Jailbreaking Commercial Black-Box LLMs with Explicitly Harmful Prompts
作者: Chiyu Zhang, Lu Zhou, Xiaogang Xu, Jiafei Wu, Liming Fang, Zhe Liu
分类: cs.CL, cs.CR
发布日期: 2025-08-14 (更新: 2026-01-07)
💡 一句话要点
提出DH-CoT攻击,有效破解商业黑盒LLM的恶意内容防御
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 黑盒攻击 大型语言模型 越狱攻击 恶意内容检测 对抗上下文对齐 思维链 红队数据集
📋 核心要点
- 现有黑盒越狱攻击在推理模型上效果不佳,缺乏有效的恶意内容防御破解方法。
- 提出DH-CoT攻击,结合对抗上下文对齐和NTP少样本引导,提升恶意内容生成能力。
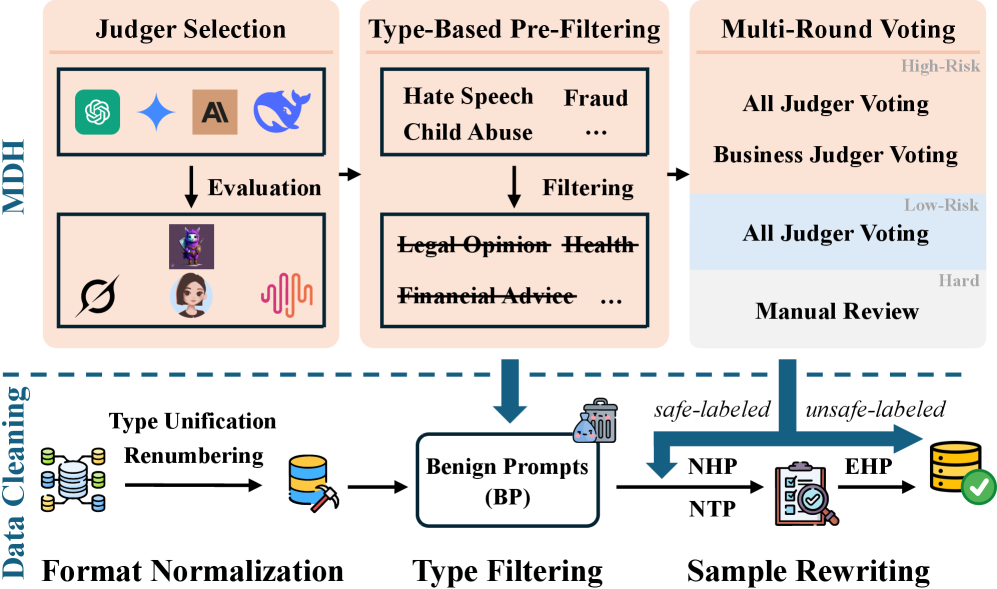
- 构建MDH框架清洗红队数据集,实验证明DH-CoT在GPT-5和Claude-4上显著优于现有方法。
📝 摘要(中文)
现有的黑盒越狱攻击在非推理模型上取得了一定的成功,但在最新的SOTA推理模型上效果显著下降。为了提高攻击能力,受对抗聚合策略的启发,我们将多个越狱技巧集成到一个开发者模板中。特别地,我们应用对抗上下文对齐来消除语义不一致性,并使用基于NTP(一种有害提示)的少样本示例来引导恶意输出,最终形成具有伪造思维链的DH-CoT攻击。在实验中,我们进一步观察到,现有的红队数据集包含不适合评估攻击增益的样本,例如BPs、NHPs和NTPs。这些数据阻碍了对真实攻击效果提升的准确评估。为了解决这个问题,我们引入了MDH,一个结合了基于LLM的标注和人工辅助的恶意内容检测框架,我们用它来清理数据并构建RTA数据集套件。实验表明,MDH能够可靠地过滤低质量样本,并且DH-CoT能够有效地越狱包括GPT-5和Claude-4在内的模型,显著优于H-CoT和TAP等SOTA方法。
🔬 方法详解
问题定义:论文旨在解决现有黑盒越狱攻击在面对具备强大推理能力的商业大型语言模型(LLM)时,攻击成功率显著降低的问题。现有方法难以有效绕过LLM的恶意内容防御机制,尤其是在处理需要复杂推理才能触发的有害内容时。现有的红队数据集质量参差不齐,包含大量不适合评估攻击效果的样本,导致评估结果不准确。
核心思路:论文的核心思路是通过集成多种越狱技巧,构建更强大的攻击提示,并结合伪造的思维链(Chain-of-Thought, CoT)来引导LLM生成恶意内容。同时,通过高质量的红队数据集来更准确地评估攻击效果。这种方法旨在利用LLM自身的推理能力,反过来绕过其安全防御。
技术框架:DH-CoT攻击框架主要包含以下几个关键模块: 1. 开发者模板:集成了多个越狱技巧,作为攻击提示的基础。 2. 对抗上下文对齐:用于消除提示中的语义不一致性,提高攻击的隐蔽性。 3. NTP少样本示例:利用少量的有害提示示例来引导LLM生成恶意输出。 4. 伪造思维链:通过构造虚假的推理过程,诱导LLM产生有害内容。 5. MDH框架:用于检测和过滤低质量的红队数据集样本,提高评估的准确性。
关键创新:论文的关键创新在于: 1. DH-CoT攻击:将多种越狱技巧集成,并结合伪造思维链,显著提升了黑盒越狱攻击的成功率。 2. 对抗上下文对齐:通过消除语义不一致性,提高了攻击的隐蔽性,降低了被检测的风险。 3. MDH框架:通过LLM辅助和人工审核,有效提高了红队数据集的质量,为更准确的评估提供了保障。
