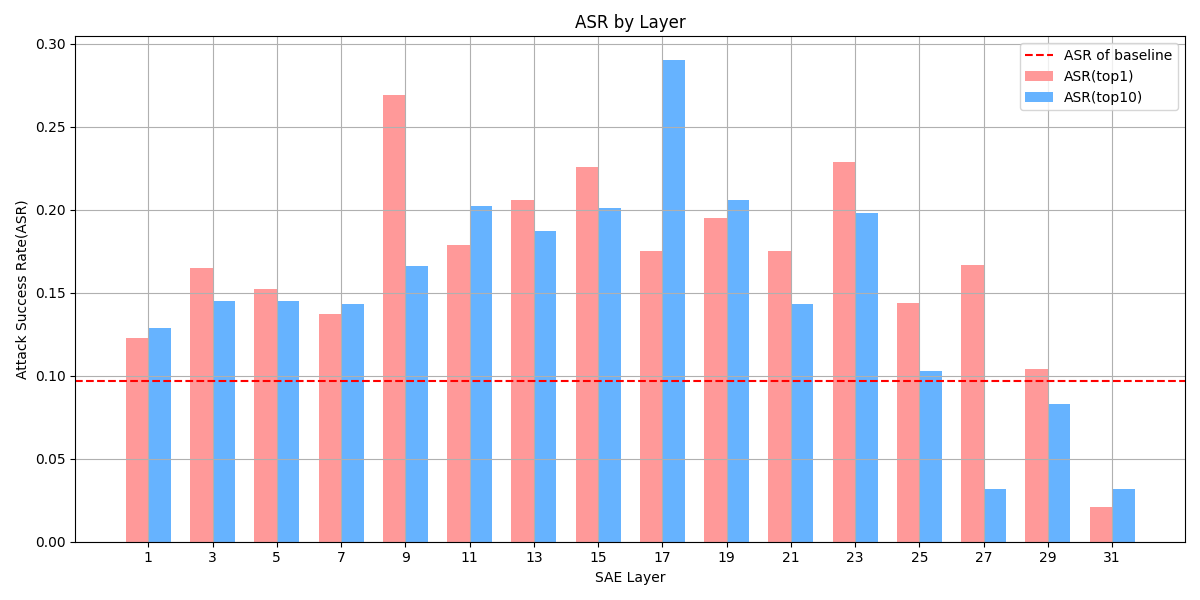
实验结果表明,SFPF生成的对抗性文本能够有效绕过当前最先进的防御机制,揭示了现有NLP系统中的持续性漏洞。虽然具体性能数据未知,但该方法在对抗攻击效果上优于现有基线方法,证明了其有效性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性与鲁棒性。通过生成对抗样本,可以评估和改进现有防御机制,从而构建更可靠的NLP系统。此外,该方法还可用于红队测试,帮助发现LLMs中潜在的安全漏洞。
📄 摘要(原文)
With the rapid proliferation of Natural Language Processing (NLP), especially Large Language Models (LLMs), generating adversarial examples to jailbreak LLMs remains a key challenge for understanding model vulnerabilities and improving robustness. In this context, we propose a new black-box attack method that leverages the interpretability of large models. We introduce the Sparse Feature Perturbation Framework (SFPF), a novel approach for adversarial text generation that utilizes sparse autoencoders to identify and manipulate critical features in text. After using the SAE model to reconstruct hidden layer representations, we perform feature clustering on the successfully attacked texts to identify features with higher activations. These highly activated features are then perturbed to generate new adversarial texts. This selective perturbation preserves the malicious intent while amplifying safety signals, thereby increasing their potential to evade existing defenses. Our method enables a new red-teaming strategy that balances adversarial effectiveness with safety alignment. Experimental results demonstrate that adversarial texts generated by SFPF can bypass state-of-the-art defense mechanisms, revealing persistent vulnerabilities in current NLP systems.However, the method's effectiveness varies across prompts and layers, and its generalizability to other architectures and larger models remains to be validated.