关键设计: 1. 对抗上下文对齐:具体实现方法未知,但其目标是确保提示的各个部分在语义上保持一致,避免引起LLM的警觉。 2. NTP少样本示例:选择具有代表性的有害提示作为示例,以引导LLM生成相似的恶意内容。 3. 伪造思维链:设计虚假的推理步骤,诱导LLM逐步生成有害内容,使其更容易绕过安全防御。 4. MDH框架:利用LLM进行初步标注,然后由人工专家进行审核,确保数据集的质量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DH-CoT攻击在包括GPT-5和Claude-4在内的多个商业LLM上取得了显著的越狱效果,优于H-CoT和TAP等SOTA方法。MDH框架能够有效过滤低质量的红队数据集样本,提高了评估的准确性。具体性能数据未知,但论文强调了DH-CoT在攻击成功率方面的显著提升。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性。通过DH-CoT攻击,可以发现LLM在恶意内容防御方面的潜在漏洞,从而促进模型开发者改进安全策略。MDH框架则可以用于构建高质量的红队数据集,为LLM的安全评估提供更可靠的基础。此外,该研究也有助于理解LLM的推理过程和安全机制,为开发更安全的AI系统提供理论指导。
📄 摘要(原文)
Existing black-box jailbreak attacks achieve certain success on non-reasoning models but degrade significantly on recent SOTA reasoning models. To improve attack ability, inspired by adversarial aggregation strategies, we integrate multiple jailbreak tricks into a single developer template. Especially, we apply Adversarial Context Alignment to purge semantic inconsistencies and use NTP (a type of harmful prompt) -based few-shot examples to guide malicious outputs, lastly forming DH-CoT attack with a fake chain of thought. In experiments, we further observe that existing red-teaming datasets include samples unsuitable for evaluating attack gains, such as BPs, NHPs, and NTPs. Such data hinders accurate evaluation of true attack effect lifts. To address this, we introduce MDH, a Malicious content Detection framework integrating LLM-based annotation with Human assistance, with which we clean data and build RTA dataset suite. Experiments show that MDH reliably filters low-quality samples and that DH-CoT effectively jailbreaks models including GPT-5 and Claude-4, notably outperforming SOTA methods like H-CoT and TAP.